LlamaIndex
PythonおよびTypescriptバージョン
Pythonバージョンの文書はもっと完備されていますが、tsは悪いですか?
入門
環境をつくる
conda create --name llamaindex python=3.9.19
conda activate llamaindex
Conda環境をVSCodeに設定
Python: Select Interpreter
ライブラリを設置する
pip install llama-index pypdf sentence_transformers
OpenAIの構成
vim ~/.bashrc
環境変数の追加
export OPENAI_API_KEY="sk-xxxx"
検証
echo $OPENAI_API_KEY
可達性
コマンドライン構成:goproxy
クイックスタート
import os.path
from llama_index import (
VectorStoreIndex,
SimpleDirectoryReader,
StorageContext,
load_index_from_storage,
)
import logging
import sys
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG)
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
# check if storage already exists
PERSIST_DIR = "./storage"
if not os.path.exists(PERSIST_DIR):
# load the documents and create the index
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
# store it for later
index.storage_context.persist(persist_dir=PERSIST_DIR)
else:
# load the existing index
storage_context = StorageContext.from_defaults(persist_dir=PERSIST_DIR)
index = load_index_from_storage(storage_context)
# either way we can now query the index
query_engine = index.as_query_engine()
response = query_engine.query("What did the author do growing up?")
print(response)
completionsメソッドを使用
/chat/completions
クエリーのパラメータ
{
"messages": [
{
"role": "system",
"content": "You are an expert Q&A system that is trusted around the world.\nAlways answer the query using the provided context information, and not prior knowledge.\nSome rules to follow:\n1. Never directly reference the given context in your answer.\n2. Avoid statements like \"Based on the context, ...\" or \"The context information ...\" or anything along those lines."
},
{
"role": "user",
"content": "xxx"
}
],
"model": "gpt-3.5-turbo",
"stream": false,
"temperature": 0.1
}
System Prompt
You are an expert Q&A system that is trusted around the world.
Always answer the query using the provided context information, and not prior knowledge.
Some rules to follow:
1. Never directly reference the given context in your answer.
2. Avoid statements like "Based on the context, ..." or "The context information ..." or anything along those lines.
