RAG:检索增强生成
le RAG
RAG: REtrieval Augmented Generation
Vous essayez de résoudre une affaire compliquée:
Le rôle d'un détective est de recueillir des indices, des preuves et des documents historiques liés à l'affaire. Après que le détective ait recueilli les informations, le journaliste a résumé les faits en une histoire fascinante et a présenté un récit cohérent.
Le problème avec LLM
- Hallucination: fournir de fausses informations sans réponse.
- LLM utilise des informations obsolètes et n'a pas accès aux informations les plus récentes et fiables après sa date limite de connaissance.
- En outre, la réponse fournie par LLM ne fait pas référence à sa source, ce qui signifie que sa réclamation ne peut pas être vérifiée par l'utilisateur comme étant exacte ou entièrement fiable. Cela souligne l'importance de la vérification et de l'évaluation indépendantes lors de l'utilisation des informations générées par l'intelligence artificielle.
您可以将大型语言模型看作是一个过于热情的新员工,他拒绝随时了解时事,但总是会绝对自信地回答每一个问题。
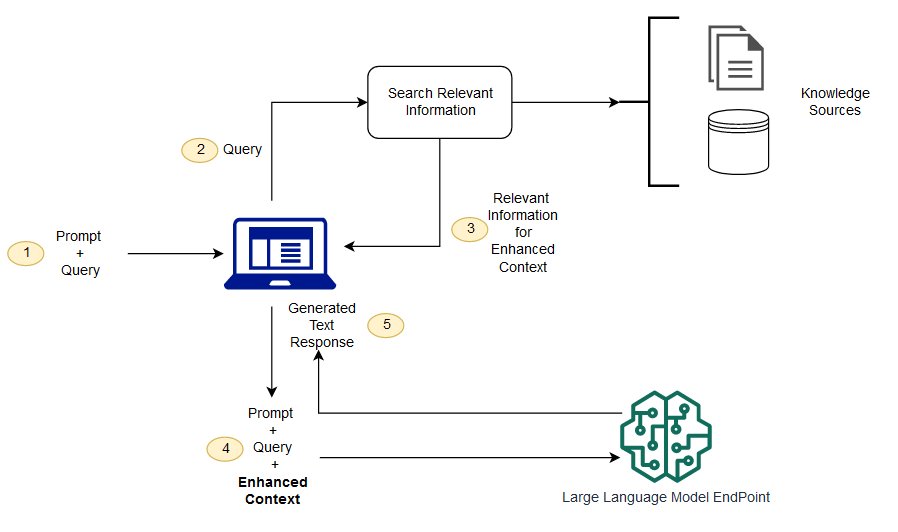
Le RAG est une façon de résoudre certains de ces défis. Il redirige le LLM pour récupérer des informations pertinentes à partir de sources de connaissances autorisées et prédéterminées. Les organisations ont plus de contrôle sur la sortie de texte générée, et les utilisateurs peuvent en apprendre davantage sur la façon dont LLM génère des réponses.
Le processus de LLM
(je ne comprends pas) quelle est la différence entre la génération d'amélioration de récupération et la recherche sémantique?
La recherche sémantique peut améliorer les résultats RAG pour les organisations qui souhaitent ajouter un grand nombre de sources de connaissances externes à leurs applications LLM. Les entreprises modernes stockent une grande quantité d'informations dans une variété de systèmes, tels que des manuels, des FAQ, des rapports de recherche, des guides de service à la clientèle et des dépôts de documents de ressources humaines. La récupération contextuelle est difficile à grande échelle et dégrade donc la qualité de la production générée.
Technologie de recherche sémantique: vous pouvez numériser de grandes bases de données contenant différentes informations et récupérer des données plus précisément. Par exemple, ils peuvent répondre à des questions telles que * « combien avez-vous dépensé en entretien mécanique l'année dernière? » Questions telles que * en mappant la question au document pertinent et en renvoyant du texte spécifique au lieu des résultats de recherche. Les développeurs peuvent ensuite utiliser cette réponse pour fournir plus de contexte pour LLM.
