RAG:检索增强生成
Il RAG
RAG: Generazione aumentata di recupero
Stai cercando di risolvere un caso complicato:
Il ruolo di un detective è quello di raccogliere indizi, prove e documenti storici relativi al caso. Dopo che il detective ha raccolto le informazioni, il reporter ha riassunto i fatti in una storia affascinante e ha presentato una narrazione coerente.
Il problema con LLM
- Allucinazione: Fornire informazioni false senza una risposta.
- LLM utilizza informazioni obsolete, e non ha accesso alle informazioni più recenti e affidabili dopo la sua scadenza di conoscenza.
- Inoltre, la risposta fornita da LLM non si riferisce alla sua fonte, il che significa che la sua rivendicazione non può essere verificata dall'utente come accurata o pienamente fidata. Ciò evidenzia l'importanza di una verifica e di una valutazione indipendenti quando si utilizzano informazioni generate dall'intelligenza artificiale.
您可以将大型语言模型看作是一个过于热情的新员工,他拒绝随时了解时事,但总是会绝对自信地回答每一个问题。
RAG è un modo per risolvere alcune di queste sfide. Riindirizza l'LLM a recuperare le informazioni pertinenti da fonti di conoscenza autorevoli e predeterminate. Le organizzazioni hanno più controllo sull'output di testo generato, e gli utenti possono saperne di più su come LLM genera risposte.
Il processo di LLM
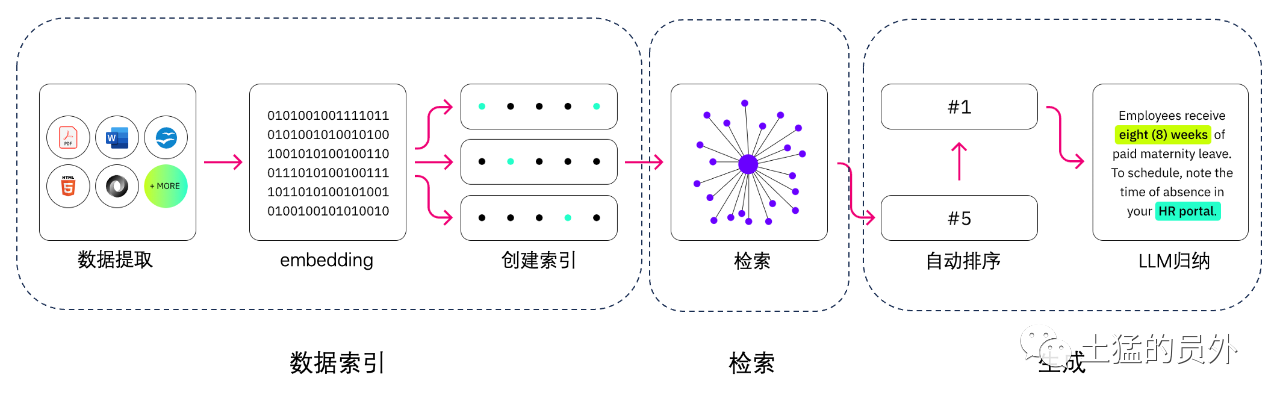
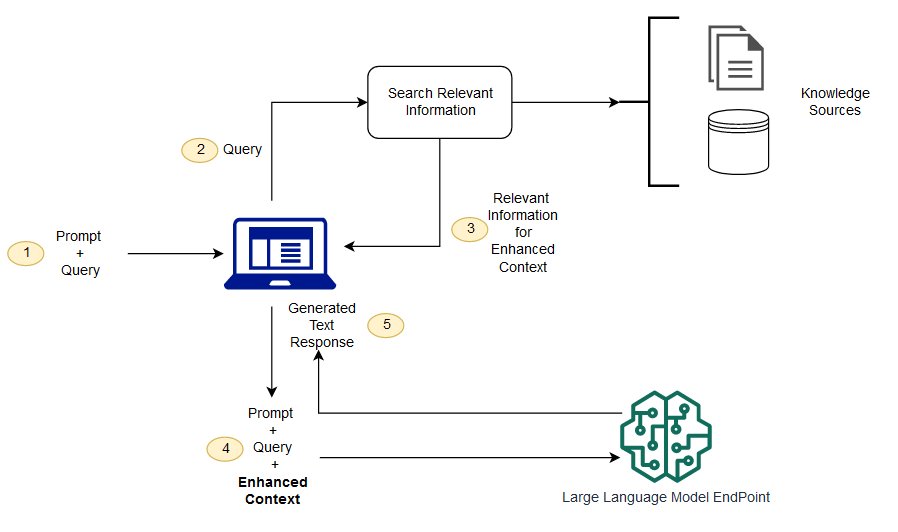
Qual e 'la differenza tra la generazione di miglioramento del recupero e la ricerca semantica?
