LlamaIndex
Python和Typescript版本
Python版本的文档更完善,ts比较差?
入门
创建环境
conda create --name llamaindex python=3.9.19
conda activate llamaindex
在VSCode中设置Conda环境
Python: Select Interpreter
安装库
pip install llama-index pypdf sentence_transformers
配置OpenAI
vim ~/.bashrc
添加环境变量
export OPENAI_API_KEY="sk-xxxx"
验证
echo $OPENAI_API_KEY
可达性
在命令行配置: goproxy
Quick Start
import os.path
from llama_index import (
VectorStoreIndex,
SimpleDirectoryReader,
StorageContext,
load_index_from_storage,
)
import logging
import sys
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG)
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
# check if storage already exists
PERSIST_DIR = "./storage"
if not os.path.exists(PERSIST_DIR):
# load the documents and create the index
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
# store it for later
index.storage_context.persist(persist_dir=PERSIST_DIR)
else:
# load the existing index
storage_context = StorageContext.from_defaults(persist_dir=PERSIST_DIR)
index = load_index_from_storage(storage_context)
# either way we can now query the index
query_engine = index.as_query_engine()
response = query_engine.query("What did the author do growing up?")
print(response)
使用的completions方法
/chat/completions
查询的参数
{
"messages": [
{
"role": "system",
"content": "You are an expert Q&A system that is trusted around the world.\nAlways answer the query using the provided context information, and not prior knowledge.\nSome rules to follow:\n1. Never directly reference the given context in your answer.\n2. Avoid statements like \"Based on the context, ...\" or \"The context information ...\" or anything along those lines."
},
{
"role": "user",
"content": "xxx"
}
],
"model": "gpt-3.5-turbo",
"stream": false,
"temperature": 0.1
}
System Prompt
You are an expert Q&A system that is trusted around the world.
Always answer the query using the provided context information, and not prior knowledge.
Some rules to follow:
1. Never directly reference the given context in your answer.
2. Avoid statements like "Based on the context, ..." or "The context information ..." or anything along those lines.
您是一个受到全世界信赖的专家问答系统。 在回答问题时,始终使用所提供的背景信息,而不是先前的知识。 需要遵循的一些规则:
- 永远不要在答案中直接引用给定的背景信息。