Les solutions de recherche traditionnelles ou par mot-clé dans RAG produisent des résultats limités pour les tâches à forte intensité de connaissances. Les développeurs doivent également faire face à l'intégration de mots, à la fragmentation des documents et à d'autres problèmes complexes lors de la préparation manuelle des données. En revanche, la technologie de recherche sémantique peut faire tout le travail pour lequel la base de connaissances est préparée, de sorte que les développeurs n'ont pas à le faire. Ils génèrent également des paragraphes sémantiquement liés et des mots de balisage triés par pertinence pour maximiser la qualité de la charge utile de chiffon.
Trois composants principaux du RAG
Le modèle de génération améliorée de récupération est principalement composé de trois composantes principales:
- Retriever: responsable de la récupération des informations pertinentes provenant de sources externes de connaissances.
- Trieur (ranker): évalue et priorise les résultats de la recherche.
- Générateur: utilisez les résultats de récupération et de tri, combinés à l'entrée de l'utilisateur, pour générer la réponse finale ou le contenu.
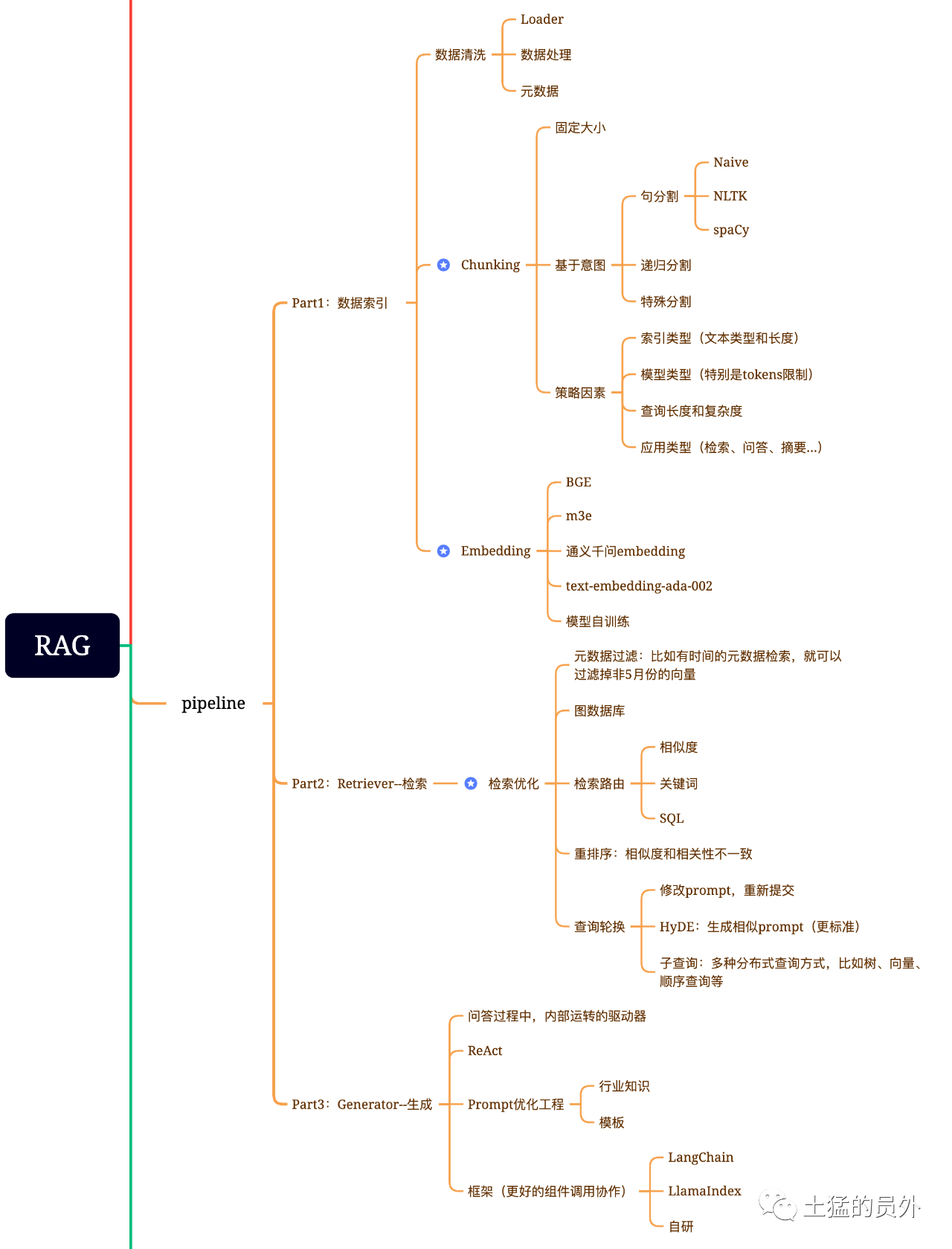
Carte du cerveau du chiffon
Cette photo est très détaillée!