Semantic Search può migliorare i risultati RAG per le organizzazioni che vogliono aggiungere un gran numero di fonti di conoscenza esterne alle loro applicazioni LLM. Le imprese moderne memorizzano una grande quantità di informazioni in una varietà di sistemi, come manuali, FAQ, rapporti di ricerca, guide del servizio clienti e repository di documenti sulle risorse umane. Il recupero contestuale è impegnativo in scala e quindi degrada la qualità dell'output generato.
Tecnologia di ricerca semantica: È possibile eseguire la scansione di grandi database contenenti diverse informazioni e recuperare i dati in modo più accurato. Per esempio, possono rispondere a domande come * "Quanto hai speso per la manutenzione meccanica l'anno scorso?" Domande come * mappando la domanda al documento pertinente e restituendo il testo specifico al posto dei risultati della ricerca. Gli sviluppatori possono quindi utilizzare questa risposta per fornire più contesto per LLM.
Le soluzioni di ricerca tradizionali o di parole chiave in RAG producono risultati limitati per la conoscenza - compiti intensivi. Gli sviluppatori devono anche affrontare l'incorporazione di parole, la frammentazione dei documenti e altri problemi complessi durante la preparazione dei dati manualmente. Al contrario, la tecnologia di ricerca semantica può fare tutto il lavoro per cui la base di conoscenza è preparata, in modo che gli sviluppatori non devono farlo. Essi generano anche paragrafi semanticamente correlati e parole di markup ordinate per rilevanza per massimizzare la qualità del carico utile RAG.
Tre componenti principali di RAG
Il modello di generazione potenziata di recupero è composto principalmente da tre componenti principali:
