Índice de Llama
Versión de Python y typescript
La versión de Python de la documentación es más completa, Ts es relativamente pobre?
INTRODUCCIÓN
Crear un entorno
conda create --name llamaindex python=3.9.19
conda activate llamaindex
Set Conda environment in VSCode
Python: Select Interpreter
Biblioteca de instalación
pip install llama-index pypdf sentence_transformers
Configurar OpenAI
vim ~/.bashrc
Añadir variabl entorno
export OPENAI_API_KEY="sk-xxxx"
Verificación
echo $OPENAI_API_KEY
- Accesibilidad**
Configurar: goproxy en la línea de órdenes
Inicio rápido
import os.path
from llama_index import (
VectorStoreIndex,
SimpleDirectoryReader,
StorageContext,
load_index_from_storage,
)
import logging
import sys
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG)
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
# check if storage already exists
PERSIST_DIR = "./storage"
if not os.path.exists(PERSIST_DIR):
# load the documents and create the index
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
# store it for later
index.storage_context.persist(persist_dir=PERSIST_DIR)
else:
# load the existing index
storage_context = StorageContext.from_defaults(persist_dir=PERSIST_DIR)
index = load_index_from_storage(storage_context)
# either way we can now query the index
query_engine = index.as_query_engine()
response = query_engine.query("What did the author do growing up?")
print(response)
** Método de terminación utilizado**
/chat/completions
** Parámetros de consulta**
{
"messages": [
{
"role": "system",
"content": "You are an expert Q&A system that is trusted around the world.\nAlways answer the query using the provided context information, and not prior knowledge.\nSome rules to follow:\n1. Never directly reference the given context in your answer.\n2. Avoid statements like \"Based on the context, ...\" or \"The context information ...\" or anything along those lines."
},
{
"role": "user",
"content": "xxx"
}
],
"model": "gpt-3.5-turbo",
"stream": false,
"temperature": 0.1
}
Prompt del sistema
You are an expert Q&A system that is trusted around the world.
Always answer the query using the provided context information, and not prior knowledge.
Some rules to follow:
1. Never directly reference the given context in your answer.
2. Avoid statements like "Based on the context, ..." or "The context information ..." or anything along those lines.
Eres un sistema de preguntas y respuestas experto de confianza en todo el mundo. Al responder preguntas, utilice siempre la información de antecedentes proporcionada, en lugar de los conocimientos previos. Algunas reglas a seguir:
1 . Nunca se refiera directamente a la información de antecedentes dada en la respuesta. 2 . Evitar el uso de "basado en información de antecedentes, ..." O "la información de antecedentes indica que..." O algo así.
Prompt de usuario
Context information is below.
---------------------
file_path: data/paul_graham_essay.txt
xxx
---------------------
Given the context information and not prior knowledge, answer the query.
Query: What did the author do growing up?
Answer:
Hipótesis de aplicación
| 应用场 | 说明 |
|---|---|
| Q&A | 最重要 |
| Chatbots | |
| Agents | 高级 |
| Structured Data Extraction | 有用,整理聊天记录等 |
| Multi-modal |
Principios básicos
Proceso básico
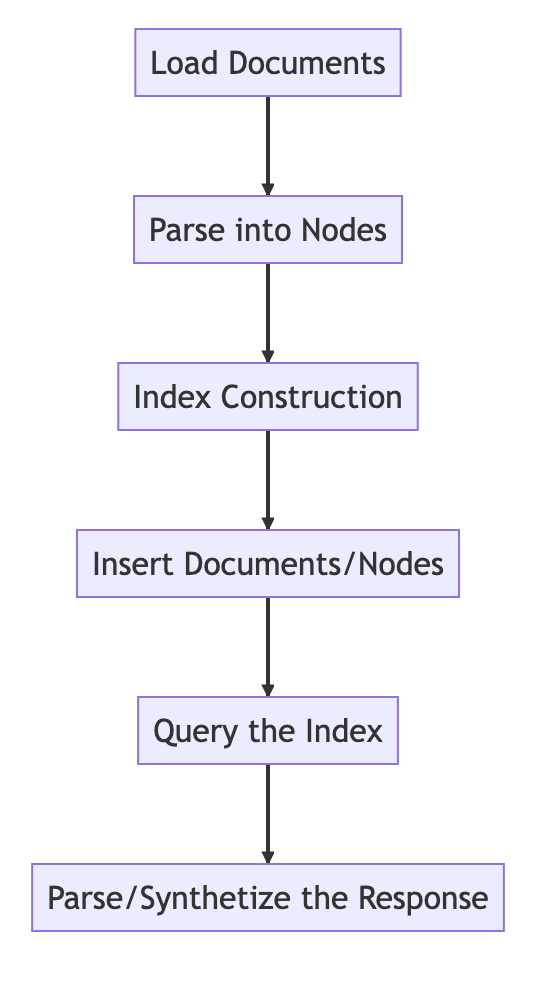
from llama_index import VectorStoreIndex, SimpleDirectoryReader
# Load in data as Document objects
documents = SimpleDirectoryReader('data').load_data()
# 切片,转成Node
# Parse Document objects into Node objects to represent chunks of data
index = VectorStoreIndex.from_documents(documents)
# Index Construction:创建索引
# Build an index over the Documents or Nodes
query_engine = index.as_query_engine()
# The response is a Response object containing the text response and source Nodes
summary = query_engine.query("What is the text about")
print("What is the data about:")
print(summary)
Chunking y Node
Datos de origen - & documentos - - · Nodos
DOCUMENTOS: Contiene información sobre el cuerpo y la meta
ID del documento
El documento es en realidad una subclase de Nodo
Es extraño que un archivo sea cortado en muchos documentos.