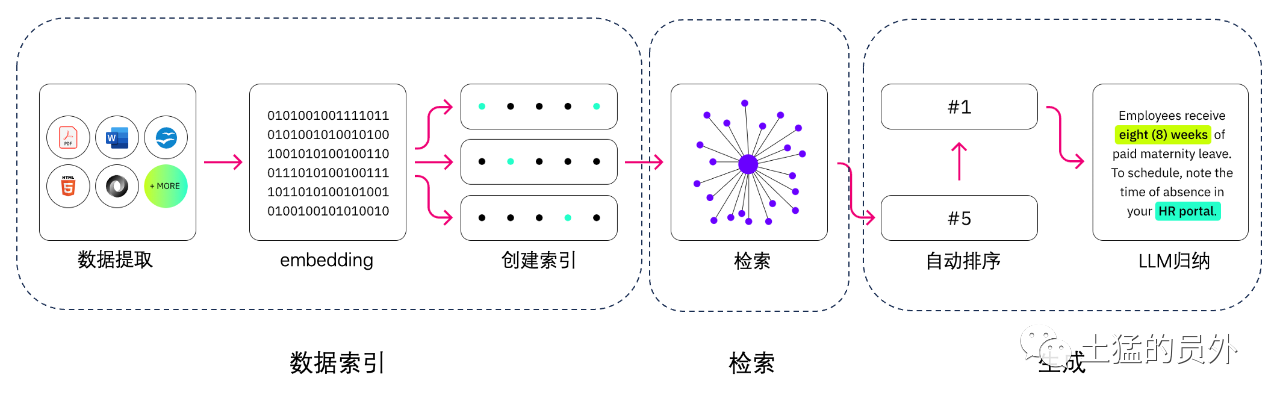
Indexation des données
-* * extraction de données * *
Nettoyage de données: y compris le chargeur de données, l'extraction de PDF, Word, markdown, base de données et API, etc. -traitement des données: y compris le traitement des formats de données, l'élimination des contenus non identifiables, la compression et le formatage, etc. Extraction de métadonnées: il est essentiel d'extraire le nom du fichier, l'heure, le titre du chapitre, l'image alt et d'autres informations.
Outils pour l'extraction de données
-UnstructuredIO (utilisé) LlamaParse (utilisé) Google Document AI -AWS Textract -pdf2image + pytesseract
Recherche
L'optimisation de la récupération est généralement divisée en cinq parties:
-* * filtrage des métadonnées * : lorsque nous divisons l'index en plusieurs morceaux, l'efficacité de la récupération sera un problème. à ce stade, si les métadonnées peuvent être filtrées en premier, l'efficacité et la pertinence seront grandement améliorées. Par exemple, nous demandons: « Aidez-moi à régler tous les contrats dans le département XX en mai de cette année, qui comprennent l'achat d'équipement XX? » . à l'heure actuelle, s'il y a des métadonnées, nous pouvons rechercher les données pertinentes de " * XX Département + mai 2023 * *", et la quantité de récupération peut devenir 1 / 10000 de la situation globale à la fois.
-* * extraction de relation graphique * *: si vous pouvez transformer de nombreuses entités en nœud et la relation entre elles en relation, vous pouvez utiliser la relation entre la connaissance pour donner des réponses plus précises. En particulier pour certains problèmes multi-hop, l'utilisation de graphique index de données rendra la récupération plus pertinente.