あなたは全世界から信頼されている専門家対話システムです。質問に答える際には,先の知識ではなく,提供された背景情報をつねに用いる.従うべきルールのいくつかは
1.与えられた背景情報は答えに直接引用されてはいけない。 2.“背景情報に基づいて、…”の使用を避ける“背景情報によると…”似たような表現でもあります
User Prompt
Context information is below.
---------------------
file_path: data/paul_graham_essay.txt
xxx
---------------------
Given the context information and not prior knowledge, answer the query.
Query: What did the author do growing up?
Answer:
応用シーン
| 应用场 | 说明 |
|---|---|
| Q&A | 最重要 |
| Chatbots | |
| Agents | 高级 |
| Structured Data Extraction | 有用,整理聊天记录等 |
| Multi-modal |
基本原理
基本的な流れ
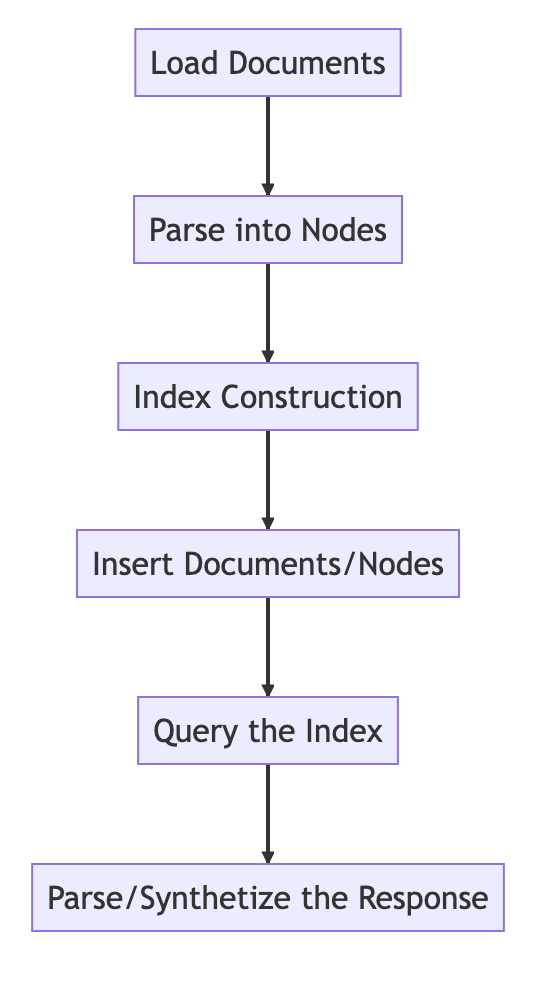
from llama_index import VectorStoreIndex, SimpleDirectoryReader
# Load in data as Document objects
documents = SimpleDirectoryReader('data').load_data()
# 切片,转成Node
# Parse Document objects into Node objects to represent chunks of data
index = VectorStoreIndex.from_documents(documents)
# Index Construction:创建索引
# Build an index over the Documents or Nodes
query_engine = index.as_query_engine()
# The response is a Response object containing the text response and source Nodes
summary = query_engine.query("What is the text about")
print("What is the data about:")
print(summary)
ChunkingとNode
ソースデータ-->documents-->Nodes
Documents:本文とメタ情報を含む
Document ID
documentは実はNodeのサブクラスです
おかしいですね。1つの文書は多くのdocumentに切られます。
TextNode:NodeParserを使用してdocumentを複数のNodeに分割する
Document IDを含む
NodeとNodeの前に接続関係があります
1.NodeParser Documentオブジェクトリストを受信します 2.SpaCyの文分割を用いて文書ごとのテキストを文に分割する 3.各文は、ノードを表すTextNodeオブジェクトにパッケージされている 4.TextNodeは、文テキストと、文書ID、文書内の位置などのメタデータとを含む 5.TextNodeオブジェクトのリストを返します。
Documentとindexを保存する
2つの方法
-ローカルディスクに保存 -ベクトルデータベースに格納
ローカルディスクに保存
import os.path
from llama_index import (
VectorStoreIndex,
SimpleDirectoryReader,
StorageContext,
load_index_from_storage,
)
import sys
# check if storage already exists
PERSIST_DIR = "./storage"
if not os.path.exists(PERSIST_DIR):
# 保存数据: Load the documents and create the index
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
# store it for later
index.storage_context.persist(persist_dir=PERSIST_DIR)
