RAG: Search Enhanced Generation
RAG
RAG: Retrieval Augmented Generation
You are trying to solve a complex case:
- The character of a detective is to collect clues, Evidence and some history % remote; records correlation to the dependence of a case.
- After the detective collects this info, the reporter summarizes the facts into a fascinating story and and if you do presents a coherent narrative.
Issues withLLM
- Illusion: Providing false info without answers.
- LLM uses outdated info and it does not have access to up-to-date, reliable info after its Knowledge deadline.
- In addition, the answers provided byLLM do not cite their sources, which means that their claims cannot be verified by users for accuracy or fully trusted. This highlights the importance of Independence verification and evaluation when using info generated by Artificial Intelligence for the hour.
You can think of aGrande Language Model as an overly enthusiastic new employee who refuses to keep abreast of current events, but always answers every question with absolute confidence. Earth.
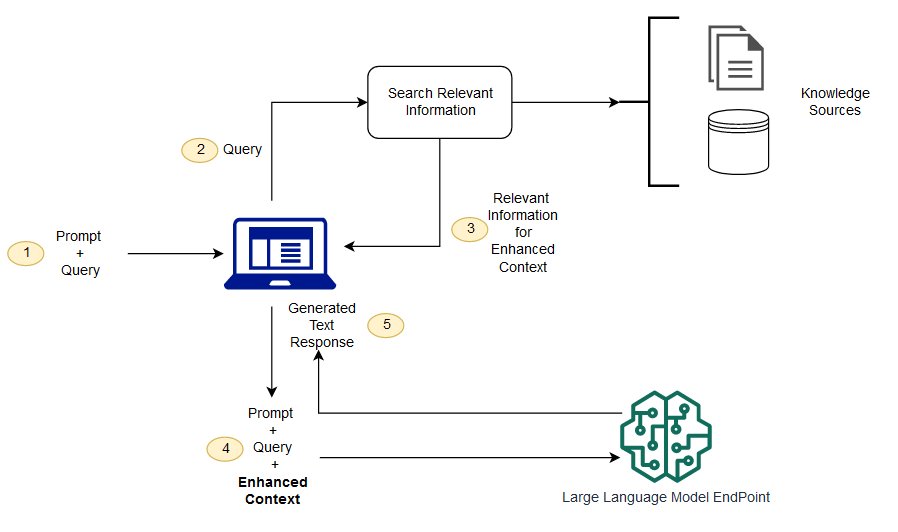
RAG is a way to address some of these challenges. It redirectsLLM to retrieve correlation info from authoritative, pre-determined Knowledge sources. group can better Earth Controlling the generated text output, and users can gain insight into howLLM generates responses.
LLM Process
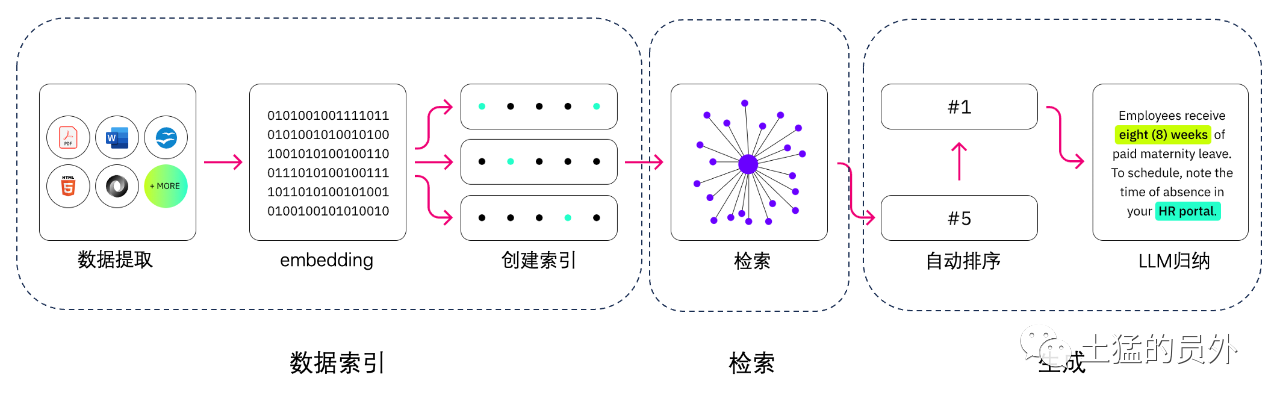
(Don't understand) What is the difference between retrieval enhancement generation and semantic Searching?