TextNode: Utilice NodePasser para cortar el documento en número múltiple
Incluir ID del documento
Había una conexión entre Node y Node.
- NodeParser recibe una lista de objetos de documentos 2 . Utilizando la segmentación de frases de Spacy, el texto de cada documento se divide en frases. 3 . Cada frase está envuelta en un objeto TextNode que representa un nodo
- TextNode contiene texto de oración, así como metadatos, tales como ID del documento, ubicación en el documento, etc. 5 . Devuelve una lista de objetos TextNode.
Guardar documento e índice
Dos maneras
- Guardar en disco local
- Base de datos Storage to Vector
- Guardar en disco local *
import os.path
from llama_index import (
VectorStoreIndex,
SimpleDirectoryReader,
StorageContext,
load_index_from_storage,
)
import sys
# check if storage already exists
PERSIST_DIR = "./storage"
if not os.path.exists(PERSIST_DIR):
# 保存数据: Load the documents and create the index
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
# store it for later
index.storage_context.persist(persist_dir=PERSIST_DIR)
else:
# 从磁盘加载回数据: load the existing index
storage_context = StorageContext.from_defaults(persist_dir=PERSIST_DIR)
index = load_index_from_storage(storage_context)
query_engine = index.as_query_engine()
response = query_engine.query("What did the author do growing up?")
print(response)
Construir un índice
Crear una incrustación para cada Nodo
Crear un índice en VectorStroreIndex
1 . Para VectorStoreIndex, el texto incrustado en el nodo se almacena en el índice Faiss, y la búsqueda de similitud puede hacerse rápidamente en el nodo. 2 . El índice también almacena metadatos en cada nodo, como identificación de documentos, ubicación, etc. 3 . Un nodo puede recuperar el contenido de un documento o un documento específico.
Índice de consulta
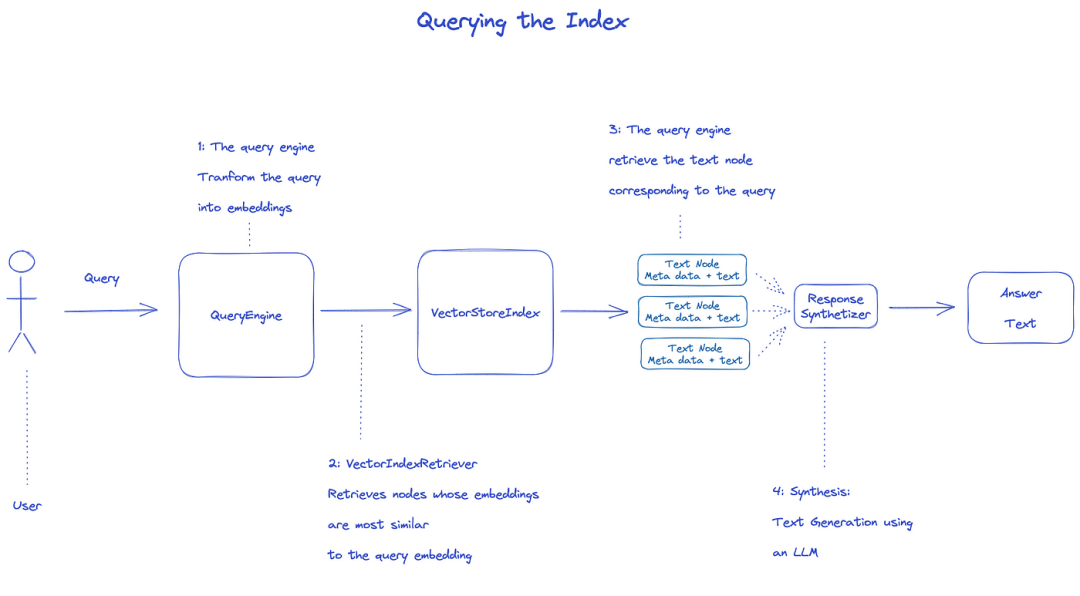
Para consultar el índice, se utilizará QueryEngine.