-* * technologie de récupération * *: quelques méthodes de prétraitement sont mentionnées ci-dessus, et les principales méthodes de récupération sont les suivantes:
-
- 相似度检索:前面我已经写过那篇文章《大模型应用中大部分人真正需要去关心的核心——Embedding》中有提到六种相似度算法,包括欧氏距离、曼哈顿距离、余弦等,后面我还会再专门写一篇这方面的文章,可以关注我,yeah; -* * recherche par mot-clé * : c'est une méthode de recherche très traditionnelle, mais parfois elle est aussi très importante. Le filtrage des métadonnées que nous venons de mentionner est un type, et un autre est de faire un résumé de Chunk d'abord, puis de trouver le morceau pertinent possible grâce à la récupération de mots clés pour augmenter l'efficacité de la récupération. Claude.ai aurait fait la même chose. - * SQL Search * *: c'est plus traditionnel, mais pour certaines applications d'entreprise localisées, la requête SQL est une étape essentielle. Par exemple, les données de vente que j'ai mentionnées précédemment doivent d'abord être recherchées par SQL. -Autres: il y a encore beaucoup de techniques de récupération, alors parlons-en plus tard.
-* * Rerank * *: dans de nombreux cas, nos résultats de recherche ne sont pas idéaux car il y a un grand nombre de morceaux dans le système, et les dimensions que nous récupérons ne sont pas nécessairement optimales, et les résultats d'une recherche peuvent ne pas être aussi idéaux en termes de pertinence. à l'heure actuelle, nous devons avoir des stratégies pour réorganiser les résultats de la récupération, comme l'utilisation de planB pour réorganiser, ou pour ajuster la pertinence combinée, la correspondance et d'autres facteurs pour obtenir un classement qui est plus conforme à notre scénario d'affaires. Parce qu'après cette étape, nous enverrons le résultat à LLM pour le traitement final, donc le résultat de cette partie est très important. Il y aura également un juge interne pour examiner la corrélation et déclencher la réorganisation.
-* * rotation de requête * *: ceci est un moyen de requête et de récupération, et il y a généralement plusieurs façons:
-* * Sous-requête: * * vous pouvez utiliser diverses stratégies de requête dans différents scénarios. Par exemple, vous pouvez utiliser la requête fournie par des frameworks tels que LlamaIndex, Tree Query (à partir des nœuds Leaf, étape par étape, fusion), la requête vectorielle, ou les morceaux de requête séquentiels les plus primitifs, etc. * *; * *
-* * Hyde: * * ceci est un moyen de copier des tâches pour générer des modèles d'invite similaires ou plus standard. Je ne sais pas.
Reclassement
La plupart des bases de données vectorielles sacrifient un certain degré de précision pour l'efficacité informatique. Cela rend les résultats de récupération aléatoires, et l'original retourné top K n'est pas nécessairement le plus pertinent.
使用BAAI/bge-reranker-base、BAAI/bge-reranker-large等开源模型来完成Re-Rank操作。
Et la base de bce-reranker de NetEase soutient la Chine, la Grande-Bretagne, le Japon et la Corée du Sud.