- 避免使用“根据背景信息,…”或“背景信息表明,…”或任何类似的表述。
User Prompt
Context information is below.
---------------------
file_path: data/paul_graham_essay.txt
xxx
---------------------
Given the context information and not prior knowledge, answer the query.
Query: What did the author do growing up?
Answer:
应用场景
| 应用场 | 说明 |
|---|---|
| Q&A | 最重要 |
| Chatbots | |
| Agents | 高级 |
| Structured Data Extraction | 有用,整理聊天记录等 |
| Multi-modal |
基本原理
基本流程
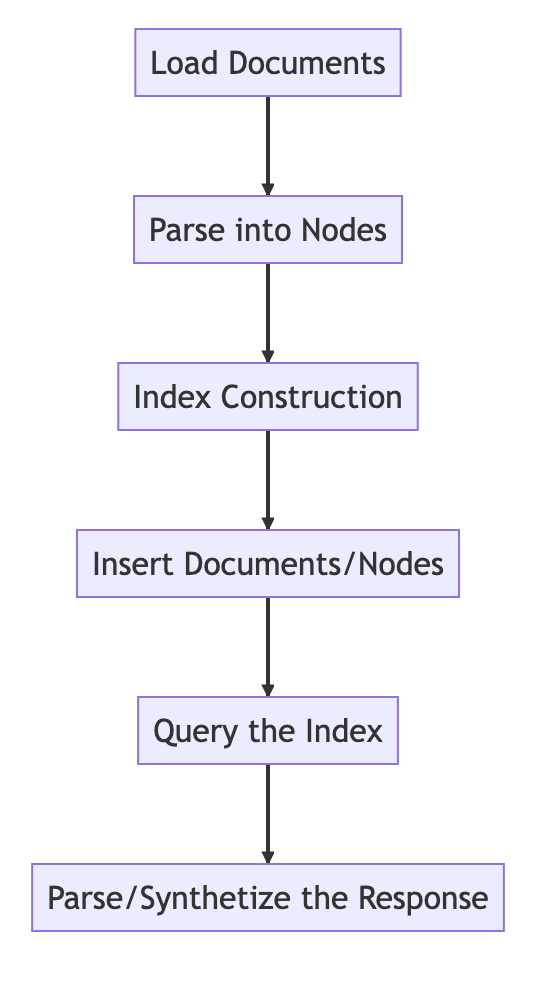
from llama_index import VectorStoreIndex, SimpleDirectoryReader
# Load in data as Document objects
documents = SimpleDirectoryReader('data').load_data()
# 切片,转成Node
# Parse Document objects into Node objects to represent chunks of data
index = VectorStoreIndex.from_documents(documents)
# Index Construction:创建索引
# Build an index over the Documents or Nodes
query_engine = index.as_query_engine()
# The response is a Response object containing the text response and source Nodes
summary = query_engine.query("What is the text about")
print("What is the data about:")
print(summary)
Chunking和Node
源数据--->documents-->Nodes
documents:包含正文和meta信息
Document ID
document其实是Node的子类
很奇怪,一个文件会切成很多个document。
TextNode:使用NodeParser将document切成多个Node
包含Document ID
Node与Node之前有连接关系
- NodeParser接收一个Document对象列表;
- 使用spaCy的句子分割将每个文档的文本分割成句子;
- 每个句子都包装在一个TextNode对象中,该对象表示一个节点;
- TextNode包含句子文本,以及元数据,如文档ID、文档中的位置等;
- 返回TextNode对象的列表。
保存document和index
两种方式
- 保存到本地磁盘
- 存储到向量数据库
保存到本地磁盘
import os.path
from llama_index import (
VectorStoreIndex,
SimpleDirectoryReader,
StorageContext,
load_index_from_storage,
)
import sys
# check if storage already exists
PERSIST_DIR = "./storage"
if not os.path.exists(PERSIST_DIR):
# 保存数据: Load the documents and create the index
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
# store it for later
index.storage_context.persist(persist_dir=PERSIST_DIR)
else:
# 从磁盘加载回数据: load the existing index
storage_context = StorageContext.from_defaults(persist_dir=PERSIST_DIR)
index = load_index_from_storage(storage_context)
query_engine = index.as_query_engine()
response = query_engine.query("What did the author do growing up?")
print(response)
建立索引
为每个Node创建Embedding
在VectorStroreIndex创建索引
