RAG:检索增强生成
RAG
RAG: استرجاع الجيل المعزز
أنت تحاول حل قضية معقدة:
- دور المحقق هو جمع الأدلة والأدلة وبعض السجلات التاريخية ذات الصلة بالقضية.
- بعد أن يجمع المحققون هذه المعلومات ، يقوم الصحفيون بتجميع هذه الحقائق في قصة جذابة وتقديم رواية متماسكة.
قضايا LLM
- الوهم: تقديم معلومات كاذبة دون إجابة.
- يستخدم LLM معلومات قديمة ولا يمكنه الوصول إلى المعلومات الحديثة والموثوقة بعد الموعد النهائي لمعرفة.
- بالإضافة إلى ذلك ، لا تشير الإجابات التي تقدمها LLM إلى مصادرها ، مما يعني أنه لا يمكن التحقق من صحة ادعاءاتها من قبل المستخدمين ولا يمكن الوثوق بها تمامًا.وهذا يسلط الضوء على أهمية التحقق والتقييم المستقلين عند استخدام المعلومات التي ينتجها الذكاء الاصطناعي.
您可以将大型语言模型看作是一个过于热情的新员工,他拒绝随时了解时事,但总是会绝对自信地回答每一个问题。
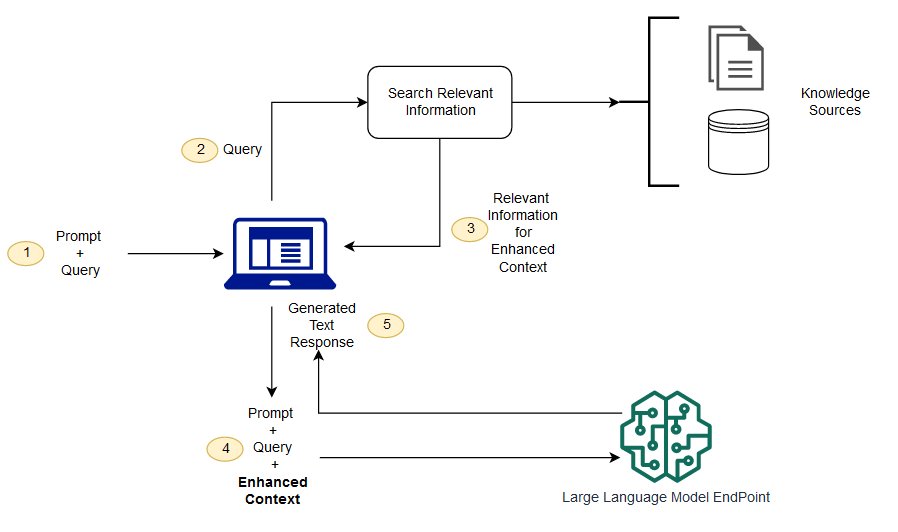
RAG هو طريقة لمعالجة بعض هذه التحديات.فإنه يعيد توجيه LLM واسترجاع المعلومات ذات الصلة من مصادر المعرفة الموثوقة المحددة سلفا.تتمتع المنظمات بالتحكم بشكل أفضل في مخرجات النص المنتجة ، ويحصل المستخدمون على فكرة عن كيفية إنشاء LLM للاستجابة.