- Retriever obtiene los nodos relevantes del índice de la consulta. Por ejemplo, VectorIndexRetriever recupera el nodo cuya incrustación es más similar a la incrustación de la consulta 2 . La lista recuperada de nodos se pasa a ResponseSynthesizer para generar la salida final 3 . Por defecto, ResponseSynthesizer procesa cada nodo secuencialmente, y cada nodo llama a la API LLM una vez.
- LLM Inputs consulta y texto de nodo para obtener la salida final 5 . Las respuestas de cada uno de estos nodos se agregan en la cadena de salida final.
from llama_index import (
VectorStoreIndex,
get_response_synthesizer,
)
from llama_index.retrievers import VectorIndexRetriever
from llama_index.query_engine import RetrieverQueryEngine
from llama_index.postprocessor import SimilarityPostprocessor
from llama_index import StorageContext, load_index_from_storage
# rebuild storage context
storage_context = StorageContext.from_defaults(persist_dir="storage")
# load index
index = load_index_from_storage(storage_context)
# configure retriever
retriever = VectorIndexRetriever(
index=index,
similarity_top_k=10,
)
# configure response synthesizer
response_synthesizer = get_response_synthesizer()
# assemble query engine
query_engine = RetrieverQueryEngine(
retriever=retriever,
response_synthesizer=response_synthesizer,
node_postprocessors=[SimilarityPostprocessor(similarity_cutoff=0.7)],
)
# query
response = query_engine.query("What did the author do growing up?")
print(response)
Documento oficial: Entendimiento
** Tres procesos de procesamiento de datos**
Limpieza de datos / tuberías de ingeniería de características en el mundo ML, o tuberías ETL en la configuración de datos tradicional.
Esta tubería de ingestión consta típicamente de tres etapas principales:
- Cargar los datos
- Transformar los datos
- Índice y almacenamiento de los datos
Cargar datos (ingestión)
Objetivo: Formatear varios tipos de datos en objetos de `document'.
Input: Varios tipos de datos
** Salida:** Objeto Documental
3 maneras
- Utilice la clase "SimpleDirectoryReader": la más conveniente
- "Reader" en "LlamaHub": diversas herramientas que se han escrito
- Crear "document" directamente
** Clase "SimpleDirectoryReader"**
from llama_index import SimpleDirectoryReader
documents = SimpleDirectoryReader("./data").load_data()
Support Markdown, PDFs, Word documents (.docx), PowerPoint Decks, Images (.jpg, .png), audio y vídeo
Llamahub
- Notion (
NotionPageReader) - Google Docs (
GoogleDocsReader) - Slack (
SlackReader) - Discord (
DiscordReader) - Apify Actors (
ApifyActor). Can crawl the web, scrape webpages, extract text content, download files including.pdf,.jpg,.png,.docx, etc.这个可以爬虫