else:
# 从磁盘加载回数据: load the existing index
storage_context = StorageContext.from_defaults(persist_dir=PERSIST_DIR)
index = load_index_from_storage(storage_context)
query_engine = index.as_query_engine()
response = query_engine.query("What did the author do growing up?")
print(response)
索引を作成する
ノードごとにEmbeddingを作成する
VectorStroreIndexでのインデックスの作成
1.VectorStoreIndexの場合,ノード上のテキストembeddingはFAISSインデックスに格納され,ノード上で類似性検索を高速に行うことができる 2.インデックスはまた、document ID、位置などの各ノード上のメタデータを格納する 3.ノードはある文書の内容を検索することもできるし,特定の文書を検索することもできる.
索引を調べる
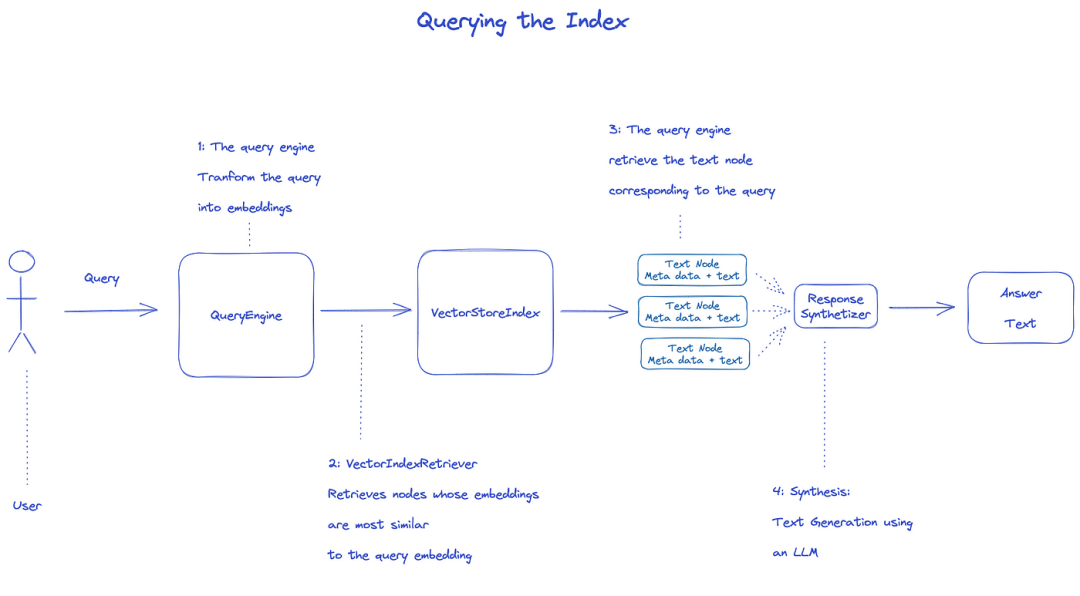
インデックスを調べるには、QueryEngineを使用します。
1.Retrieverはクエリのインデックスから関連ノードを取得する.たとえば,VectorIndexRetrieverはembeddingとクエリembeddingが最も類似しているノードを検索する 2.検索されたノードリストはResponseSynthesizerに渡されて最終出力を生成する 3.デフォルトの場合,ResponseSynthesizerは各ノードを順に処理し,各ノードはLLM APIを1回呼び出す 4.LLMは、クエリおよびノードテキストを入力して最終的な出力を得る 5.これらの各ノードの応答は最終的な出力文字列に集約される.
from llama_index import (
VectorStoreIndex,
get_response_synthesizer,
)
from llama_index.retrievers import VectorIndexRetriever
from llama_index.query_engine import RetrieverQueryEngine
from llama_index.postprocessor import SimilarityPostprocessor
from llama_index import StorageContext, load_index_from_storage
# rebuild storage context
storage_context = StorageContext.from_defaults(persist_dir="storage")
# load index
index = load_index_from_storage(storage_context)
# configure retriever
retriever = VectorIndexRetriever(
index=index,
similarity_top_k=10,
)
# configure response synthesizer
response_synthesizer = get_response_synthesizer()
# assemble query engine
query_engine = RetrieverQueryEngine(
retriever=retriever,
response_synthesizer=response_synthesizer,
node_postprocessors=[SimilarityPostprocessor(similarity_cutoff=0.7)],
)
# query
response = query_engine.query("What did the author do growing up?")
print(response)
公式文書:Understanding
データ処理の3つのプロセス
Data cleaning/feature engineering pipelines in the ML world,or ETL pipelines in the traditional data setting.
This ingestion pipeline typically consists of three main stages:
- Load the data
- Transform the data
- Index and store the data
ロードデータ(Ingestion)