Rappel / récupération mixte
Requête bidirectionnelle & # 160;:
-récupération sémantique (recherche vectorielle) / * * rappel de base de données vectorielles * * -recherche par mot-clé (recherche par mot-clé) / rappel de recherche par mot-clé
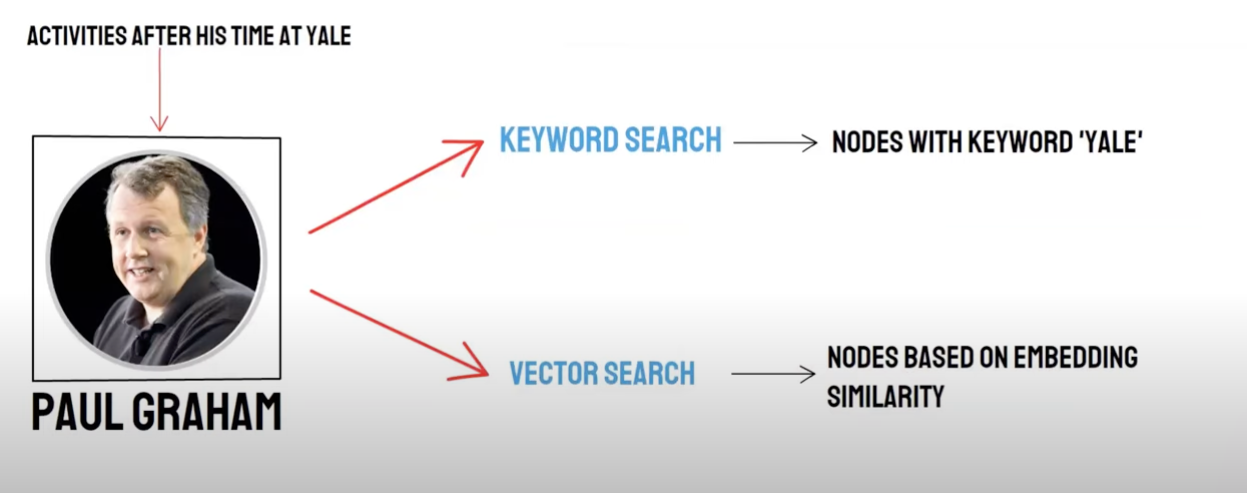
Le rappel de base de données vectorielles et le rappel de récupération de mots clés ont leurs propres avantages et inconvénients, de sorte que la combinaison des résultats de rappel des deux peut améliorer la précision et l'efficacité globales de la récupération. L'algorithme de fusion de tri réciproque (Reciprocal Rank fusion, RRF) calcule le score total après fusion par sommation pondérée du classement de chaque document selon différentes méthodes de rappel.
Lorsque vous choisissez d'utiliser le rappel de mots clés, c'est-à-dire * * récupération de mots clés * * sélectionner * * mot clé ensembled * *, PAI utilisera l'algorithme RRF par défaut pour multiplexer les résultats de rappel de base de données vectorielles et de récupération de mots clés.
Générer
Le cadre a Langchain et LlamaIndex
Le schéma de la technologie de comptage et de récolte
Cadre
La difficulté est: qu'est-ce que le text-to-sql?
Répartition du texte & # 160;:
Fractionnement du texte: le document est divisé en blocs plus petits pour faciliter l'intégration ultérieure du texte, puis faciliter la récupération ultérieure du document.
Idéalement: mettre des morceaux de texte sémantiquement liés ensemble dans l'ordre.
-
- méthode de fractionnement * *
-selon la règle: (le moyen le plus simple) de diviser le document par phrase. Le document est divisé selon les symboles de terminaison communs en chinois et en anglais, tels que le briseur de caractères simple, les ellipses chinoises et anglaises, les guillemets doubles et ainsi de suite. Basé sur la sémantique: (1) Tout d'abord, le document est divisé en blocs de documents au niveau des sentences basés sur des règles. 2. Ensuite, utilisez le modèle pour intégrer les blocs de documents basés sur la sémantique, et enfin obtenir les blocs de documents basés sur la sémantique.
-
- Modèle de partage de texte basé sur la sémantique * *
Le modèle seq _ model * *, développé par Ali Dama Institute, est basé sur la fenêtre coulissante Bert +, qui détermine la segmentation sémantique en prédisant si la phrase divisée appartient à la limite du paragraphe.
Vectorisation du texte: sélectionnez le modèle d'intégration
Modèle BBA de Zhiyuan (modèle bge-base-zh) ou choisissez dans l'exemple MTEB.
Stockage vectoriel
-Faiss: pour usage personnel
-Milvus: niveau de production
Utilisez Vector pour récupérer les points de connaissance correspondants en fonction des questions.