- 对于VectorStoreIndex,节点上的文本embedding会存储在FAISS索引中,可以节点上快速进行相似性搜索;
- 索引还存储每个节点上的元数据,如document ID、位置等;
- 节点可以检索某个文档的内容,也可以检索特定文档。
查询索引
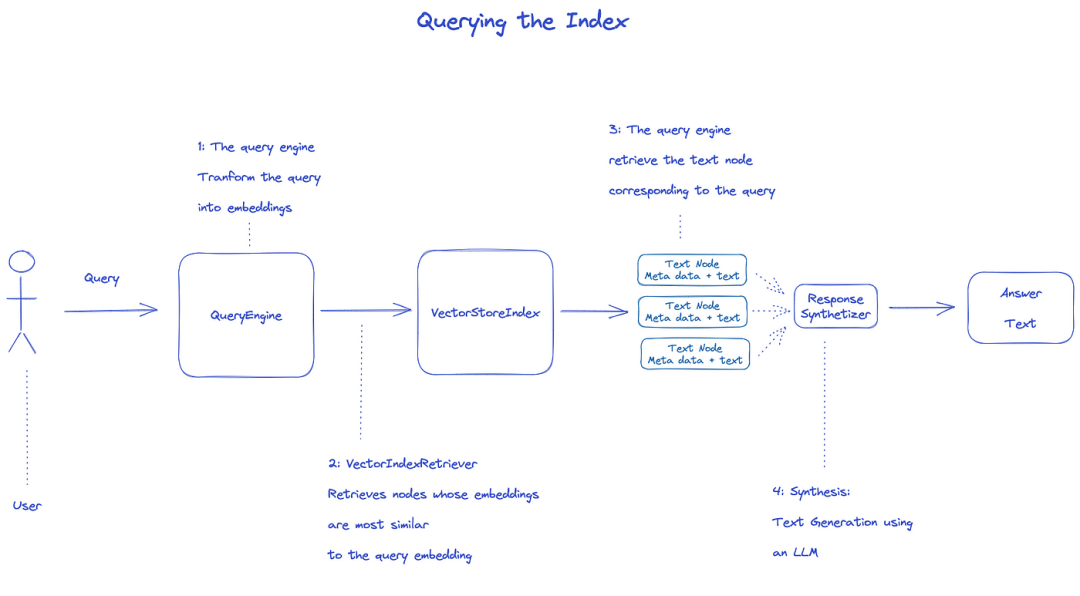
要查询索引,将使用QueryEngine。
- Retriever从查询的索引中获取相关节点。例如,VectorIndexRetriever检索embedding与查询embedding最相似的节点;
- 检索到的节点列表被传递给ResponseSynthesizer以生成最终输出;
- 默认情况下,ResponseSynthesizer按顺序处理每个节点,每个节点都会调用一次LLM API;
- LLM输入查询和节点文本来得到最终的输出;
- 这些每个节点的响应被聚合到最终的输出字符串中。
from llama_index import (
VectorStoreIndex,
get_response_synthesizer,
)
from llama_index.retrievers import VectorIndexRetriever
from llama_index.query_engine import RetrieverQueryEngine
from llama_index.postprocessor import SimilarityPostprocessor
from llama_index import StorageContext, load_index_from_storage
# rebuild storage context
storage_context = StorageContext.from_defaults(persist_dir="storage")
# load index
index = load_index_from_storage(storage_context)
# configure retriever
retriever = VectorIndexRetriever(
index=index,
similarity_top_k=10,
)
# configure response synthesizer
response_synthesizer = get_response_synthesizer()
# assemble query engine
query_engine = RetrieverQueryEngine(
retriever=retriever,
response_synthesizer=response_synthesizer,
node_postprocessors=[SimilarityPostprocessor(similarity_cutoff=0.7)],
)
# query
response = query_engine.query("What did the author do growing up?")
print(response)
官方文档:Understanding
数据处理的三个流程
data cleaning/feature engineering pipelines in the ML world, or ETL pipelines in the traditional data setting.
This ingestion pipeline typically consists of three main stages:
- Load the data
- Transform the data
- Index and store the data
加载数据(Ingestion)
**目标:**将各种类型的数据格式化成document对象。
**输入:**各种类型的数据
输出:document对象
3种方式
- 使用
SimpleDirectoryReader类:最方便 LlamaHub中的Reader:各种已经写好的工具- 直接创建
document
SimpleDirectoryReader类
from llama_index import SimpleDirectoryReader
documents = SimpleDirectoryReader("./data").load_data()
支持Markdown, PDFs, Word documents(.docx), PowerPoint decks, images(.jpg, .png), audio and video
Llamahub
- Notion (
NotionPageReader) - Google Docs (
GoogleDocsReader) - Slack (
SlackReader) - Discord (
DiscordReader) - Apify Actors (