- Recupero: responsabile del recupero di informazioni rilevanti da fonti esterne di conoscenza.
- Sorter (Ranker): valuta e dà priorità ai risultati della ricerca.
- Generatore: Utilizzare i risultati di recupero e selezione, combinati con l'ingresso dell'utente, per generare la risposta finale o il contenuto.
Mappa del cervello di RAG
Questa immagine è molto dettagliata!
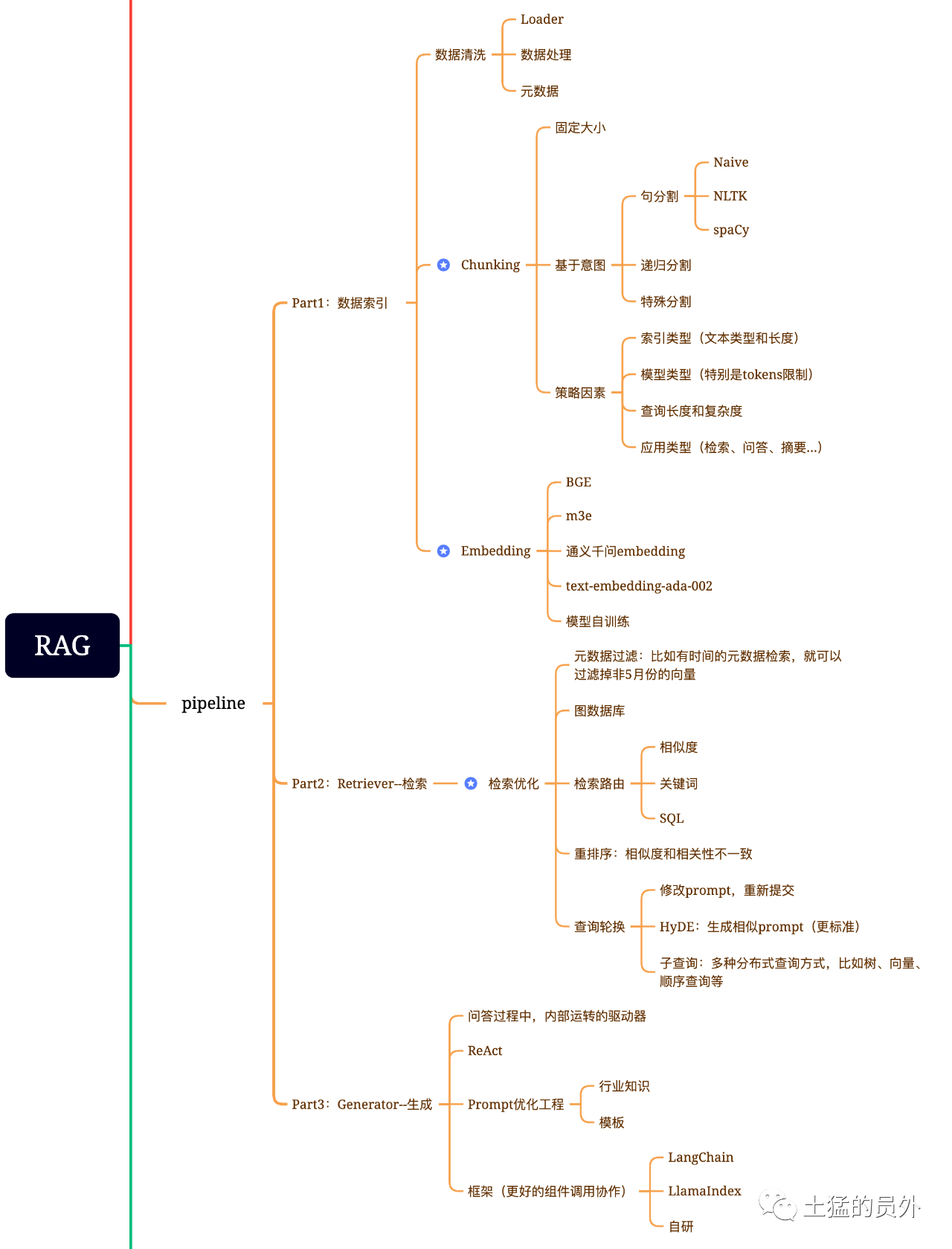
Indicizzazione dei dati
-
-
- Estrazione dati * *
-
Pulizia dei dati: incluso Data Loader, estrazione di PDF, Word, markdown, database e API, ecc.
- trattamento dei dati: compreso il trattamento del formato dei dati, l'eliminazione dei contenuti non identificabili, la compressione e la formattazione, ecc.
- Estrazione di metadati: è fondamentale estrarre il nome del file, l'ora, il titolo del capitolo, l'immagine alt e altre informazioni.
Strumenti per l'estrazione dei dati
- Strutturato io (utilizzato)
- LlamaParse (usato)
- Google documento AI
- estratto di AWS
- pdf2image + pytesseract
Pesquisar
L'ottimizzazione del recupero è generalmente suddivisa nelle seguenti cinque parti:
-
-
- Filtering dei metadati * : Quando dividiamo l'indice in molti pezzi, l'efficienza di recupero sarà un problema. In questo momento, se i metadati possono essere filtrati prima, l'efficienza e la rilevanza saranno notevolmente migliorate. Per esempio, chiediamo: "Aiutatemi a risolvere tutti i contratti del reparto XX nel maggio di quest'anno, che includono l'acquisto di attrezzature XX?" . In questo momento, se ci sono metadati, possiamo cercare i dati rilevanti di " * XX Dipartimento + Maggio 2023 * *", e la quantità di recupero può diventare 1 / 10000 della situazione generale in una sola volta.