مسار LLM
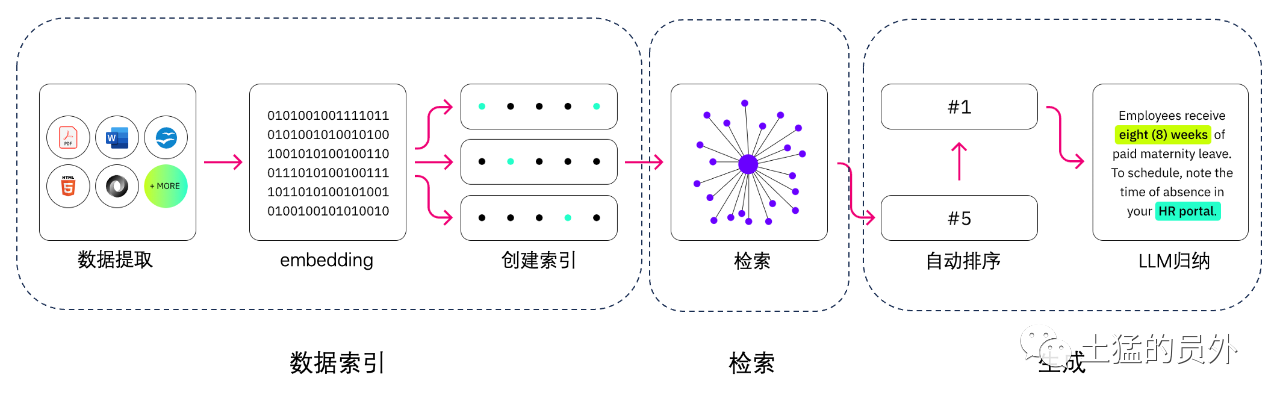
ما هو الفرق بين البحث المحسن والبحث الدلالي؟
يمكن للبحث الدلالي أن يحسن نتائج RAG ، وهو مناسب للمنظمات التي ترغب في إضافة عدد كبير من مصادر المعرفة الخارجية إلى تطبيقات LLM الخاصة بها.تقوم المؤسسات الحديثة بتخزين كمية كبيرة من المعلومات في أنظمة متنوعة مثل الأدلة والأسئلة الشائعة وتقارير البحوث وإرشادات خدمة العملاء ومستودعات وثائق الموارد البشرية.الاسترجاع في السياق صعب من حيث الحجم، وبالتالي يمكن أن يقلل من جودة الناتج المنتج.
تقنيات البحث الدلالي: يمكن مسح قواعد بيانات كبيرة تحتوي على معلومات مختلفة واسترجاع البيانات بشكل أكثر دقة.على سبيل المثال، قد يجيبون على مثل * "كم أنفقت على صيانة الميكانيك في العام الماضي؟" *مثل الأسئلة، عن طريق رسم خرائط الأسئلة إلى المستندات ذات الصلة وإرجاع نص معين بدلا من نتائج البحث.يمكن للمطورين بعد ذلك استخدام هذه الإجابة لتوفير سياق إضافي لLLM.
حلول البحث التقليدية أو الكلمات الرئيسية في RAG تنتج نتائج محدودة للمهام كثيفة المعرفة.يجب على المطورين أيضًا التعامل مع تضمين الكلمات وتقسيم المستندات وغيرها من المشاكل المعقدة عند إعداد البيانات يدويًا.على النقيض من ذلك ، يمكن لتقنيات البحث الدلالي القيام بكل ما تقوم به قاعدة المعرفة من إعداد ، وبالتالي لا يضطر المطورون إلى القيام بذلك.كما أنها تنتج الفقرات ذات الصلة بالمعنى وكلمات العلامات المرتبة حسب الصلة لتحقيق أقصى قدر من جودة حمولة RAG.
المكونات الرئيسية الثلاثة لـ RAG
يتكون نموذج إنتاج تحسينات الاسترجاع من ثلاثة مكونات أساسية:
- Retriever: مسؤول عن استعادة المعلومات ذات الصلة من مصادر المعرفة الخارجية.
- الترتيب (Ranker): تقييم نتائج البحث وتحديد أولوياتها.
- مولد (Generator): يستخدم نتائج البحث والترتيب، جنبا إلى جنب مع مدخلات المستخدم، لإنشاء الإجابة النهائية أو المحتوى.
RAG مخطط الدماغ
هذه الخريطة مفصلة جدا!
