RAG:检索增强生成
El RAG
Trag: Generación aumentada de recuperación
Estás tratando de resolver un caso complicado:
El papel de un detective es reunir pistas, pruebas y registros históricos relacionados con el caso. Después de que el detective recolectó la información, el reportero resumió los hechos en una historia fascinante y presentó una narrativa coherente.
El problema con LLM
- Alucinación: proporcionar información falsa sin respuesta.
- LLM utiliza información anticuada, y no tiene acceso a la información más reciente y fiable después de su fecha límite de conocimiento.
- Además, la respuesta proporcionada por LLM no se refiere a su fuente, lo que significa que su afirmación no puede ser verificada por el usuario como exacta o totalmente confiable. Esto pone de relieve la importancia de la verificación y evaluación independientes cuando se utiliza información generada por la inteligencia artificial.
您可以将大型语言模型看作是一个过于热情的新员工,他拒绝随时了解时事,但总是会绝对自信地回答每一个问题。
RAG es una manera de resolver algunos de estos desafíos. Redirecciona a la LLM para recuperar la información pertinente de fuentes autorizadas y predeterminadas de conocimiento. Las organizaciones tienen más control sobre la salida de texto generada, y los usuarios pueden aprender más acerca de cómo LLM genera respuestas.
El proceso de LLM
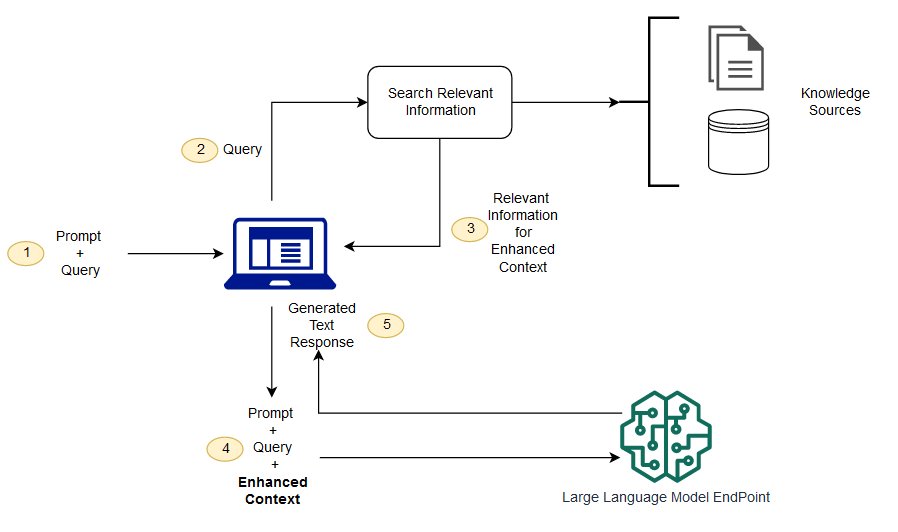
(No entiendo) ¿Cuál es la diferencia entre la generación de mejora de recuperación y la búsqueda semántica?
La búsqueda semántica puede mejorar los resultados de RAG para las organizaciones que desean añadir un gran número de fuentes externas de conocimiento a sus aplicaciones de MLL. Las empresas modernas almacenan una gran cantidad de información en una variedad de sistemas, como manuales, preguntas frecuentes, informes de investigación, guías de servicio al cliente y repositorios de documentos de recursos humanos. La recuperación contextual es difícil en escala y, por lo tanto, degrada la calidad de la producción generada.
Tecnología de búsqueda semántica: puede escanear grandes bases de datos que contengan información diferente y recuperar datos con mayor precisión. Por ejemplo, pueden responder preguntas como * "¿Cuánto gastaste en mantenimiento mecánico el año pasado?" Preguntas como * mapeando la pregunta al documento pertinente y devolviendo texto específico en lugar de resultados de búsqueda. Los desarrolladores pueden entonces usar esta respuesta para proporcionar más contexto para LLM.