-
-
-
- Graph Relation Retrieval * *: Se è possibile trasformare molte entità in nodo e la relazione tra loro in relazione, è possibile utilizzare la relazione tra la conoscenza per fare risposte più accurate. Soprattutto per alcuni problemi multi-hop, l'uso di indice di dati grafico renderà il recupero più rilevante.
-
-
-
- Tecnologia retrievale * *: di cui sopra sono alcuni metodi di pre-elaborazione, e i principali metodi di recupero sono i seguenti:
-
-
- 相似度检索:前面我已经写过那篇文章《大模型应用中大部分人真正需要去关心的核心——Embedding》中有提到六种相似度算法,包括欧氏距离、曼哈顿距离、余弦等,后面我还会再专门写一篇这方面的文章,可以关注我,yeah;
-
-
- Keyword Search * *: Questo è un metodo di ricerca molto tradizionale, ma a volte è anche molto importante. Il filtraggio dei metadati di cui abbiamo parlato poco fa è di un tipo, e un altro è quello di fare un riassunto di Chunk prima, e poi trovare il possibile pezzo rilevante attraverso il recupero delle parole chiave per aumentare l'efficienza di recupero. Si dice che Claude.ai abbia fatto lo stesso.
-
-
-
- SQL Search * *: Questo è più tradizionale, ma per alcune applicazioni aziendali localizzate, SQL query è un passo essenziale. Ad esempio, i dati di vendita che ho citato in precedenza devono essere cercati da SQL prima.
-
-
Altro: Ci sono ancora molte tecniche di recupero, quindi parliamone più tardi.
-
-
- Rerank * *: In molti casi, i nostri risultati di recupero non sono ideali perché ci sono un gran numero di pezzi nel sistema, e le dimensioni che recuperiamo non sono necessariamente ottimali, e i risultati di una ricerca possono non essere così ideali in termini di rilevanza. In questo momento, abbiamo bisogno di avere alcune strategie per riordinare i risultati di recupero, come l'utilizzo di planb per riordinare, o per regolare la rilevanza combinata, l'abbinamento e altri fattori per ottenere una classifica che è più in linea con il nostro scenario di business. Perché dopo questo passo, invieremo il risultato a LLM per l'elaborazione finale, quindi il risultato di questa parte è molto importante. Ci sarà anche un giudice interno per rivedere la correlazione e innescare il riordino.
-
-
-
- Rotazione di query * *: Questo è un modo di query e recupero, e di solito ci sono diversi modi:
-
-
-
- Sub - Query: * * È possibile utilizzare varie strategie di query in diversi scenari. Ad esempio, è possibile utilizzare il questore fornito da quadri come LlamaIndex, query albero (da nodi foglia, query passo dopo passo, fusione), query vettoriali, o i pezzi di query sequenziali più primitivi, ecc * *; * *
-
-
-
- Hyde: * * Questo è un modo per copiare i lavori per generare modelli di prompt simili o più standard. * *
-
Re - Rank
La maggior parte dei database vettoriali sacrificano un certo grado di precisione per l'efficienza computazionale. Questo rende i risultati di recupero casuali, e l'originale restituito TOP K non è necessariamente il più rilevante.
使用BAAI/bge-reranker-base、BAAI/bge-reranker-large等开源模型来完成Re-Rank操作。
E la base BCE - reranker - di NetEase sostiene Cina, Gran Bretagna, Giappone e Corea del Sud.