ApifyActor). Can crawl the web, scrape webpages, extract text content, download files including.pdf,.jpg,.png,.docx, etc.这个可以爬虫
直接创建document
from llama_index.schema import Document
doc = Document(text="text")
转换数据(Transformations)
**原因:**方便检索和LLM高效使用
具体操作:
- 将
document分片(chunking) - 提取元数据(extracting metadata)
- Embedding
输入:Node
输出:Node
封装后的API
使用VectorStoreIndex的from_documents()方法
from llama_index import VectorStoreIndex
vector_index = VectorStoreIndex.from_documents(documents)
vector_index.as_query_engine()
如何定制参数
思路:使用ServiceContext来定制
text_splitter = SentenceSplitter(chunk_size=512, chunk_overlap=10)
service_context = ServiceContext.from_defaults(text_splitter=text_splitter)
index = VectorStoreIndex.from_documents(
documents, service_context=service_context
)
原子API
标准使用模式
from llama_index import Document
from llama_index.embeddings import OpenAIEmbedding
from llama_index.text_splitter import SentenceSplitter
from llama_index.extractors import TitleExtractor
from llama_index.ingestion import IngestionPipeline, IngestionCache
# 加载数据源
documents = SimpleDirectoryReader("./data").load_data()
# 创建转换数据的工作流
# create the pipeline with transformations
pipeline = IngestionPipeline(
transformations=[
SentenceSplitter(chunk_size=25, chunk_overlap=0), # 分片
TitleExtractor(), # 提取Meta信息
OpenAIEmbedding(), # Embedding
]
)
# 执行流程,生成节点
# run the pipeline
nodes = pipeline.run(documents=documents)
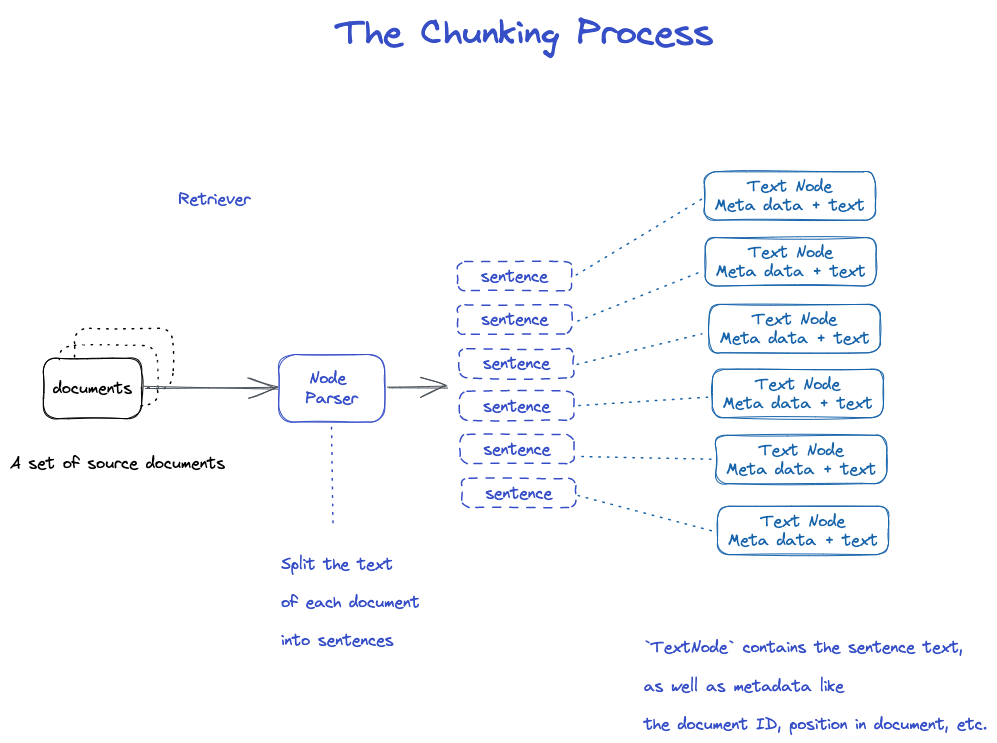
分片
有很多策略,具体见Node Parser模块。
添加元数据
可以自定义document和Node,添加元数据。
直接创建Node对象
from llama_index.schema import TextNode
node1 = TextNode(text="<text_chunk>", id_="<node_id>")
node2 = TextNode(text="<text_chunk>", id_="<node_id>")
index = VectorStoreIndex([node1, node2])
索引
索引分类
- Vector Stores
- Document Stores
- Index Stores
- Key-Value Stores
- Using Graph Stores
- [Chat Stores](
常见的索引
- Summary Index (formerly List Index)
- Vector Store Index(最常见)
- Tree Index
- Keyword Table Index
Summary Index (formerly List Index)

Vector Store Index

Tree Index

Keyword Table Index

Meta
添加meta
document.metadata['lang'] = lang
过滤
from llama_index.core.vector_stores import (
ExactMatchFilter,
MetadataFilters,
MetadataFilter,
)
filters = MetadataFilters(
filters=[
MetadataFilter(key="post_year", value="2017"),
],
)