Las soluciones tradicionales o de búsqueda de palabras clave en RAG producen resultados limitados para el conocimiento - tareas intensivas. Los desarrolladores también tienen que lidiar con la integración de palabras, la fragmentación de documentos y otros temas complejos al preparar los datos manualmente. Por el contrario, la tecnología de búsqueda semántica puede hacer todo el trabajo para el que la base de conocimientos está preparada, por lo que los desarrolladores no tienen que hacerlo. También generan párrafos semánticamente relacionados y palabras de marcado ordenadas por relevancia para maximizar la calidad de la carga útil trag.
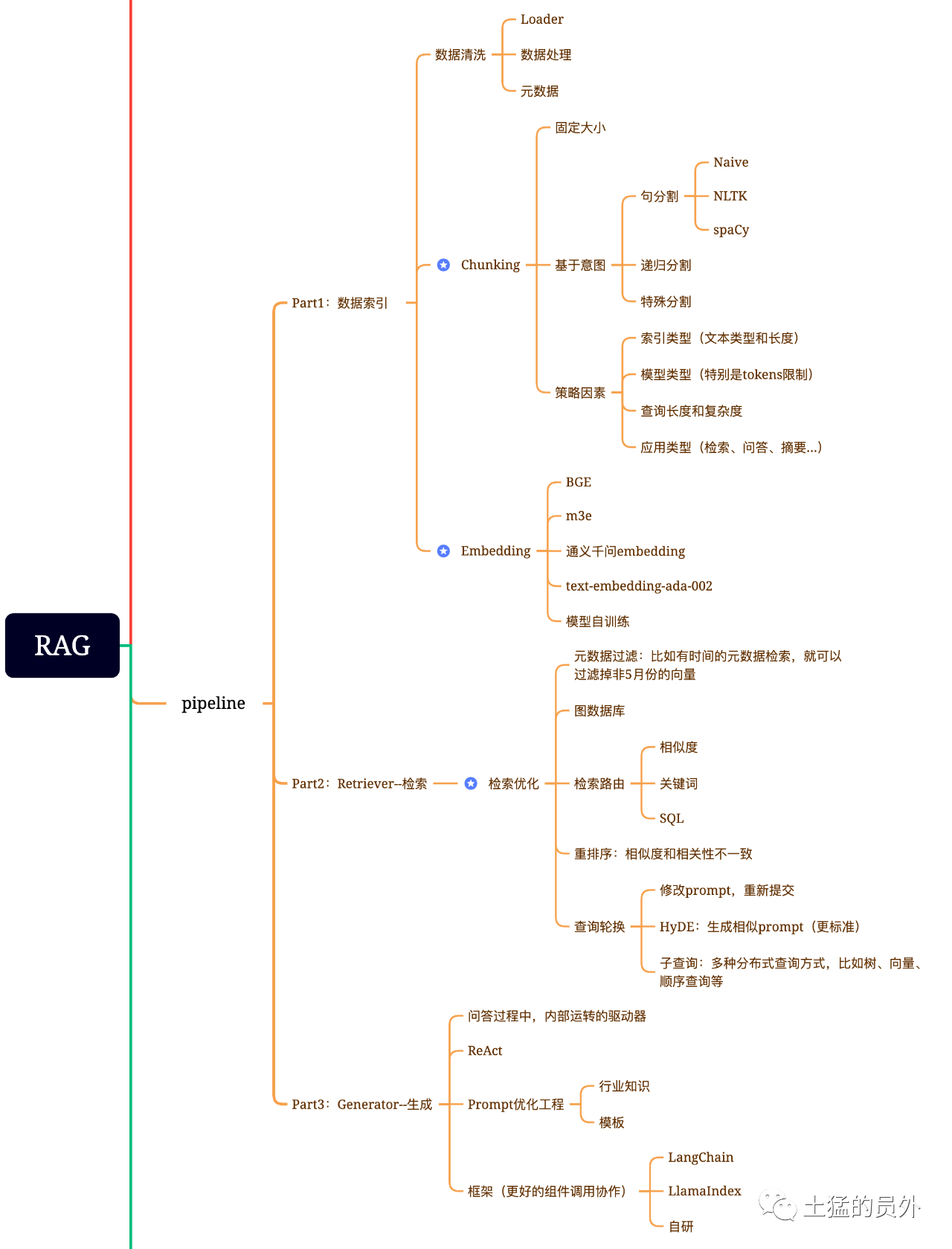
Tres componentes básicos de RAG
El modelo de generación mejorada de recuperación se compone principalmente de tres componentes básicos:
- Retriever: responsable de recuperar la información pertinente de fuentes externas de conocimientos.