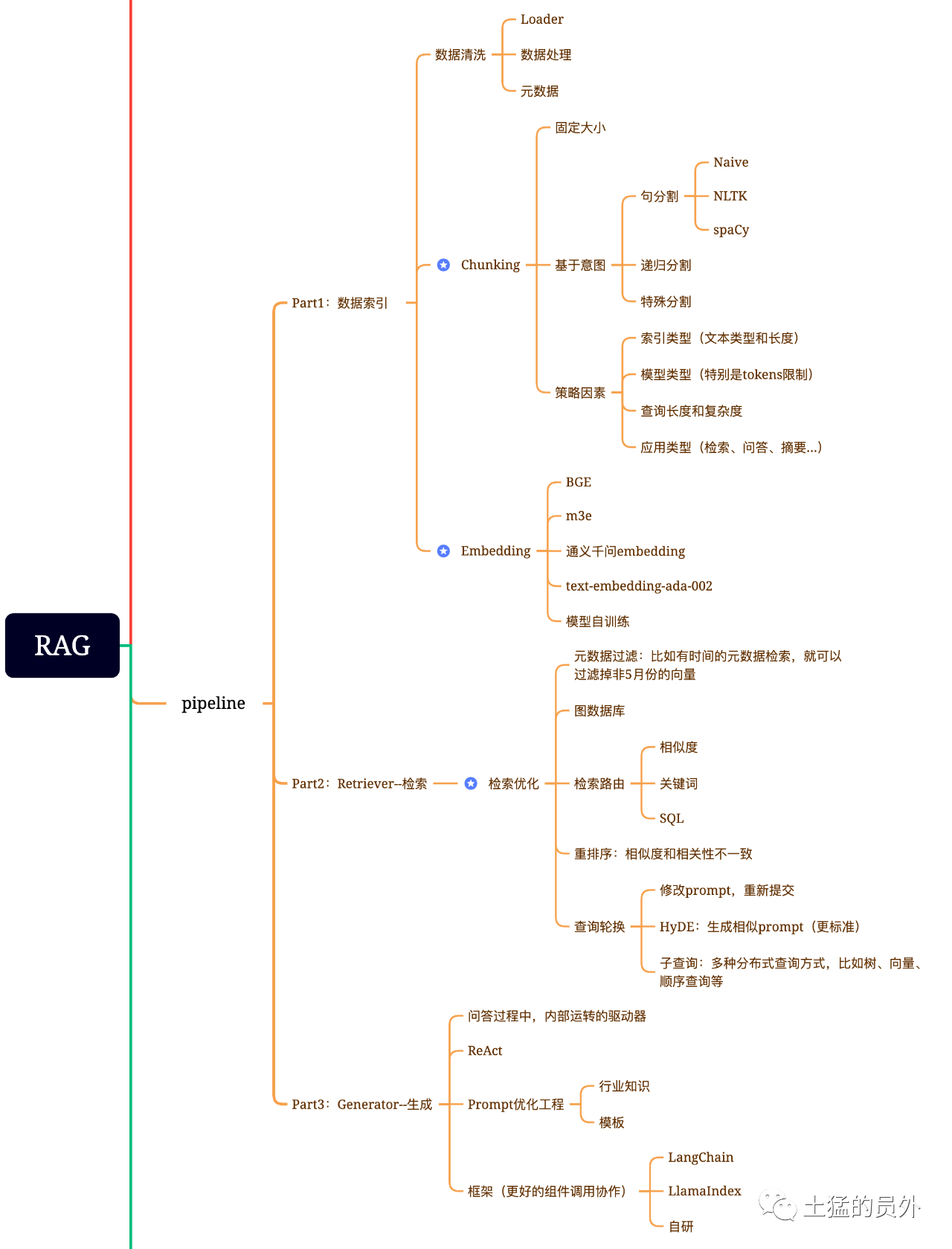
فهرس البيانات
-
** استخراج البيانات **
-
- تنظيف البيانات: بما في ذلك Data Loader ، استخراج PDF ، word ، markdown وقواعد البيانات و API ، إلخ ؛
- معالجة البيانات: بما في ذلك معالجة تنسيق البيانات، وإزالة المحتوى غير المعرف، والضغط والتنسيق، وما إلى ذلك؛
- استخراج البيانات الفوقية: استخراج اسم الملف والوقت والعنوان القسمي والصورة alt وغيرها من المعلومات أمر بالغ الأهمية.