Crear documento Directamente
from llama_index.schema import Document
doc = Document(text="text")
Transformar datos (transformaciones)
** Razón:** Recuperación conveniente y uso eficiente de LLM
** Operaciones específicas:**
- Fragmento "Documento" (Chunking)
- Extraer metadatos (extracción de metadatos)
- Incorporación
Input: "Node"
** Salida:** "Nodo"
API encapsulada
Utilice el método «VectorStoreIndex» «From_documents»()
from llama_index import VectorStoreIndex
vector_index = VectorStoreIndex.from_documents(documents)
vector_index.as_query_engine()
Cómo personalizar parámetros
Idea: use "ServiceContext" para personalizar
text_splitter = SentenceSplitter(chunk_size=512, chunk_overlap=10)
service_context = ServiceContext.from_defaults(text_splitter=text_splitter)
index = VectorStoreIndex.from_documents(
documents, service_context=service_context
)
API atómica
Modo de uso estándar
from llama_index import Document
from llama_index.embeddings import OpenAIEmbedding
from llama_index.text_splitter import SentenceSplitter
from llama_index.extractors import TitleExtractor
from llama_index.ingestion import IngestionPipeline, IngestionCache
# 加载数据源
documents = SimpleDirectoryReader("./data").load_data()
# 创建转换数据的工作流
# create the pipeline with transformations
pipeline = IngestionPipeline(
transformations=[
SentenceSplitter(chunk_size=25, chunk_overlap=0), # 分片
TitleExtractor(), # 提取Meta信息
OpenAIEmbedding(), # Embedding
]
)
# 执行流程,生成节点
# run the pipeline
nodes = pipeline.run(documents=documents)
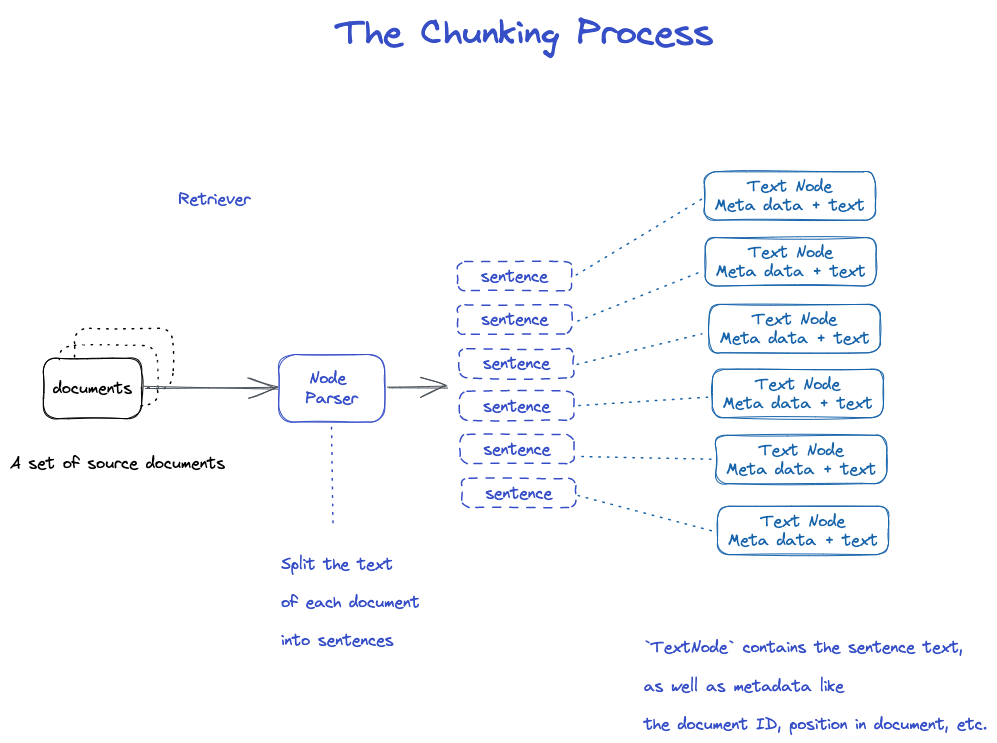
Rebanada
Hay muchas estrategias, como se especifica en el módulo Node Parser.
Añadir metadatos
Puede personalizar documentos y notas para añadir metadatos.
Crear un objeto Node directamente
from llama_index.schema import TextNode
node1 = TextNode(text="<text_chunk>", id_="<node_id>")
node2 = TextNode(text="<text_chunk>", id_="<node_id>")
index = VectorStoreIndex([node1, node2])
Índice
** Clasificación del índice**
- Vector Stores
- Document Stores
- Index Stores
- Key-Value Stores
- Using Graph Stores
- [Chat Stores] (
** Índices comunes**
- Índice resumido (anteriormente índice de lista)
- Índice de Store Vector (más común)
- Índice de árboles
- Índice de Tabla de Palabras Clave
** Índice resumido (anteriormente Índice de lista)**

** Índice de Store Vector**

** Índice de Árboles**

Índice de Tabla de Palabras Clave**

Meta
Añadir meta
document.metadata['lang'] = lang
Filtrar
from llama_index.core.vector_stores import (
ExactMatchFilter,
MetadataFilters,
MetadataFilter,
)
filters = MetadataFilters(
filters=[
MetadataFilter(key="post_year", value="2017"),
],
)