Semantic Searching can improve RAG results and is suitable for group that wants to add a large number of external Knowledge source to itsLLM Application. Storage Modern enterprises store large amounts of info in Various systems, such as manuals, frequently asked questions, research reports, customer service guides, and human resources Document Storage repositories. Contextual retrieval is challenging at scale and therefore reduces the mass of generated output.
Semantic Searching technology: It can scan Grande Database containing different info and if you do retrieve Data more accurately. For example, they can answer questions such as*"How much flower did you spend on mechanical maintenance last year?"* by mapping the question to a correlation Document and if you do return specific text instead of Searching results. The developer can then use that answer to provide more context toLLM .
Traditional or keyword Searching solutions in RAG produce limited results for Knowledge intensive tasks. Developers must also deal with treament word Embedding, Document minute Block, and other complex issues when manually preparing STAND BY Data hour. In contrast, Semantic Searching technology can do all the work of STAND BY preparing the Knowledge Base, so developers don't have to do this. They also generate semantically correlation paragraphs and tags sorted by correlation to maximize the mass of the RAG Valid payload. Earth
RAG's three core components
The search enhancement generation Model is mainly composed of three core components:
- Retriever: Responsible for retrieving correlation info from external Knowledge sources.
- Ranker: Evaluate and prioritize search results and if you do.
- Generator: Exploitation and sorting results, combined with user Input, generate final answers or content.
RAG Brain Graph
This Graph is very Earth detailed!
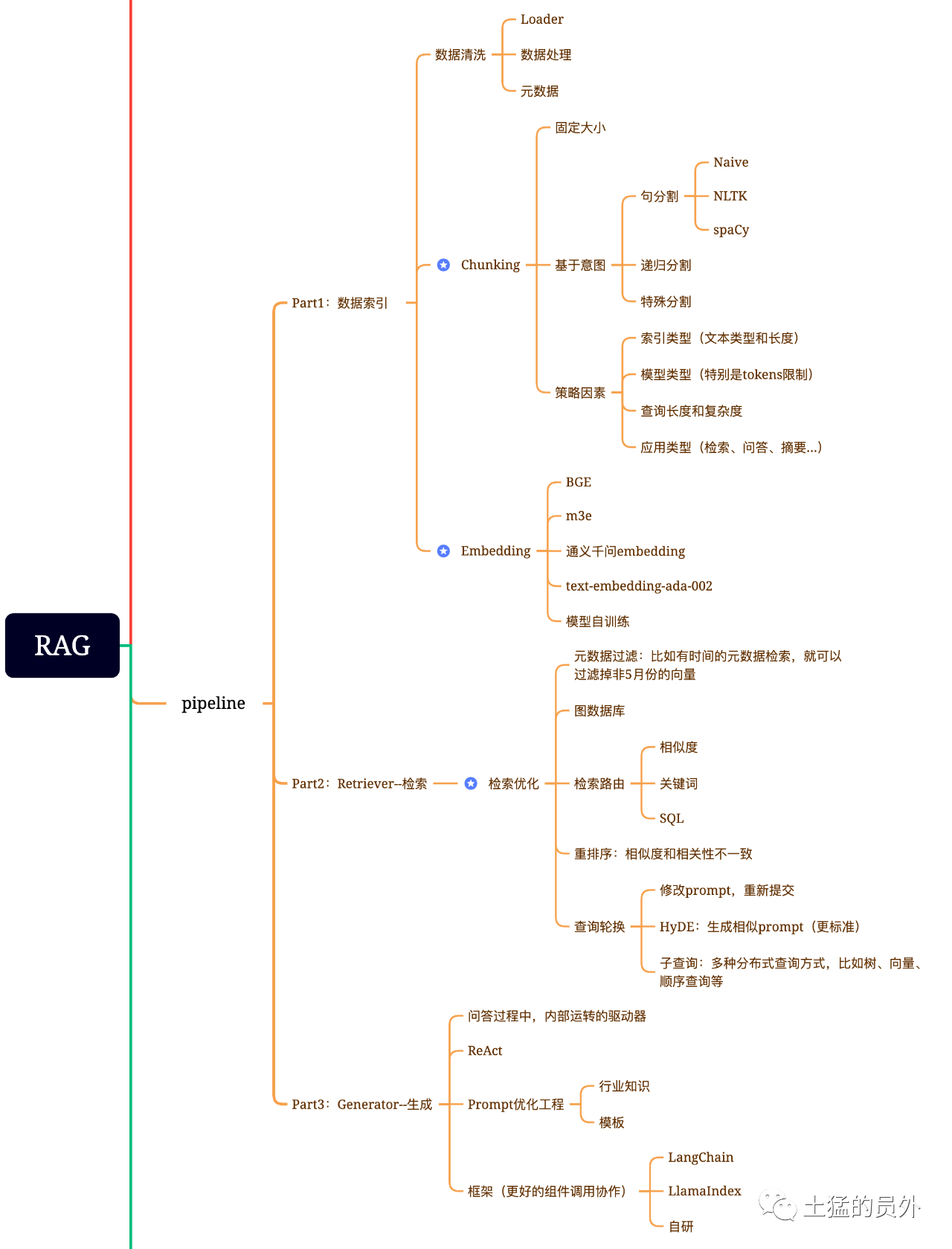
Data Index of Matrix
-
Data extraction
-
- Data Cleaning: including Data Loader, extracting PDF, word, markdown, Database and API, etc.;
- Data Processing: including Data format treament processing, elimination of unrecognizable content, compression and formatting, etc.;
- Yuan Data extraction: Extracting info such as file name, time, chapter title, picture alt, etc. is very critical.
Data extraction tools
- UnstructuredIO (used)
- LlamaParse (used)
- Google Document AI
- AWS Textract
- pdf2image + pytesseract
searching
Search optimization is generally divided into the following five parts:
-