أدوات استخراج البيانات
- UnstructuredIO (استخدمت)
- LlamaParse (استخدمت)
- Google Document AI
- AWS Textract
- pdf2image + بيتسيراكت
البحث
ينقسم تحسين البحث عمومًا إلى خمسة أجزاء من العمل:
-
** تصفية البيانات الفوقية**: عندما نقسم الفهرس إلى أجزاء كثيرة ، تصبح كفاءة الاسترجاع مشكلة.في هذا الوقت ، إذا كان من الممكن تصفية البيانات الفوقية أولاً ، فسوف تزيد الكفاءة والأهمية بشكل كبير.على سبيل المثال ، نسأل "ساعدني في ترتيب جميع العقود التي تم إبرامها في قسم X في مايو من هذا العام ، ما هي العقود التي تتضمن شراء المعدات X؟"في هذا الوقت ، إذا كان هناك بيانات meta ، يمكننا البحث عن البيانات ذات الصلة "XX الإدارة + مايو 2023" ، وقد يصبح حجم البحث واحد من كل عشرة آلاف عالمياً في وقت واحد ؛
-
** استرجاع العلاقات الرسمية**: إذا كان بإمكانك تحويل العديد من الكيانات إلى عقدة وتحويل العلاقات بينها إلى علاقة ، فيمكنك استخدام العلاقات بين المعرفة لإجابة أكثر دقة.وخاصة بالنسبة لبعض المشاكل المتعددة القفزات ، فإن استخدام فهرس بيانات الرسم البياني يمكن أن يجعل البحث أكثر أهمية ؛
-
تقنيات الاسترداد: ما سبق ذكره هو بعض أساليب المعالجة المسبقة، والطريقة الرئيسية للاسترداد أو هذه:
-
- 相似度检索:前面我已经写过那篇文章《大模型应用中大部分人真正需要去关心的核心——Embedding》中有提到六种相似度算法,包括欧氏距离、曼哈顿距离、余弦等,后面我还会再专门写一篇这方面的文章,可以关注我,yeah;
- ** البحث عن الكلمات الرئيسية**: هذه طريقة البحث التقليدية ، ولكنها مهمة في بعض الأحيان.تصفية البيانات الفوقية التي تحدثنا عنها للتو هي نوع من البيانات الفوقية ، وهناك نوع آخر هو أول ملخص لقطعة ، ثم من خلال البحث عن الكلمات الرئيسية للعثور على قطعة محتملة ذات صلة ، وزيادة كفاءة البحث.ويقال إن كلاود.ai يفعل الشيء نفسه؛
- استرداد SQL: هذا أكثر تقليدية، ولكن لبعض تطبيقات المؤسسات المحلية، الاستعلام SQL هو خطوة أساسية، مثل بيانات المبيعات التي ذكرتها سابقا، تحتاج إلى استرداد SQL أولا.
- آخر: لا يزال هناك الكثير من تكنولوجيا الاسترداد ، واستخدامها مرة أخرى ببطء.
-
** إعادة الترتيب (Rerank) **: في كثير من الأحيان نتائج البحث لدينا ليست مثالية، والسبب هو أن عدداً كبيراً من الأجزاء في النظام، ونحن لا نسترجع البعد هو بالضرورة الأمثل، ونتائج البحث قد تكون أقل مثالية في الصلة.في هذا الوقت ، نحتاج إلى بعض الاستراتيجيات لإعادة ترتيب نتائج البحث ، مثل إعادة ترتيب planB ، أو إعادة ضبط بعض العوامل مثل الصلة والمطابقة للحصول على ترتيب أكثر تتناسب مع سيناريو أعمالنا.ونظراً لأن هذه الخطوة ستُرسل النتائج إلى LLM للتجهيز النهائي، فإن النتائج في هذا الجزء مهمة.سيكون هناك أيضًا حكم داخلي لمراجعة الصلة وتشغيل إعادة الترتيب.
-
** تناوب الاستعلام**: هذه طريقة للاسترجاع الاستعلامي ، وعادة ما يكون هناك عدة طرق:
-
** الاستعلامات الفرعية: ** يمكن استخدام استراتيجيات الاستعلام المختلفة في سيناريوهات مختلفة، مثل الاستعلامات التي توفرها إطار مثل LlamaIndex، باستخدام الاستعلامات شجرة (من عقدة الأوراق، الاستعلام خطوة بخطوة، دمج)، باستخدام الاستعلامات المتجهة، أو أكثر ترتيب الاستعلامات البدائية قطع، إلخ **؛
-
HyDE: ** هذه طريقة لنسخ الواجبات لإنشاء قالب prompt مماثل أو أكثر قياسية
-
إعادة الترتيب
تضحي معظم قواعد بيانات المتجهات بدرجة من الدقة من أجل كفاءة الحساب.هذا يجعل نتائج البحث عشوائية إلى حد ما ، حيث أن Top K الأصلي المرجع ليس بالضرورة الأكثر صلة.
使用BAAI/bge-reranker-base、BAAI/bge-reranker-large等开源模型来完成Re-Rank操作。
هناك أيضًا bce-reranker-base من NetEase ، التي تدعم الصينية والإنجليزية واليابانية والكورية.