# You pass filter as an argument. You can have any type of filter
# we saw above and then pass it to query engine.
query_engine = index.as_query_engine(service_context=service_context,
similarity_top_k=5,
filters = filters,
response_mode='tree_summarize')
response = query_engine.query("Marathon Running")
print(response)
Response Modes
- refine:逐一跟context一直生成答案;先使用text_qa_template模板,再使用refine_template模板。
- compact:默认。与refine类似,但是,会将context塞满一次请求。
- tree_summarize
- simple_summarize
源码
Document
a
Documentis a subclass of aNode)
包含:
-
text
-
metadata -
relationships:与其它 Documents/Nodes的关系
原子使用流程
from llama_index import Document, VectorStoreIndex
# 数据源
text_list = [text1, text2, ...]
# 手动创建documents
documents = [Document(text=t) for t in text_list]
# 建立索引: 传入document,在VectorStoreIndex再转换:分片转成Node,Embedding等
index = VectorStoreIndex.from_documents(documents)
创建document的几种方法
手动创建
from llama_index import Document
text_list = [text1, text2, ...]
documents = [Document(text=t) for t in text_list]
使用data loader(connector)
它们都有一个方法load_data()
from llama_index import SimpleDirectoryReader
documents = SimpleDirectoryReader("./data").load_data()
自动生成的范例数据
document = Document.example()
自定义Meta
from llama_index import Document
from llama_index.schema import MetadataMode
document = Document(
text="This is a super-customized document",
metadata={
"file_name": "super_secret_document.txt",
"category": "finance",
"author": "LlamaIndex",
},
excluded_llm_metadata_keys=["file_name"],
metadata_seperator="::",
metadata_template="{key}=>{value}",
text_template="Metadata: {metadata_str}\n-----\nContent: {content}",
)
print(
"The LLM sees this: \n",
document.get_content(metadata_mode=MetadataMode.LLM),
)
print()
print(
"The Embedding model sees this: \n",
document.get_content(metadata_mode=MetadataMode.EMBED),
)
输出
The LLM sees this:
Metadata: category=>finance::author=>LlamaIndex
-----
Content: This is a super-customized document
The Embedding model sees this:
Metadata: file_name=>super_secret_document.txt::category=>finance::author=>LlamaIndex
-----
Content: This is a super-customized document
Metadata Extraction Usage Pattern(不明白)
Node
本质:document的分片
如何得到:
- 使用NodeParser类将document转成Node
- 手动创建
与document一样,有:
-
text
-
metadata -
relationships:与其它 Documents/Nodes的关系
从document转换成Node时,会继承metadata等信息。
Node是LlamaIndex中的一等公民。
原子使用流程
from llama_index.node_parser import SentenceSplitter
# load documents
...