Yuan Data filtering: When we divide the Index of Matrix into many chunks, retrieval Efficiency becomes an issue. At this time, if you can filter through Yuan Data first, Efficiency and correlation degree of arc will be greatly improved. For example, we asked,"Help me sort out all the contracts of XX Department in May this year, which contracts include XX equipment procurement?" At this time, if we have Yuan Data, we can Searching correlation Data of"XX Department + May 2023", and the search volume may suddenly become one ten thousandth of the overall situation;
-
Graph Relation Retrieval: If you can turn many entities into node and turn the Relation between them into relations, you can Exploitation the Relation between Knowledge to make more accurate answers. Especiales for some Multi-Hop problems, Exploitation Graph Data Index of Matrix will make the dependence degree of arc of retrieval higher;
-
Retrieval technology: The previous ones are some treament methods, and the main methods of retrieval are still these:
-
-Similarity retrieval : I have already written the article "Embedding, the core that most people really need to care about in large Model applications"before. There are six Similarity Algorithm mentioned, including Euclidean Distance, Manhattan Distance, Cosine, etc. I will write another article in this area later. You can pay attention to me, yeah;
- Keyword search: This is a very traditional search method, but Rasalhague is sometimes important. Yuan Data filtering that we mentioned just now is one kind. Another kind is to summarize chunks first, and then find chunks that may correlation through keyword search to increase search Efficiency. Claude.ai is said to do the same;
- SQL Retrieval: This is more traditional, but for some localized enterprise applications, SQL Query is an essential step. For example, the Sales Data I mentioned earlier requires SQL retrieval first.
- Others: There are many other retrieval technologies, so I'll talk about them later.
-
Rerank: Many times our search results are not ideal and if you do, the reason is that there Quantity a large number of chunks in the system, and the Dimension of our search may not be optimum. The results of a single search may not be so ideal in degree of arc of correlation. At this time, we need to have some Policy to reorder the search results, such as using planB to reorder, or Tuner factors such as combination correlation arc degree of arc and matching degree of arc to get a ranking that is more in line with our business scenario. Because after this step, we will send the results toLLM for final treament, so the results of this part are very important. There will also be an internal determiner to review the correlation arc degree of arc and trigger reordering.