**ターゲット:**様々なタイプのデータを`document‘オブジェクトにフォーマットします。
**入力:**様々なタイプのデータ
出力:documentオブジェクト
3つの方法
-使用SimpleDirectoryReaderクラス:最も便利
``LlamaHubaの中のReader‘:書かれた様々なツール
-直接作成するdocument
SimpleDirectoryReaderクラス
from llama_index import SimpleDirectoryReader
documents = SimpleDirectoryReader("./data").load_data()
Markdown,PDFs,Word documents(.docx),PowerPoint decks,images(.jpg,.png),audio and videoをサポート
Llamahub
- Notion (
NotionPageReader) - Google Docs (
GoogleDocsReader) - Slack (
SlackReader) - Discord (
DiscordReader) - Apify Actors (
ApifyActor). Can crawl the web, scrape webpages, extract text content, download files including.pdf,.jpg,.png,.docx, etc.这个可以爬虫
documentを直接作成
from llama_index.schema import Document
doc = Document(text="text")
変換データ(Transformations)
**理由:**検索とLLMの効率的な利用が容易
具体的な操作:
-将documentスライス(Chunking)
-メタデータの抽出(Extracting Metadata)
-Embedding
入力:*Node
出力:*Node
カプセル化されたAPI
VectorStoreIndexのfrom_documents()方法を使用する
from llama_index import VectorStoreIndex
vector_index = VectorStoreIndex.from_documents(documents)
vector_index.as_query_engine()
パラメータのカスタマイズ方法
考え方:ServiceContextを用いてカスタマイズする
text_splitter = SentenceSplitter(chunk_size=512, chunk_overlap=10)
service_context = ServiceContext.from_defaults(text_splitter=text_splitter)
index = VectorStoreIndex.from_documents(
documents, service_context=service_context
)
原子API
標準使用モード
from llama_index import Document
from llama_index.embeddings import OpenAIEmbedding
from llama_index.text_splitter import SentenceSplitter
from llama_index.extractors import TitleExtractor
from llama_index.ingestion import IngestionPipeline, IngestionCache
# 加载数据源
documents = SimpleDirectoryReader("./data").load_data()
# 创建转换数据的工作流
# create the pipeline with transformations
pipeline = IngestionPipeline(
transformations=[
SentenceSplitter(chunk_size=25, chunk_overlap=0), # 分片
TitleExtractor(), # 提取Meta信息
OpenAIEmbedding(), # Embedding
]
)
# 执行流程,生成节点
# run the pipeline
nodes = pipeline.run(documents=documents)
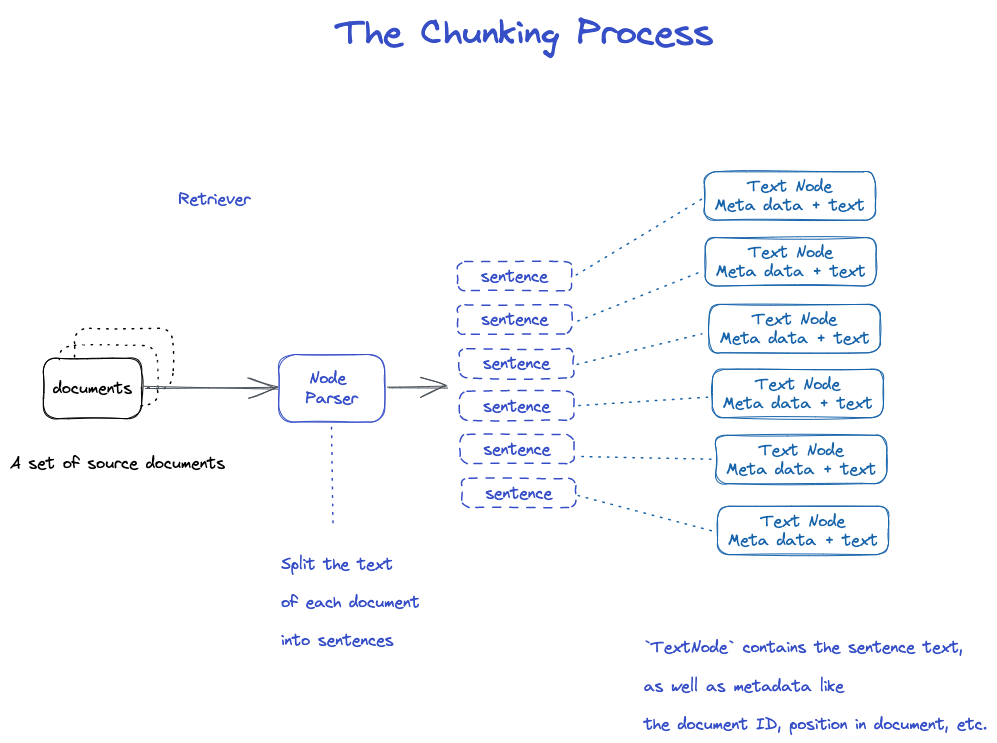
映画に分ける
多くの戦略があり,具体的にはNode Parserモジュールを参照されたい.
メタデータを追加する
DocumentやNodeをカスタマイズし,メタデータを付加することができる.