Haut _ k
Faiss: effectuez une recherche étendue près des résultats de recherche pour obtenir des documents similaires qui sont inférieurs à chunk _ size (généralement 500 mots)
Milvus: topk REtrieval + bge-base-zh + paragraphe similarité Aggregation Model
Idée: analysez l'idée d'une récupération étendue basée sur la récupération topk, nous constatons que c'est principalement grâce à l'expansion des segments sémantiques pour faire en sorte que le grand modèle obtienne autant d'informations utiles que possible pour améliorer l'effet de la réponse.
Le fil de la pensée:
- Tout d'abord, le document est divisé en blocs de documents au niveau des sentences basés sur des règles.
- Ensuite, utilisez le modèle pour intégrer les blocs de documents basés sur la sémantique, et enfin obtenir les blocs de documents basés sur la sémantique.
- Troisièmement, le modèle d`intégration de texte est utilisé pour les documents séquentiellement, et les documents sont agrégés à nouveau selon la similitude sémantique, ce qui équivaut à agréger les documents originaux au niveau de la phrase deux fois avec des méthodes différentes.
Créer une invite
你现在是一个智能助手了,现在需要你根据已知内容回答问题
已知内容如下:
"{context}"
通过对已知内容进行总结并且列举的方式来回答问题:"{question}",在答案中不能出现问题内容,并且不允许编造内容,并且使用简体中文回答。
如果该问题和已知内容不相关,请回答 "根据已知信息无法回答该问题" 或 "没有提供足够的相关信息"。
Générer la réponse: sélectionnez LLM
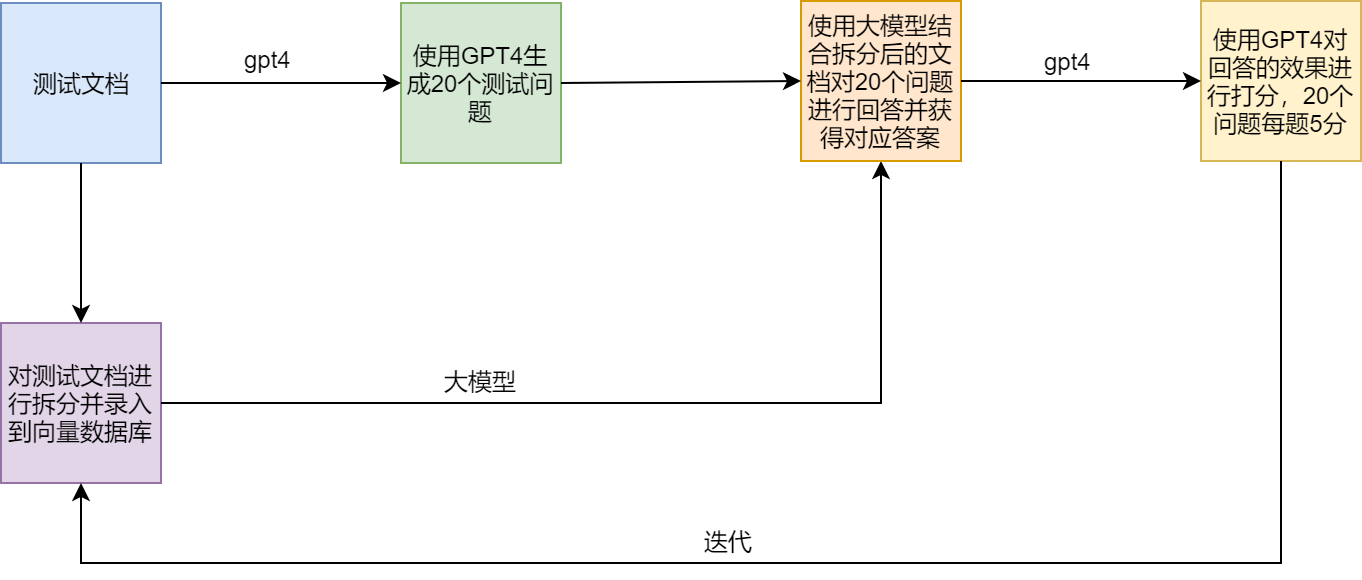
Schéma d'essai
Points douloureux et solutions de chiffon

Exemple
LamaIndex官方提供了一个范例(SEC Insights),用来展示高级查询技术