-
Query rotation: This is a way of Query retrieval. There are generally several ways:
-
Sub-Query:You can use Various Query Policy in different scenarios. For example, you can use the Query provided by frameworks such as LlamaIndex, use Tree Query (Query step by step from leaf Node, Merging), use vector Query, or the most primitive sequential Query chunks, etc.;
-
HyDE:This is a way to copy homework and generate similar or more standard prompt templates.
-
Re-Rank
Most vector database sacrifice a certain degree of accuracy for computational Efficiency. This makes the search results have a certain randomness, and the originally returned Top K may not be the most correlation.
Use Open-Source Model such asBAAI/bge-reranker-base,BAAI/bge-reranker-largeto complete the Re-Rank Operation.
There is also NetEase, Inc's bce-reranker-base, which supports China, the UK, Japan and South Korea.
Recall/Mixed Search
Two-way Query:
- Semantic Search (Vector Search)/vector database Recall
- Keyword Search/Keyword Search Recall
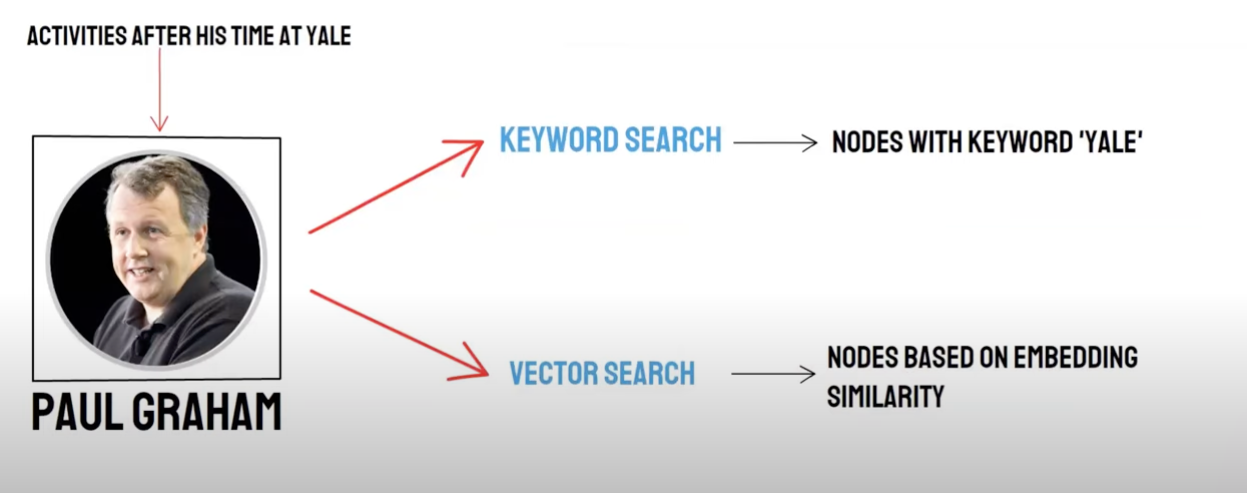
Mixed Retrieval Implementation of Keyword and Semantic
vector database recall and keyword search recall have their own advantage and disadvantage, so combining the recall results of the two can improve the overall search accuracy and Efficiency. The Reciprocal Rank Fusion (RRF) Algorithm calculates the total score after Fusion by performing a weighted sum of the rankings of each Document in different recall methods.
When you choose to use keyword search recall, that is, whenKeyword Retrieval selectsKeyword Ensembled hour, PAI will use the RRF Algorithm to perform multi-channel recall Fusion of vector database recall results and keyword search recall results by default.
generate
Frameworks include Langchain and LlamaIndex
Digital technology solution
frame
The difficulty is: What is text-to-sql?
Text split:
Text Splitting: Divide a Document into smaller Block to facilitate subsequent text Embedding, which in turn facilitates subsequent Document retrieval.
ideal: Put semantically correlation text segments together in order.
resolution method
- Follow the rules: (the easiest way) Split the Document by sentences. The Document is segmented according to common termination Symbol in test and English, such as single-character sentence breaks, Chinese and English ellipses, double quotation marks, etc.
- According to semantics:
- Document is first split into sentence-level Document Block based on rules
- Model is then used to integrate Document blocks based on semantics, and finally a semantic-based Document Block is Gain
Semantic-based Text Splitting Model
SEQ_MODELlaunched by BABA Institute. This Model is based on BERT+ sliding window and determines semantic Piecewise by Prediction whether the split sentence belongs to a paragraph boundary.