# 手动转换:切片,转成Node
# parse nodes
parser = SentenceSplitter()
nodes = parser.get_nodes_from_documents(documents)
# build index
index = VectorStoreIndex(nodes)
设置关系
from llama_index.schema import TextNode, NodeRelationship, RelatedNodeInfo
node1 = TextNode(text="text_chunk1", id_="node_id1")
node2 = TextNode(text="text_chunk2", id_="node_id2")
node3 = TextNode(text="text_chunk3", id_="node_id3")
# set relationships
node1.relationships[NodeRelationship.NEXT] = RelatedNodeInfo(
node_id=node2.node_id
)
node2.relationships[NodeRelationship.PREVIOUS] = RelatedNodeInfo(
node_id=node1.node_id
)
node2.relationships[NodeRelationship.PARENT] = RelatedNodeInfo(
node_id=node3.node_id, metadata={"key": "val"}
)
print(node2)
NodeParser
用途:将数据源转成Node对象
具体:将一组document对象分片成多个Node对象
常见的具体实现
NodeParser是一个抽象类,具体实现有:
按文件类型
- SimpleFileNodeParser
- HTMLNodeParser
- JSONNodeParser
- MarkdownNodeParser
文本分割
- CodeSplitter
- LangchainNodeParser
- SentenceSplitter
- SentenceWindowNodeParser(不明白)
- SemanticSplitterNodeParser(不明白,感觉比较高级)
- TokenTextSplitter
父子关系
- HierarchicalNodeParser:在AutoMergingRetriever中使用
典型用法
原子使用
from llama_index import Document
from llama_index.node_parser import SentenceSplitter
# 创建NodeParser
node_parser = SentenceSplitter(chunk_size=1024, chunk_overlap=20)
# 调用 get_nodes_from_documents() 方法
# show_progress 可以显示进度
nodes = node_parser.get_nodes_from_documents(
[Document.example(), Document.example()], show_progress=True
)
print(len(nodes))
print()
print(nodes[0])
输出
2
Node ID: eaeb6e44-6828-4e36-b7a3-69342de4dc7c
Text: Context LLMs are a phenomenal piece of technology for knowledge
generation and reasoning. They are pre-trained on large amounts of
publicly available data. How do we best augment LLMs with our own
private data? We need a comprehensive toolkit to help perform this
data augmentation for LLMs. Proposed Solution That's where LlamaIndex
comes in. Ll...
Pipline中的Transformations
from llama_index import Document
from llama_index.node_parser import SentenceSplitter
from llama_index.ingestion import IngestionPipeline
from llama_index.node_parser import TokenTextSplitter
documents = [Document.example(), Document.example()]
# 创建NodeParser
node_parser = SentenceSplitter(chunk_size=1024, chunk_overlap=20)
# 将NodeParser放到Pipeline中的transformations列表
pipeline = IngestionPipeline(transformations=[node_parser])
nodes = pipeline.run(documents=documents)
print(len(nodes))
print()
print(nodes[0])
使用ServiceContext
from llama_index import Document, ServiceContext, VectorStoreIndex
from llama_index.node_parser import SentenceSplitter
from llama_index.ingestion import IngestionPipeline
from llama_index.node_parser import TokenTextSplitter
documents = [Document.example(), Document.example()]
node_parser = SentenceSplitter(chunk_size=1024, chunk_overlap=20)
service_context = ServiceContext.from_defaults(text_splitter=node_parser)
index = VectorStoreIndex.from_documents(
documents, service_context=service_context, show_progress=True
)
Transformations
输入:一组Node
输出:一组Node
有两个公共的方法:
__call__():同步acall():异步
NodeParser和MetadataExtractor属于Transformations
使用模式
from llama_index.text_splitter import SentenceSplitter
from llama_index.extractors import TitleExtractor
node_parser = SentenceSplitter(chunk_size=512)
extractor = TitleExtractor()
# use transforms directly
nodes = node_parser(documents)
# or use a transformation in async
nodes = await extractor.acall(nodes)
与ServiceContext组合使用
from llama_index import ServiceContext, VectorStoreIndex
from llama_index.extractors import (
TitleExtractor,
QuestionsAnsweredExtractor,
)
from llama_index.ingestion import IngestionPipeline
from llama_index.text_splitter import TokenTextSplitter
transformations = [
TokenTextSplitter(chunk_size=512, chunk_overlap=128),
TitleExtractor(nodes=5),
QuestionsAnsweredExtractor(questions=3),
]
# 创建ServiceContext,传入Transfrmation
service_context = ServiceContext.from_defaults(
transformations=[text_splitter, title_extractor, qa_extractor]
)
# 传入VectorStoreIndex的from_documents()或insert()方法
index = VectorStoreIndex.from_documents(
documents, service_context=service_context
)
ServiceContext
a bundle of services and configurations used across a LlamaIndex pipeline.