- Sorter (Ranker): evalúa y prioriza los resultados de la búsqueda.
- Generador: Utilice los resultados de recuperación y clasificación, combinados con la entrada del usuario, para generar la respuesta o contenido final.
Mapa cerebral de trapos
¡Esta foto es muy detallada!
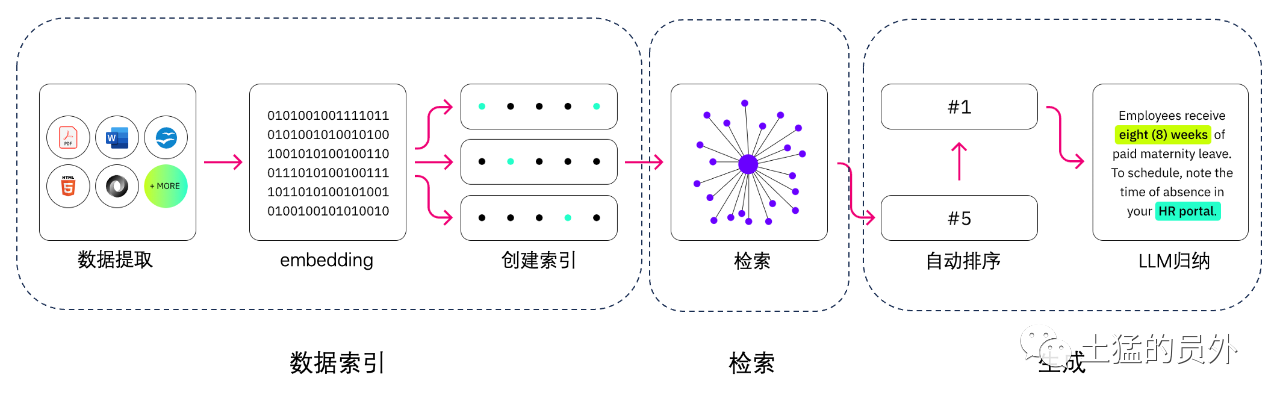
Indexación de datos
- Extracción de datos
Limpieza de datos: Incluyendo loader de datos, extracción de PDF, Word, markdown, base de datos y API, etc.
- Procesamiento de datos: incluyendo el procesamiento del formato de datos, la eliminación del contenido no identificable, la compresión y el formato, etc.
- Extracción de metadatos: es fundamental extraer el nombre del archivo, el tiempo, el título del capítulo, alt de la imagen y otra información.
Herramientas para la extracción de datos
- UnstructuredIO (utilizado)
- LlamaParse (utilizado)
- Google document AI
- AWS Textract
- pdf2image + pytesseract
Buscar
La optimización de la recuperación se divide generalmente en las cinco partes siguientes:
-** Filtrado de metadatos**: Cuando dividamos el índice en muchos trozos, la eficiencia de recuperación será un problema. En este momento, si los metadatos pueden filtrarse primero, la eficiencia y la pertinencia mejorarán considerablemente. Por ejemplo, nos preguntamos, "Ayúdame a ordenar todos los contratos en el departamento XX en mayo de este año, que incluyen la compra de equipo XX?" . En este momento, si hay metadatos, podemos buscar los datos relevantes de "XX Department + May 2023", y la cantidad de recuperación puede convertirse en 1/10000 de la situación global a la vez.