الاستدعاء/البحث المختلط
الاستفسار الثنائي:
- البحث الدلالي (Vector Search)/استدعاء قاعدة بيانات المتجهات
- البحث عن الكلمات الرئيسية/Keyword Search
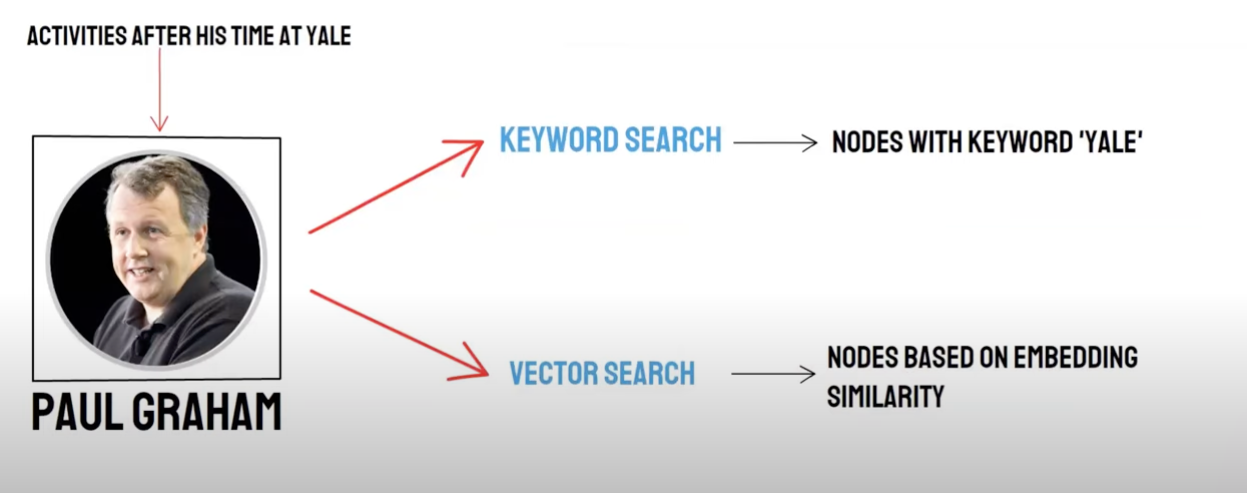
واستدعاء قاعدة البيانات المتجهة واستدعاء استعادة الكلمات الرئيسية لها مزايا وأوجه نقص خاصة بها، وبالتالي فإن تجميع نتائج الاستدعاء يمكن أن تحسن من دقة وكفاءة الاسترجاع العامة.تقوم خوارزمية Reciprocal Rank Fusion (RRF) بحساب النتيجة الإجمالية المدمجة عن طريق إجراء مجموع مرجح لمرتبة كل مستند في طرق استدعاء مختلفة.
عندما تختار استخدام استدعاء استرجاع الكلمات الرئيسية، أي Keyword Retrieval اختيار Keyword Ensembled، PAI الافتراضي استخدام خوارزمية RRF لجمع استدعاء متعددة بين نتائج استدعاء قاعدة بيانات المتجهات ونتائج استدعاء الكلمات الرئيسية.
توليد
إطار عمل: Langchain و LlamaIndex
برنامج تكنولوجيا التكنولوجيا
إطار العمل
ما هو text-to-sql ؟
فصل النص:
تقسيم النص: تقسيم المستندات إلى كتل أصغر، وتسهيل المتابعة النص Embedding، وبالتالي تسهيل استرجاع المستندات اللاحقة.
مثالياً: تجمع أجزاء النص ذات الصلة بالمعنى الدلالي معًا في ترتيب.
** منهجية التقسيم**
- وفقا للقاعدة: (أبسط طريقة) تقسيم المستندات حسب الجمل.تقسيم المستندات استنادا إلى علامات الإنهاء الشائعة في الصينية والإنكليزية، مثل قطع الحرف الواحد، والحذف الصينية والإنكليزية، والعلامات الاقتباس المزدوجة، إلخ.
- وفقاً لللغة: 1.أولاً ، قم بتقسيم المستند إلى كتل مستند على مستوى الجملة بناءً على القواعد. 2.ثم استخدم النموذج لدمج كتل الوثيقة على أساس الدلالي ، مما يؤدي في النهاية إلى كتل مستندية قائمة على الدلالي.
** نموذج تقسيم النص القائم على الدلالات**
SEQ_MODEL الذي أطلقه معهد أريدهاما، يعتمد على نافذة BERT+ المنزلقة لتحديد التجزئة الدلالية عن طريق التنبؤ بما إذا كانت الجملة المجزأة تقع ضمن حدود الفقرة.
ناقلات النص: اختيار نموذج Embedding
نموذج BBA (نموذج bge-base-zh) أو اختيار من نموذج MTEB.