# You pass filter as an argument. You can have any type of filter
# we saw above and then pass it to query engine.
query_engine = index.as_query_engine(service_context=service_context,
similarity_top_k=5,
filters = filters,
response_mode='tree_summarize')
response = query_engine.query("Marathon Running")
print(response)
Modos de respuesta
- Refinar: Generar respuestas una por una con contexto; utilizar la plantilla text_qa_plantilla primero, y luego utilizar la plantilla refina_template.
- compacta: por defecto. Similar a refinar, sin embargo, el contexto está repleto de una solicitud.
- árbol_resumen
- Simple_resumen
Código fuente
Documento
· Un `Documento' es una subclase de un 'Nodo')
Contiene:
-
Texto
-
"Metadata"
-
"Casas": relación con otros documentos/nodos
** Proceso de utilización atómica**
from llama_index import Document, VectorStoreIndex
# 数据源
text_list = [text1, text2, ...]
# 手动创建documents
documents = [Document(text=t) for t in text_list]
# 建立索引: 传入document,在VectorStoreIndex再转换:分片转成Node,Embedding等
index = VectorStoreIndex.from_documents(documents)
Varios métodos de creación de documentos
Crear manualmente
from llama_index import Document
text_list = [text1, text2, ...]
documents = [Document(text=t) for t in text_list]
** Usar el cargador de datos (conector)**
Todos tienen un método load_data()
from llama_index import SimpleDirectoryReader
documents = SimpleDirectoryReader("./data").load_data()
** Datos de muestra generados automáticamente**
document = Document.example()
Meta personalizada
from llama_index import Document
from llama_index.schema import MetadataMode
document = Document(
text="This is a super-customized document",
metadata={
"file_name": "super_secret_document.txt",
"category": "finance",
"author": "LlamaIndex",
},
excluded_llm_metadata_keys=["file_name"],
metadata_seperator="::",
metadata_template="{key}=>{value}",
text_template="Metadata: {metadata_str}\n-----\nContent: {content}",
)
print(
"The LLM sees this: \n",
document.get_content(metadata_mode=MetadataMode.LLM),
)
print()
print(
"The Embedding model sees this: \n",
document.get_content(metadata_mode=MetadataMode.EMBED),
)
Producto
The LLM sees this:
Metadata: category=>finance::author=>LlamaIndex
-----
Content: This is a super-customized document
The Embedding model sees this:
Metadata: file_name=>super_secret_document.txt::category=>finance::author=>LlamaIndex
-----
Content: This is a super-customized document
Patrón de uso de extracción de metadatos (no entiendes)
Nodo
Esencia: Fragmentación del documento
Cómo obtener:
- Utilice la clase NodePasser para convertir el documento a Node
- Crear manualmente
Al igual que el documento, hay:
-
Texto
-
"Metadata"
-
"Casas": relación con otros documentos/nodos
Cuando se convierte del documento a Node, la información como metadatos es heredada.
Nodo es un ciudadano de primera clase en LlamaIndex.
** Proceso de utilización atómica**
from llama_index.node_parser import SentenceSplitter
# load documents
...