-
Graph Relation Retrieval: Si puedes convertir muchas entidades en nodo y la relación entre ellas en relación, puedes usar la relación entre conocimiento para hacer respuestas más precisas. Especialmente para algunos problemas multi-hop, el uso del índice de datos gráfico hará que la recuperación sea más relevante.
-
Tecnología Retrieval: mencionados anteriormente son algunos métodos de preprocesamiento, y los principales métodos de recuperación son los siguientes:
-
- 相似度检索:前面我已经写过那篇文章《大模型应用中大部分人真正需要去关心的核心——Embedding》中有提到六种相似度算法,包括欧氏距离、曼哈顿距离、余弦等,后面我还会再专门写一篇这方面的文章,可以关注我,yeah;
-
Búsqueda de palabras clave: Este es un método de búsqueda muy tradicional, pero a veces también es muy importante. El filtrado de metadatos que acabamos de mencionar es un tipo, y otro es hacer un resumen de Chunk primero, y luego encontrar el posible fragmento relevante a través de la recuperación de palabras clave para aumentar la eficiencia de la recuperación. Se dice que Claude.ai ha hecho lo mismo.
-
SQL Search: Esto es más tradicional, pero para algunas aplicaciones empresariales localizadas, la consulta SQL es un paso esencial. Por ejemplo, los datos de ventas que mencioné anteriormente necesitan ser buscados por SQL primero.
-
Otros: todavía hay muchas técnicas de recuperación, así que hablemos de ello más tarde.
-
ReRank: En muchos casos, nuestros resultados de recuperación no son ideales porque hay un gran número de trozos en el sistema, y las dimensiones que recuperamos no son necesariamente óptimas, y los resultados de una búsqueda pueden no ser tan ideales en términos de relevancia. En este momento, necesitamos tener algunas estrategias para reordenar los resultados de la recuperación, como el uso de planb para reordenar, o para ajustar la relevancia combinada, emparejamiento y otros factores para obtener un ranking más acorde con nuestro escenario de negocio. Porque después de este paso, enviaremos el resultado a LLM para el procesamiento final, por lo que el resultado de esta parte es muy importante. También habrá un juez interno que revisará la correlación y desencadenará el reordenamiento.
-** Rotación de consulta**: Esta es una forma de consulta y recuperación, y por lo general hay varias maneras:
-** Sub - Consulta:** Puede utilizar varias estrategias de consulta en diferentes escenarios. Por ejemplo, puede utilizar el querier proporcionado por marcos como LlamaIndex, consulta de árbol (de nodos de hojas, consulta paso a paso, fusión), consulta vectorial, o los trozos de consulta secuenciales más primitivos, etc.;
- Hyde: Esta es una forma de copiar trabajos para generar plantillas de prompt similares o más estándar. ♪
Re-Rank
La mayoría de las bases de datos vectoriales sacrifican cierto grado de precisión para la eficiencia computacional. Esto hace que los resultados de recuperación sean aleatorios, y el original devuelto Top K no es necesariamente el más relevante.
使用BAAI/bge-reranker-base、BAAI/bge-reranker-large等开源模型来完成Re-Rank操作。
Y la base de NetEase - reranker - apoya a China, Gran Bretaña, Japón y Corea del Sur.