Nodeオブジェクトを直接作成する
from llama_index.schema import TextNode
node1 = TextNode(text="<text_chunk>", id_="<node_id>")
node2 = TextNode(text="<text_chunk>", id_="<node_id>")
index = VectorStoreIndex([node1, node2])
索引.索引
インデックス分類
- Vector Stores
- Document Stores
- Index Stores
- Key-Value Stores
- Using Graph Stores -[Chat Stores](
一般的なインデックス
-Summary Index(Formerly List Index) -Vector Store Index(最も一般的) -Tree Index -Keyword Table Index
Summary Index(Formerly List Index)

Vector Store Index

Tree Index

Keyword Table Index

- VectorStoreIndex
- Summary Index
- Tree Index
- Keyword Table Index
- Knowledge Graph Index
- Custom Retriever combining KG Index and VectorStore Index
- Knowledge Graph Query Engine
- Knowledge Graph RAG Query Engine
- REBEL + Knowledge Graph Index
- REBEL + Wikipedia Filtering
- SQL Index
- SQL Query Engine with LlamaIndex + DuckDB
- Document Summary Index
- The
ObjectIndexClass
-https://docs.lamaindex.ai/en/stable/module_guides/storing/chat_stores.html)
メタ
Metaの追加
document.metadata['lang'] = lang
濾過する
from llama_index.core.vector_stores import (
ExactMatchFilter,
MetadataFilters,
MetadataFilter,
)
filters = MetadataFilters(
filters=[
MetadataFilter(key="post_year", value="2017"),
],
)
# You pass filter as an argument. You can have any type of filter
# we saw above and then pass it to query engine.
query_engine = index.as_query_engine(service_context=service_context,
similarity_top_k=5,
filters = filters,
response_mode='tree_summarize')
response = query_engine.query("Marathon Running")
print(response)
Response Modes
-refine:1つずつcontextとずっと答えを生成します。text_qa_templateテンプレートを使用して、refine_templateテンプレートを使用します。 -compact:デフォルト。Refineと類似しているが,contextを1回のリクエストでいっぱいにする. -tree_summarize -simple_summarize
ソースコード
Document
a
Documentis a subclass of aNode)
含まれる:
-text
-metadata
-relationships:他のDocuments/Nodesとの関係
原子使用プロセス
from llama_index import Document, VectorStoreIndex
# 数据源
text_list = [text1, text2, ...]
# 手动创建documents
documents = [Document(text=t) for t in text_list]
# 建立索引: 传入document,在VectorStoreIndex再转换:分片转成Node,Embedding等
index = VectorStoreIndex.from_documents(documents)
Documentを作成するいくつかの方法
手動で作成
from llama_index import Document
text_list = [text1, text2, ...]
documents = [Document(text=t) for t in text_list]
data loaderを使用して
いずれもload_data()の方法があります
from llama_index import SimpleDirectoryReader
documents = SimpleDirectoryReader("./data").load_data()
自動生成されたサンプルデータ
document = Document.example()
Metaをカスタマイズする
from llama_index import Document
from llama_index.schema import MetadataMode
document = Document(
text="This is a super-customized document",
metadata={
"file_name": "super_secret_document.txt",
"category": "finance",
"author": "LlamaIndex",
},
excluded_llm_metadata_keys=["file_name"],
metadata_seperator="::",
metadata_template="{key}=>{value}",
text_template="Metadata: {metadata_str}\n-----\nContent: {content}",
)
print(
"The LLM sees this: \n",
document.get_content(metadata_mode=MetadataMode.LLM),
)
print()
print(
"The Embedding model sees this: \n",
document.get_content(metadata_mode=MetadataMode.EMBED),
)
出力
The LLM sees this:
Metadata: category=>finance::author=>LlamaIndex
-----
Content: This is a super-customized document
The Embedding model sees this:
Metadata: file_name=>super_secret_document.txt::category=>finance::author=>LlamaIndex
-----
Content: This is a super-customized document
Metadata Extraction Usage Pattern(不明)
Node
本質:documentの断片
どうやって手に入れるか
-NodeParserクラスを使用してdocumentをNodeに転送 -手動で作成
Documentと同じように
-text
-metadata
-relationships:他のDocuments/Nodesとの関係
DocumentからNodeに変換する際には,metadataなどの情報を継承する.
NodeはLlamaIndexの一等市民です。
原子使用プロセス
from llama_index.node_parser import SentenceSplitter
# load documents
...