Recall / recupero misto
Due - domanda di modo:
- Retrieval semantico (Vector Search) / * Richiamamento del database vettoriale * *
- Ricerca di parole chiave (ricerca di parole chiave) / richiamo di ricerca di parole chiave
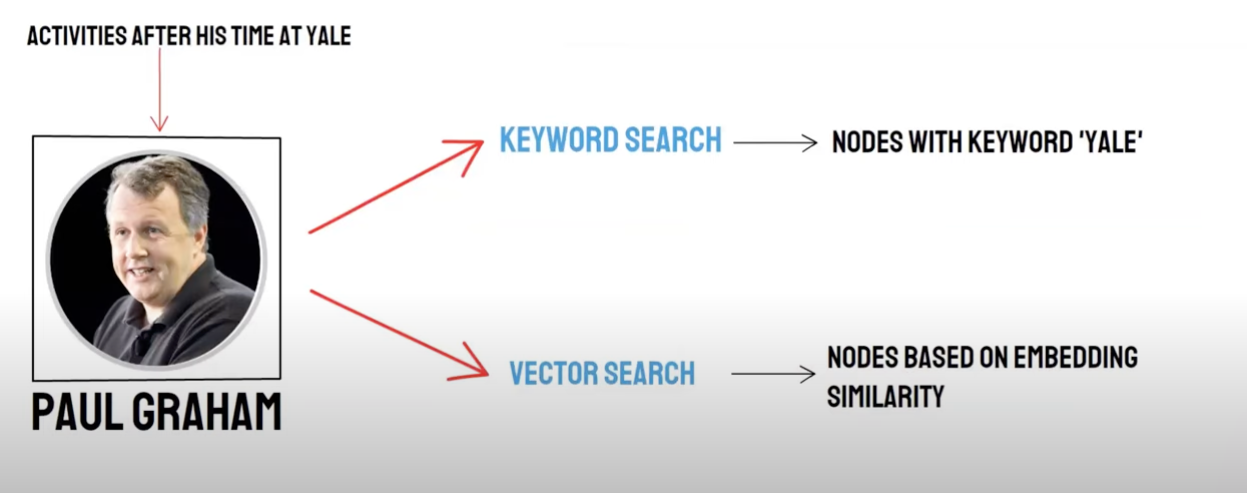
Vector database recall e keyword retrieval recall hanno i propri vantaggi e svantaggi, in modo da combinare i risultati di richiamo dei due possono migliorare la precisione e l'efficienza complessiva di recupero. L'algoritmo di fusione di tipo reciproco (Reciprocal Rank Fusion, RRF) calcola il punteggio totale dopo la fusione mediante sommatoria ponderata della graduatoria di ciascun documento in diversi metodi di richiamo.
Quando si sceglie di utilizzare Keyword Retrieval Recall, cioè, * * Parola chiave Retrieval * * selezionare * * Parola chiave ensembled * *, PAI userà l'algoritmo RRF di default per multiplex i risultati di richiamo del database vettoriale e il recupero delle parole chiave.
Genera
Il quadro ha Langchain e LlamaIndex
Lo schema della tecnologia di conteggio e raccolta
Telaio
La difficoltà è: Che cosa è il testo - a - SQL?
Spalato del testo:
Spaccatura del testo: Il documento è suddiviso in blocchi più piccoli per facilitare l'incorporazione del testo successivo, e quindi facilitare il successivo recupero dei documenti.
Idealmente: mettere insieme pezzi di testo semanticamente correlati in ordine.
-
- Metodo di divisione * *
- Secondo la regola: (il modo più semplice) per dividere il documento per frase. Il documento è diviso in base ai simboli di terminazione comuni in cinese e inglese, come singolo carattere breaker, ellissi cinese e inglese, doppie virgolette e così via.
- Sulla base della semantica:
- In primo luogo, il documento è suddiviso in blocchi di documenti di livello di frase basati su regole.
- Quindi utilizzare il modello per integrare i blocchi di documento in base alla semantica, e infine ottenere i blocchi di documento semantici - basati.
-
- Semantic - modello di divisione del testo basato * *
Il modello SEQ _ MODEL * *, sviluppato dall'Istituto Ali Dama, si basa sulla finestra scorrevole Bert +, che determina la segmentazione semantica prevedendo se la frase frazionata appartiene al contorno del paragrafo.
Vectorizzazione del testo: Selezionare il modello di embedding
Modello BBA di Zhiyuan (BGE - base - modello ZH) o scegliere tra l'esempio MTEB.
Stoccaggio vettoriale
-
Faiss: per uso personale
-
Milvus: livello di produzione
Utilizzare Vector per recuperare i punti di conoscenza corrispondenti in base alle domande.