تخزين المتجهات
-
Faiss: الاستخدام الشخصي
-
Milvus: درجة الإنتاج
استخدام ناقلات لاسترداد نقاط المعرفة المتطابقة على أساس الأسئلة
top_k
Faiss: البحث الموسع بالقرب من نتائج البحث للحصول على مستندات متقاربة أصغر من chunk_size (عادة 500 كلمة)
Milvus:topk search +bge-base-zh + نموذج تجميع مماثل للفقرة
الأفكار: تحليل الأفكار الاسترداد الموسعة القائمة على استرجاع topk ، وجدنا أنه يتم بشكل أساسي من خلال توسيع قطاعات الدلالي للسماح للنموذج الكبير بالحصول على أكبر قدر ممكن من المعلومات المفيدة عند الإجابة لتحسين تأثير الإجابة.
الأفكار:
- أولاً ، قم بتقسيم المستند إلى كتل مستند على مستوى الجملة بناءً على القواعد.
- ثم استخدم النموذج لدمج كتل الوثيقة على أساس الدلالي ، مما يؤدي في النهاية إلى كتل مستندية قائمة على الدلالي.
- مرة أخرى في الترتيب باستخدام نموذج embedding النص للوثيقة، وفقا للتشابه الدلالي تجميع مرة أخرى، ما يعادل مرتين باستخدام طرق مختلفة لمستوى الجملة الأصلية المستند تجميع مرتين.
إنشاء Prompt
你现在是一个智能助手了,现在需要你根据已知内容回答问题
已知内容如下:
"{context}"
通过对已知内容进行总结并且列举的方式来回答问题:"{question}",在答案中不能出现问题内容,并且不允许编造内容,并且使用简体中文回答。
如果该问题和已知内容不相关,请回答 "根据已知信息无法回答该问题" 或 "没有提供足够的相关信息"。
توليد الإجابة: اختيار LLM
برنامج اختبار
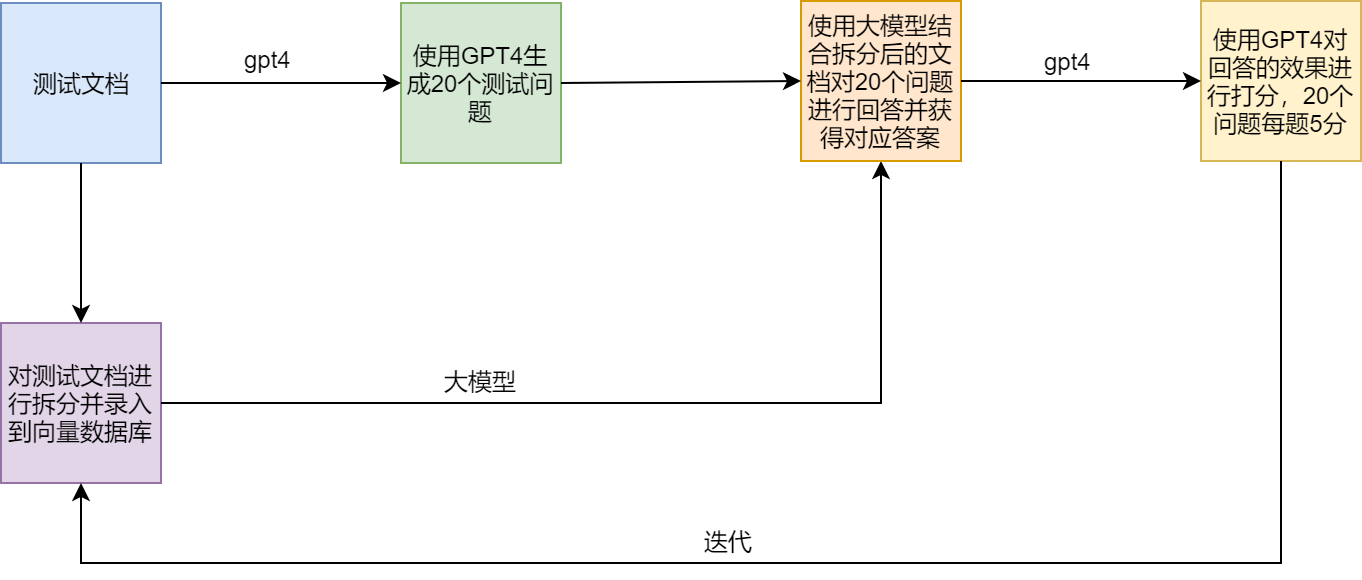
نقاط الألم والحلول في RAG

أمثلة
LamaIndex官方提供了一个范例(SEC Insights),用来展示高级查询技术