# 手动转换:切片,转成Node
# parse nodes
parser = SentenceSplitter()
nodes = parser.get_nodes_from_documents(documents)
# build index
index = VectorStoreIndex(nodes)
関係を設定
from llama_index.schema import TextNode, NodeRelationship, RelatedNodeInfo
node1 = TextNode(text="text_chunk1", id_="node_id1")
node2 = TextNode(text="text_chunk2", id_="node_id2")
node3 = TextNode(text="text_chunk3", id_="node_id3")
# set relationships
node1.relationships[NodeRelationship.NEXT] = RelatedNodeInfo(
node_id=node2.node_id
)
node2.relationships[NodeRelationship.PREVIOUS] = RelatedNodeInfo(
node_id=node1.node_id
)
node2.relationships[NodeRelationship.PARENT] = RelatedNodeInfo(
node_id=node3.node_id, metadata={"key": "val"}
)
print(node2)
NodeParser
用途:データソースをNodeオブジェクトに変換する
具体的には,documentオブジェクトのセットを複数のNodeオブジェクトに分割する
よく見られる具体的な実現
NodeParserは抽象クラスで具体的に実現されています
ファイルタイプ別
-SimpleFileNodeParser -HTMLNodeParser -JSONodeParser -MarkdownNodeParser
テキスト分割
-CodeSplitter -ランchainNodeParser -SentenceSplitter -SentenceWindowNodeParser(不明) -SemanticSplitterNodeParser(わからない、高級な気がする) -TokenTextSplitter
親子関係
-HierarchicalNodeParser:AutoMergingRetrieverで使用
典型的な用法
原子使用
from llama_index import Document
from llama_index.node_parser import SentenceSplitter
# 创建NodeParser
node_parser = SentenceSplitter(chunk_size=1024, chunk_overlap=20)
# 调用 get_nodes_from_documents() 方法
# show_progress 可以显示进度
nodes = node_parser.get_nodes_from_documents(
[Document.example(), Document.example()], show_progress=True
)
print(len(nodes))
print()
print(nodes[0])
出力
2
Node ID: eaeb6e44-6828-4e36-b7a3-69342de4dc7c
Text: Context LLMs are a phenomenal piece of technology for knowledge
generation and reasoning. They are pre-trained on large amounts of
publicly available data. How do we best augment LLMs with our own
private data? We need a comprehensive toolkit to help perform this
data augmentation for LLMs. Proposed Solution That's where LlamaIndex
comes in. Ll...
PiplineのTransformations
from llama_index import Document
from llama_index.node_parser import SentenceSplitter
from llama_index.ingestion import IngestionPipeline
from llama_index.node_parser import TokenTextSplitter
documents = [Document.example(), Document.example()]
# 创建NodeParser
node_parser = SentenceSplitter(chunk_size=1024, chunk_overlap=20)
# 将NodeParser放到Pipeline中的transformations列表
pipeline = IngestionPipeline(transformations=[node_parser])
nodes = pipeline.run(documents=documents)
print(len(nodes))
print()
print(nodes[0])
ServiceContextを使用
from llama_index import Document, ServiceContext, VectorStoreIndex
from llama_index.node_parser import SentenceSplitter
from llama_index.ingestion import IngestionPipeline
from llama_index.node_parser import TokenTextSplitter
documents = [Document.example(), Document.example()]
node_parser = SentenceSplitter(chunk_size=1024, chunk_overlap=20)
service_context = ServiceContext.from_defaults(text_splitter=node_parser)
index = VectorStoreIndex.from_documents(
documents, service_context=service_context, show_progress=True
)
トランスフォーム
入力:ノードのセット
出力:1組のNode
2つの公共の方法があります
-_call__():同期
-acall():非同期
NodeParserおよび`MetadataExtractor‘はTransformationsに属する
モードを使用
from llama_index.text_splitter import SentenceSplitter
from llama_index.extractors import TitleExtractor
node_parser = SentenceSplitter(chunk_size=512)
extractor = TitleExtractor()
# use transforms directly
nodes = node_parser(documents)
# or use a transformation in async
nodes = await extractor.acall(nodes)
ServiceContextと組み合わせて使用
from llama_index import ServiceContext, VectorStoreIndex
from llama_index.extractors import (
TitleExtractor,
QuestionsAnsweredExtractor,
)
from llama_index.ingestion import IngestionPipeline
from llama_index.text_splitter import TokenTextSplitter
transformations = [
TokenTextSplitter(chunk_size=512, chunk_overlap=128),
TitleExtractor(nodes=5),
QuestionsAnsweredExtractor(questions=3),
]
# 创建ServiceContext,传入Transfrmation
service_context = ServiceContext.from_defaults(
transformations=[text_splitter, title_extractor, qa_extractor]
)
# 传入VectorStoreIndex的from_documents()或insert()方法
index = VectorStoreIndex.from_documents(
documents, service_context=service_context
)
ServiceContext
a bundle of services and configurations used across a LlamaIndex pipeline.