# 手动转换:切片,转成Node
# parse nodes
parser = SentenceSplitter()
nodes = parser.get_nodes_from_documents(documents)
# build index
index = VectorStoreIndex(nodes)
Set relationship
from llama_index.schema import TextNode, NodeRelationship, RelatedNodeInfo
node1 = TextNode(text="text_chunk1", id_="node_id1")
node2 = TextNode(text="text_chunk2", id_="node_id2")
node3 = TextNode(text="text_chunk3", id_="node_id3")
# set relationships
node1.relationships[NodeRelationship.NEXT] = RelatedNodeInfo(
node_id=node2.node_id
)
node2.relationships[NodeRelationship.PREVIOUS] = RelatedNodeInfo(
node_id=node1.node_id
)
node2.relationships[NodeRelationship.PARENT] = RelatedNodeInfo(
node_id=node3.node_id, metadata={"key": "val"}
)
print(node2)
NodePasserCity in California USA
Finalidad: Convertir fuentes de datos en objetos de Nodo
Específico: Fragmentar un grupo de objetos de documento en múltiples objetos de Nodo
Aplicación concreta común
NodeParser es una clase abstracta, que se implementa de la siguiente manera:
** Por tipo de archivo**
- SimpleFileNodePasser
- HTMLNodePasser
- JSONNodePasser
- MarkdownNodeParser
Segmentación de texto
- CodeSplitter
- LangchainNodePasser
- SentenceSplitter
- SentenceWindowNodePasser (no entiendo)
- SemanticSplitterNodePasser (no entiendo, se siente más avanzado)
- TokenTextSplitter
- Padre - Relación de Hijos *
- HierarchicalNodePasser: utilizado en AutoMergingRetriever
Uso típico
** Uso atómico**
from llama_index import Document
from llama_index.node_parser import SentenceSplitter
# 创建NodeParser
node_parser = SentenceSplitter(chunk_size=1024, chunk_overlap=20)
# 调用 get_nodes_from_documents() 方法
# show_progress 可以显示进度
nodes = node_parser.get_nodes_from_documents(
[Document.example(), Document.example()], show_progress=True
)
print(len(nodes))
print()
print(nodes[0])
Producto
2
Node ID: eaeb6e44-6828-4e36-b7a3-69342de4dc7c
Text: Context LLMs are a phenomenal piece of technology for knowledge
generation and reasoning. They are pre-trained on large amounts of
publicly available data. How do we best augment LLMs with our own
private data? We need a comprehensive toolkit to help perform this
data augmentation for LLMs. Proposed Solution That's where LlamaIndex
comes in. Ll...
Transformaciones # # en piplina
from llama_index import Document
from llama_index.node_parser import SentenceSplitter
from llama_index.ingestion import IngestionPipeline
from llama_index.node_parser import TokenTextSplitter
documents = [Document.example(), Document.example()]
# 创建NodeParser
node_parser = SentenceSplitter(chunk_size=1024, chunk_overlap=20)
# 将NodeParser放到Pipeline中的transformations列表
pipeline = IngestionPipeline(transformations=[node_parser])
nodes = pipeline.run(documents=documents)
print(len(nodes))
print()
print(nodes[0])
Usar ServiceContext
from llama_index import Document, ServiceContext, VectorStoreIndex
from llama_index.node_parser import SentenceSplitter
from llama_index.ingestion import IngestionPipeline
from llama_index.node_parser import TokenTextSplitter
documents = [Document.example(), Document.example()]
node_parser = SentenceSplitter(chunk_size=1024, chunk_overlap=20)
service_context = ServiceContext.from_defaults(text_splitter=node_parser)
index = VectorStoreIndex.from_documents(
documents, service_context=service_context, show_progress=True
)
Transformaciones
Entrada: un conjunto de Nodo
Salida: un conjunto de Node
Hay dos maneras comunes:
- ___llamada _() : Sincronizar
- `Asincrónico()': acall
NodePasser y "MetadataExtractor" pertenecen a las transformaciones
** Modo de uso**
from llama_index.text_splitter import SentenceSplitter
from llama_index.extractors import TitleExtractor
node_parser = SentenceSplitter(chunk_size=512)
extractor = TitleExtractor()
# use transforms directly
nodes = node_parser(documents)
# or use a transformation in async
nodes = await extractor.acall(nodes)
** Combinado con ServiceContext**
from llama_index import ServiceContext, VectorStoreIndex
from llama_index.extractors import (
TitleExtractor,
QuestionsAnsweredExtractor,
)
from llama_index.ingestion import IngestionPipeline
from llama_index.text_splitter import TokenTextSplitter
transformations = [
TokenTextSplitter(chunk_size=512, chunk_overlap=128),
TitleExtractor(nodes=5),
QuestionsAnsweredExtractor(questions=3),
]
# 创建ServiceContext,传入Transfrmation
service_context = ServiceContext.from_defaults(
transformations=[text_splitter, title_extractor, qa_extractor]
)
# 传入VectorStoreIndex的from_documents()或insert()方法
index = VectorStoreIndex.from_documents(
documents, service_context=service_context
)
ServicioContexto
· Un conjunto de servicios y configuraciones utilizados a través de una tubería de LlamaIndex.