Recuperación/recuperación mixta
Pregunta de dos vías:
- recuperación semántica (búsqueda Vector) /** Recuperación de la base de datos vectorial**
- búsqueda de palabras clave (búsqueda de palabras clave) / memoria de búsqueda de palabras clave
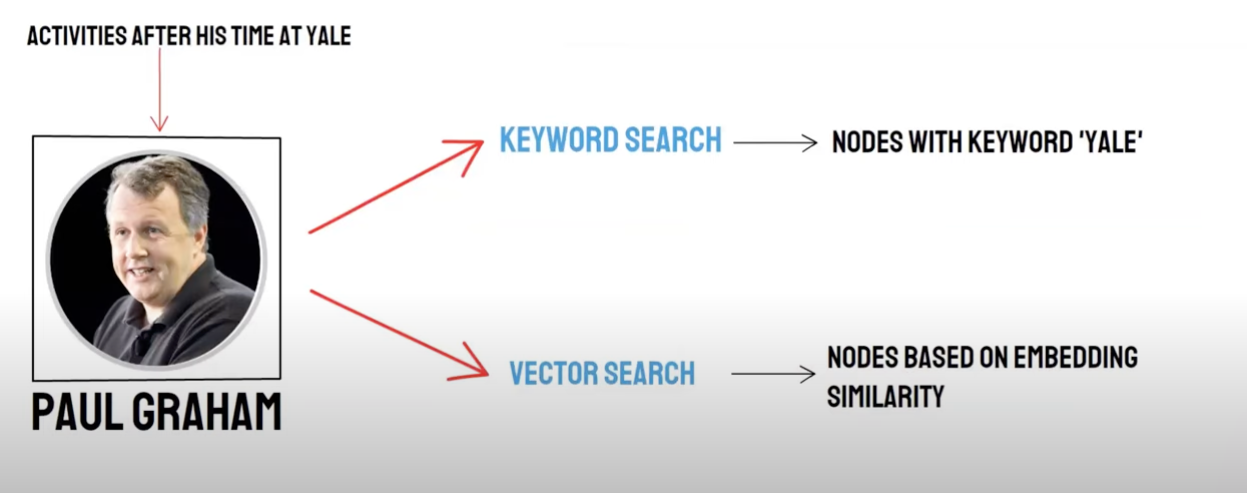
La memoria de la base de datos vectorial y la recuperación de palabras clave tienen sus propias ventajas y desventajas, por lo que la combinación de los resultados de la recuperación de los dos puede mejorar la exactitud y eficiencia general de la recuperación. El algoritmo de fusión recíproca de tipo (Recíproca Fusión Rank, RRF) calcula la puntuación total después de la fusión mediante la suma ponderada de la clasificación de cada documento en diferentes métodos de memoria.
Cuando elija usar memoria de recuperación de palabras clave, es decir,** palabra clave Retrievalselect palabra clave ensamble**, PAI usará algoritmo RRF por defecto para multiplex los resultados de memoria de base de datos vectorial y recuperación de palabras clave.
Generar
El marco tiene Langchain y LlamaIndex
El esquema de la tecnología de recuento y recolección
Marco
La dificultad es: ¿Qué es texto - a - SQL?
Texto dividido:
Fraccionamiento de textos: El documento se divide en bloques más pequeños para facilitar la posterior incorporación de textos y, a continuación, facilitar la recuperación posterior de documentos.
Idealmente: Coloque piezas de texto semánticamente relacionadas en orden.
Método dividido
- Según la regla: (la forma más fácil) de dividir el documento por frase. El documento se divide de acuerdo con los símbolos comunes de terminación en chino e inglés, tales como interruptor de caracteres individuales, chino e inglés elipsis, comillas dobles, etc.
- Basado en la semántica: 1 . En primer lugar, el documento se divide en bloques de documentos de nivel de oración basados en reglas. 2 . A continuación, utilice el modelo para integrar los bloques de documentos basados en la semántica, y finalmente obtener los bloques semánticos - basados en documentos.
Semántico - modelo de división de textos basado en la base
El modelo SEQ_MODEL** desarrollado por Ali Dama Institute se basa en la ventana deslizante Bert+, que determina la semántica segmentación prediciendo si la frase dividida pertenece al límite del párrafo.
Vectorización de texto: Seleccione el modelo de incrustación
Modelo BBA de Zhiyuan (BGE - base - modelo ZH) o elegir entre el ejemplo MTEB.
Almacenamiento vectorial
-
Faiss: para uso personal
-
Milvus: nivel de producción
Utilice Vector para recuperar puntos de conocimiento coincidentes de acuerdo con las preguntas.
Top_k
Faiss: Haga una búsqueda extendida cerca de los resultados de la búsqueda para obtener documentos similares que son menores que chunk_size (generalmente 500 palabras)
Milvus: TOPK Retrieval + BGE - base - zh + modelo de agregación de similitud de párrafo
IDEA: Analizar la idea de recuperación extendida basada en la recuperación de TOPK, encontramos que es principalmente a través de la expansión de segmentos semánticos para hacer que el modelo grande obtenga tanta información útil como sea posible para mejorar el efecto de la respuesta.