構成可能
from llama_index import (
ServiceContext,
OpenAIEmbedding,
PromptHelper,
)
from llama_index.llms import OpenAI
from llama_index.text_splitter import SentenceSplitter
# 设置LLM
llm = OpenAI(model="text-davinci-003", temperature=0, max_tokens=256)
# 设置Embedding模型
embed_model = OpenAIEmbedding()
# 设置Chunk的大小
text_splitter = SentenceSplitter(chunk_size=1024, chunk_overlap=20)
prompt_helper = PromptHelper(
context_window=4096,
num_output=256,
chunk_overlap_ratio=0.1,
chunk_size_limit=None,
)
service_context = ServiceContext.from_defaults(
llm=llm, # 设置LLM
embed_model=embed_model, # 设置Embedding模型
text_splitter=text_splitter, # 设置Chunk的大小
prompt_helper=prompt_helper,
)
構造関数伝達(より便利)
Kwargs for node parser:
-``chunk_size` -chunk_overlap
Kwargs for prompt helper:
-context_window:
-num_output
例えば
service_context = ServiceContext.from_defaults(chunk_size=1000)
グローバル構成
from llama_index import set_global_service_context
set_global_service_context(service_context)
ローカル構成
query_engine = index.as_query_engine(service_context=service_context)
StorageContext
defines the storage backend for where the documents,embeddings,and indexes are stored
API Reference
store = PGVectorStore(
connection_string=conn_string,
async_connection_string=async_conn_string,
schema_name=PGVECTOR_SCHEMA,
table_name=PGVECTOR_TABLE,
)
index = VectorStoreIndex.from_vector_store(store)
VectorStoreIndex
構造関数
index = VectorStoreIndex.from_vector_store(store)
Engineには2種類あります
- Query Engine: BaseQueryEngine
- Chat Engines: BaseChatEngine
Engineの作成
index.as_query_engine()# BaseQueryEngine
index.as_query_engine(streaming=True)# 流式 BaseQueryEngine
index.as_chat_engine() # BaseChatEngine; 流式不是在这里控制
照会する
# Query
response = await query_engine.aquery(query) # 流式
response = await query_engine.aquery(query)
# Chat
response = await chat_engine.astream_chat(last_message_content, messages) # 流式在这里控制
response = await chat_engine.achat(last_message_content, messages)
BaseQueryEngine
-query -aquery
BaseChatEngine
-chat -stream_chat -achat -astream_chat
サポートフロー:stream
非同期をサポート:a先頭
応答のタイプ
# Query
RESPONSE_TYPE = Union[
Response,
StreamingResponse, AsyncStreamingResponse, #流式
PydanticResponse
]
# Chat
StreamingAgentChatResponse #流式
AGENT_CHAT_RESPONSE_TYPE = Union[AgentChatResponse, StreamingAgentChatResponse] #非流式
ストリーミングの応答をどのように処理するか
Pythonの標準インタフェースを使用します
-StreamingResponse() -AsyncStreamingResponse -StreamingResponse
-Query
@r.post("")
async def chat(
request: Request,
queryData: _QueryData,
query_engine: BaseQueryEngine = Depends(get_query_engine_stream),
):
query = queryData.query
streaming_response = await query_engine.aquery(query)
async def event_generator():
async for token in streaming_response.async_response_gen:
if await request.is_disconnected():
break
yield f"data: {token}\n\n"
return StreamingResponse(event_generator(), media_type="text/event-stream")
-Chat
@r.post("")
async def chat(
request: Request,
data: _ChatData,
chat_engine: BaseChatEngine = Depends(get_chat_engine),
):
last_message_content, messages = await parse_chat_data(data)
response = await chat_engine.astream_chat(last_message_content, messages)
async def event_generator():
async for token in response.async_response_gen():
if await request.is_disconnected():
break
yield token
return StreamingResponse(event_generator(), media_type="text/plain")
StreamingResponse
class AsyncStreamingResponse:
async_response_gen: TokenAsyncGen
class StreamingResponse:
response_gen: TokenGen
Response Modes
監視カメラ
教程
Deeplearnチュートリアル
Building and Evaluating Advanced RAG Applications:链接 Bilibili
Joint Text to SQL and Semantic Search
This video covers