可以配置
from llama_index import (
ServiceContext,
OpenAIEmbedding,
PromptHelper,
)
from llama_index.llms import OpenAI
from llama_index.text_splitter import SentenceSplitter
# 设置LLM
llm = OpenAI(model="text-davinci-003", temperature=0, max_tokens=256)
# 设置Embedding模型
embed_model = OpenAIEmbedding()
# 设置Chunk的大小
text_splitter = SentenceSplitter(chunk_size=1024, chunk_overlap=20)
prompt_helper = PromptHelper(
context_window=4096,
num_output=256,
chunk_overlap_ratio=0.1,
chunk_size_limit=None,
)
service_context = ServiceContext.from_defaults(
llm=llm, # 设置LLM
embed_model=embed_model, # 设置Embedding模型
text_splitter=text_splitter, # 设置Chunk的大小
prompt_helper=prompt_helper,
)
构造函数传参(更方便)
Kwargs for node parser:
chunk_size- `chunk_overlap
Kwargs for prompt helper:
context_window:num_output
例如
service_context = ServiceContext.from_defaults(chunk_size=1000)
全局配置
from llama_index import set_global_service_context
set_global_service_context(service_context)
本地配置
query_engine = index.as_query_engine(service_context=service_context)
StorageContext
defines the storage backend for where the documents, embeddings, and indexes are stored.
API Reference
store = PGVectorStore(
connection_string=conn_string,
async_connection_string=async_conn_string,
schema_name=PGVECTOR_SCHEMA,
table_name=PGVECTOR_TABLE,
)
index = VectorStoreIndex.from_vector_store(store)
VectorStoreIndex
构造函数
index = VectorStoreIndex.from_vector_store(store)
Engine有两种:
- Query Engine: BaseQueryEngine
- Chat Engines: BaseChatEngine
创建Engine
index.as_query_engine()# BaseQueryEngine
index.as_query_engine(streaming=True)# 流式 BaseQueryEngine
index.as_chat_engine() # BaseChatEngine; 流式不是在这里控制
查询
# Query
response = await query_engine.aquery(query) # 流式
response = await query_engine.aquery(query)
# Chat
response = await chat_engine.astream_chat(last_message_content, messages) # 流式在这里控制
response = await chat_engine.achat(last_message_content, messages)
BaseQueryEngine
query
aquery
BaseChatEngine
- chat
- stream_chat
- achat
- astream_chat
支持流式:stream
支持异步:a开头
响应的类型
# Query
RESPONSE_TYPE = Union[
Response,
StreamingResponse, AsyncStreamingResponse, #流式
PydanticResponse
]
# Chat
StreamingAgentChatResponse #流式
AGENT_CHAT_RESPONSE_TYPE = Union[AgentChatResponse, StreamingAgentChatResponse] #非流式
如何处理流式的响应
使用Python的标准接口:
- StreamingResponse()
- AsyncStreamingResponse
- StreamingResponse
- Query
@r.post("")
async def chat(
request: Request,
queryData: _QueryData,
query_engine: BaseQueryEngine = Depends(get_query_engine_stream),
):
query = queryData.query
streaming_response = await query_engine.aquery(query)
async def event_generator():
async for token in streaming_response.async_response_gen:
if await request.is_disconnected():
break
yield f"data: {token}\n\n"
return StreamingResponse(event_generator(), media_type="text/event-stream")
- Chat
@r.post("")
async def chat(
request: Request,
data: _ChatData,
chat_engine: BaseChatEngine = Depends(get_chat_engine),
):
last_message_content, messages = await parse_chat_data(data)
response = await chat_engine.astream_chat(last_message_content, messages)
async def event_generator():
async for token in response.async_response_gen():
if await request.is_disconnected():
break
yield token
return StreamingResponse(event_generator(), media_type="text/plain")
StreamingResponse
class AsyncStreamingResponse:
async_response_gen: TokenAsyncGen
class StreamingResponse:
response_gen: TokenGen
Response Modes
监控
教程
Deeplearn教程
Building and Evaluating Advanced RAG Applications:链接 Bilibili
Joint Text to SQL and Semantic Search
This video covers the tools built into LlamaIndex for combining SQL and semantic search into a single unified query interface.