Tren de pensamiento:
- En primer lugar, el documento se divide en bloques de documentos de nivel de oración basados en reglas.
- A continuación, utilice el modelo para integrar los bloques de documentos basados en la semántica, y finalmente obtener los bloques semánticos - basados en documentos.
- En tercer lugar, el modelo de incrustación de textos se utiliza para los documentos secuencialmente, y los documentos se agregan de nuevo de acuerdo con la similitud semántica, lo que equivale a agregar la frase original - documentos de nivel dos veces con diferentes métodos.
Construir prompt
你现在是一个智能助手了,现在需要你根据已知内容回答问题
已知内容如下:
"{context}"
通过对已知内容进行总结并且列举的方式来回答问题:"{question}",在答案中不能出现问题内容,并且不允许编造内容,并且使用简体中文回答。
如果该问题和已知内容不相关,请回答 "根据已知信息无法回答该问题" 或 "没有提供足够的相关信息"。
Generar respuesta: seleccionar LLM
Sistema de ensayo
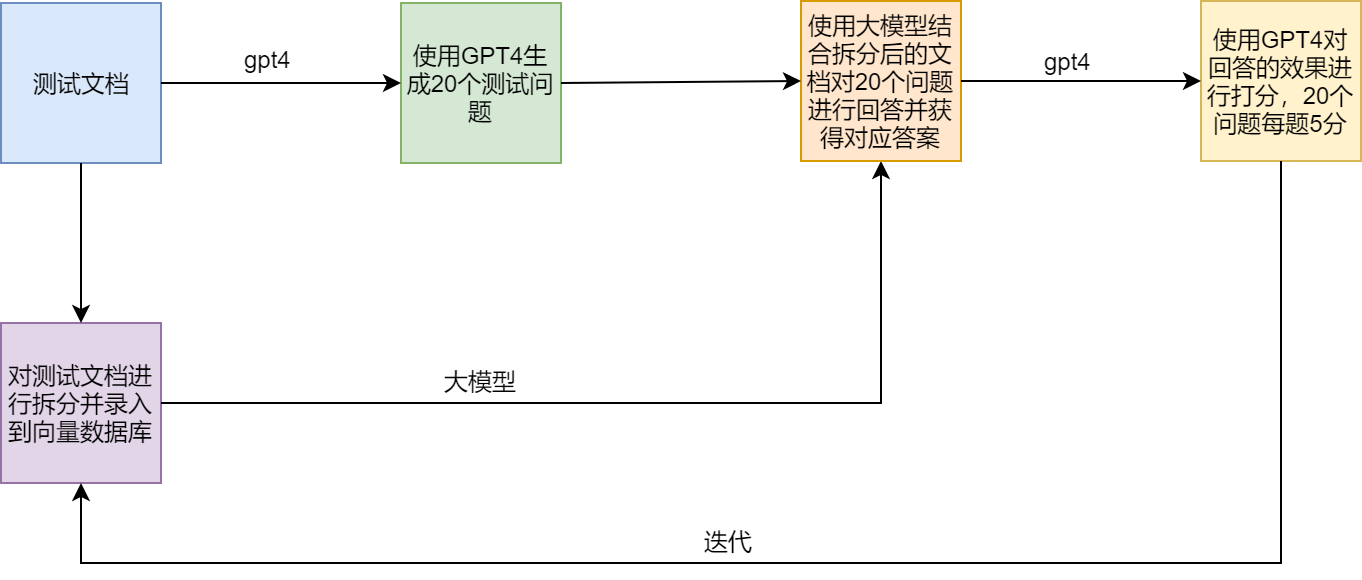
Puntos de dolor y soluciones del trapo

Ejemplos
LamaIndex官方提供了一个范例(SEC Insights),用来展示高级查询技术