Top _ k
Faiss: Fai una ricerca estesa vicino ai risultati della ricerca per ottenere documenti simili che sono inferiori a Chunk _ size (di solito 500 parole)
Milvus: TOPK Retrieval + BGE - BASE - ZH + Paragrafo Similary Aggregation Model
IDEA: Analizzare l'idea di recupero esteso basata sul recupero TOPK, scopriamo che è principalmente attraverso l'espansione di segmenti semantici per rendere il grande modello ottenere il maggior numero possibile di informazioni utili per migliorare l'effetto della risposta.
Treno del pensiero:
- In primo luogo, il documento è suddiviso in blocchi di documenti di livello di frase basati su regole.
- Quindi utilizzare il modello per integrare i blocchi di documento in base alla semantica, e infine ottenere i blocchi di documento semantici - basati.
- In terzo luogo, il modello di incorporazione del testo è utilizzato per i documenti in sequenza, e i documenti sono nuovamente aggregati in base alla somiglianza semantica, che equivale ad aggregare la frase originale - documenti di livello due volte con metodi diversi.
Costruisci prompt
你现在是一个智能助手了,现在需要你根据已知内容回答问题
已知内容如下:
"{context}"
通过对已知内容进行总结并且列举的方式来回答问题:"{question}",在答案中不能出现问题内容,并且不允许编造内容,并且使用简体中文回答。
如果该问题和已知内容不相关,请回答 "根据已知信息无法回答该问题" 或 "没有提供足够的相关信息"。
Genera risposta: selezionare LLM
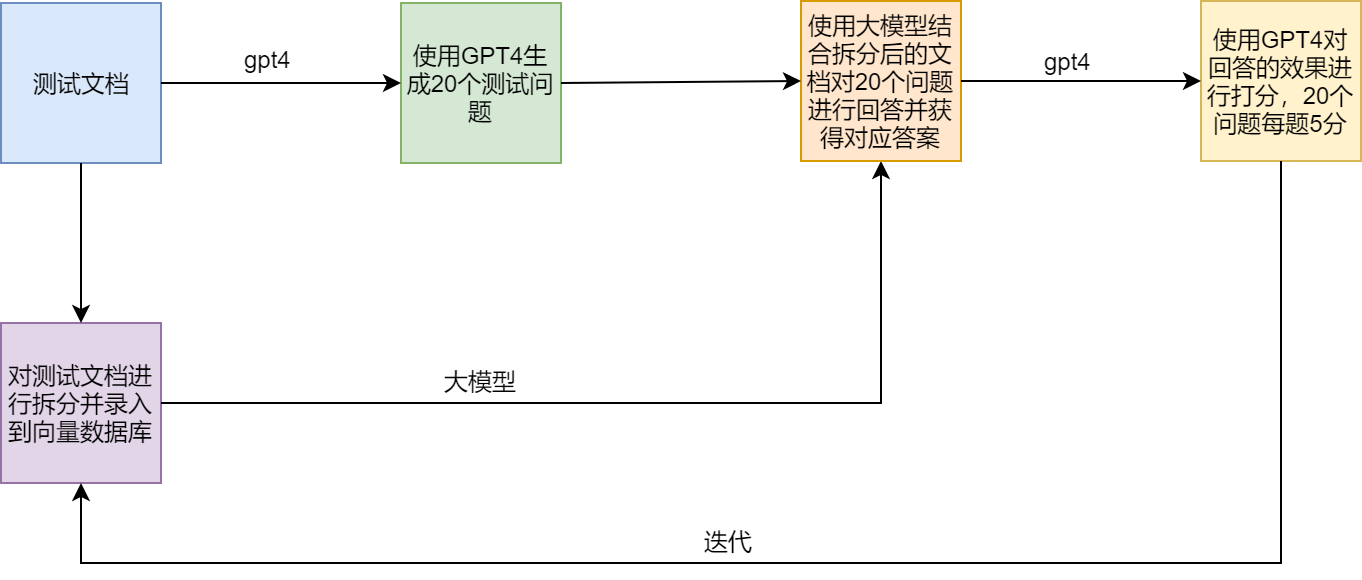
Schema di prova
Punti di dolore e Soluzioni di straccio

Esempio
LamaIndex官方提供了一个范例(SEC Insights),用来展示高级查询技术