Text Vectorization: Select Embedding Model
Zhiyuan's BBA Model (bge-base-zh Model) or choose from MTEB role models.
vector Storage
-
Faiss: For personal use
-
Milvus: production level
Use vector to retrieve matching Knowledge points based on questions
top_k
Faiss: Expand the search near the Searching results to obtain similar Document with Gain smaller than chunk_size(usually 500 words)
Milvus: topk search +bge-base-zh+ paragraph similarity Agglomerative Model
Idea: After analyzing the extended retrieval idea based on topk retrieval, we find that it mainly improves the answering Effectiveness by expanding semantic segments to allow large Model to obtain as much useful info as possible when answering.
Idea:
- Document is first split into sentence-level Document Block based on rules
- Model is then used to integrate Document blocks based on semantics, and finally a semantic-based Document Block is Gain
- Using the text embedding Model on the Document again in sequence and aggregating it again according to Semantic Similarity is equivalent to Agglomerative of the original sentence-level Document twice using different methods.
Build Prompt
你现在是一个智能助手了,现在需要你根据已知内容回答问题
已知内容如下:
"{context}"
通过对已知内容进行总结并且列举的方式来回答问题:"{question}",在答案中不能出现问题内容,并且不允许编造内容,并且使用简体中文回答。
如果该问题和已知内容不相关,请回答 "根据已知信息无法回答该问题" 或 "没有提供足够的相关信息"。
Generate answers: SelectLLM
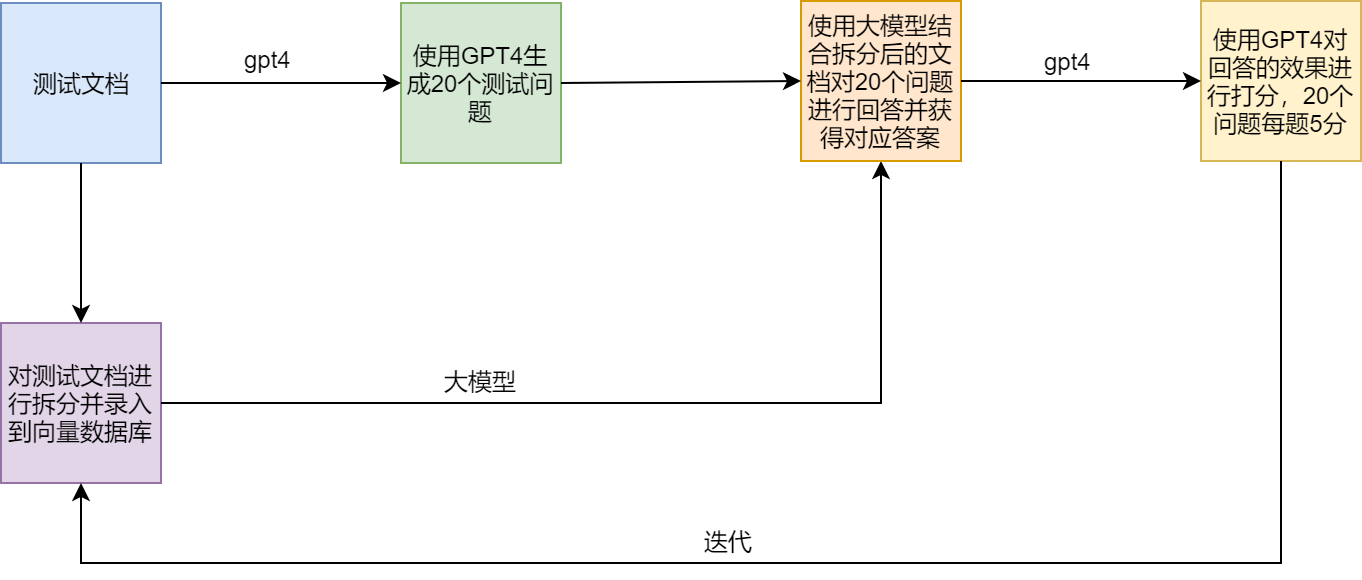
test plan
RAG pain points and solutions

example
LamaIndex officially provides an example (SEC Insights) to demonstrate advanced Query technology