Se puede configurar
from llama_index import (
ServiceContext,
OpenAIEmbedding,
PromptHelper,
)
from llama_index.llms import OpenAI
from llama_index.text_splitter import SentenceSplitter
# 设置LLM
llm = OpenAI(model="text-davinci-003", temperature=0, max_tokens=256)
# 设置Embedding模型
embed_model = OpenAIEmbedding()
# 设置Chunk的大小
text_splitter = SentenceSplitter(chunk_size=1024, chunk_overlap=20)
prompt_helper = PromptHelper(
context_window=4096,
num_output=256,
chunk_overlap_ratio=0.1,
chunk_size_limit=None,
)
service_context = ServiceContext.from_defaults(
llm=llm, # 设置LLM
embed_model=embed_model, # 设置Embedding模型
text_splitter=text_splitter, # 设置Chunk的大小
prompt_helper=prompt_helper,
)
** Parámetros de construcción** (más conveniente)
** Kwargs para analizador de nodos**:
- "Chunk_size"
- "Chunk_Superposición"
Kwargs for Prompt Helper:
- "Window": "Window":
- "num_output"
Por ejemplo
service_context = ServiceContext.from_defaults(chunk_size=1000)
** Configuración global**
from llama_index import set_global_service_context
set_global_service_context(service_context)
Configuración local
query_engine = index.as_query_engine(service_context=service_context)
StorageContext
Define el motor de almacenamiento para donde se almacenan los documentos, incrustaciones e índices.
[Referencia API] (https://docs.llamaindex.ai/en/stable/api_reference/)
store = PGVectorStore(
connection_string=conn_string,
async_connection_string=async_conn_string,
schema_name=PGVECTOR_SCHEMA,
table_name=PGVECTOR_TABLE,
)
index = VectorStoreIndex.from_vector_store(store)
VectorStoreIndex
Función constructora
index = VectorStoreIndex.from_vector_store(store)
Hay dos tipos de motor:
- Query Engine: BaseQueryEngine
- Chat Engines: BaseChatEngine
Crear motor
index.as_query_engine()# BaseQueryEngine
index.as_query_engine(streaming=True)# 流式 BaseQueryEngine
index.as_chat_engine() # BaseChatEngine; 流式不是在这里控制
Consulta
# Query
response = await query_engine.aquery(query) # 流式
response = await query_engine.aquery(query)
# Chat
response = await chat_engine.astream_chat(last_message_content, messages) # 流式在这里控制
response = await chat_engine.achat(last_message_content, messages)
BaseQueryEngine
- consulta
- Acuery
BaseChatEngine
- Chat
- stream_chat
- Achat
- astream_chat
& Soportes streaming: stream
·Asincrónico es compatible: a partir de un
Tipo de respuesta
# Query
RESPONSE_TYPE = Union[
Response,
StreamingResponse, AsyncStreamingResponse, #流式
PydanticResponse
]
# Chat
StreamingAgentChatResponse #流式
AGENT_CHAT_RESPONSE_TYPE = Union[AgentChatResponse, StreamingAgentChatResponse] #非流式
Cómo lidiar con la respuesta al streaming
· Utilice las API estándar de Python:
<> - StreamingResponse()
-
AsyncStreamingResponse > - StreamingResponse
-
Consulta
@r.post("")
async def chat(
request: Request,
queryData: _QueryData,
query_engine: BaseQueryEngine = Depends(get_query_engine_stream),
):
query = queryData.query
streaming_response = await query_engine.aquery(query)
async def event_generator():
async for token in streaming_response.async_response_gen:
if await request.is_disconnected():
break
yield f"data: {token}\n\n"
return StreamingResponse(event_generator(), media_type="text/event-stream")
- Chatear
@r.post("")
async def chat(
request: Request,
data: _ChatData,
chat_engine: BaseChatEngine = Depends(get_chat_engine),
):
last_message_content, messages = await parse_chat_data(data)
response = await chat_engine.astream_chat(last_message_content, messages)
async def event_generator():
async for token in response.async_response_gen():
if await request.is_disconnected():
break
yield token
return StreamingResponse(event_generator(), media_type="text/plain")
StreamingResponse
class AsyncStreamingResponse:
async_response_gen: TokenAsyncGen
class StreamingResponse:
response_gen: TokenGen
Modos de respuesta
Monitor y control
Tutoriales
Tutorial Deeplearn
Building and Evaluating Advanced RAG Applications:链接 Bilibili
** Texto conjunto a SQL y búsqueda semántica**
Este vídeo cubre las herramientas incorporadas en LlamaIndex para combinar SQL y búsqueda semántica en una única interfaz de consulta unificada.