RAG:检索增强生成
RAGさん
RAG:Retrieval Augmented Generation
あなたは複雑な事件を解決しようとしています
-探偵の役割は、事件に関する手がかり、証拠、およびいくつかの歴史的記録を収集することである。 探偵がこれらの情報を収集した後、記者はこれらの事実を魅力的な物語にまとめ、一貫した記述を呈した。
LLMの問題
- 幻覚:答えがない場合に偽りの情報を提供する.
- LLMは時代遅れの情報を用いており,その知識締切日以降の最新の信頼できる情報にアクセスできない.
- また,LLMが提供する答えがそのソースを引用していないことは,その主張がユーザに正確であるかどうかを検証できず,完全に信頼できないことを意味する.これは,人工知能を用いて生成された情報を用いて独立したチェックと評価を行うことの重要性を強調している.
您可以将大型语言模型看作是一个过于热情的新员工,他拒绝随时了解时事,但总是会绝对自信地回答每一个问题。
RAGはいくつかの課題を解決する1つの方法である.これはLLMをリダイレクトし,オーソリティのあらかじめ定められた知識源から関連情報を検索する.組織は、生成されたテキスト出力をよりよく制御することができ、ユーザは、LLMがどのように応答を生成するかを深く知ることができる。
LLMの流れ
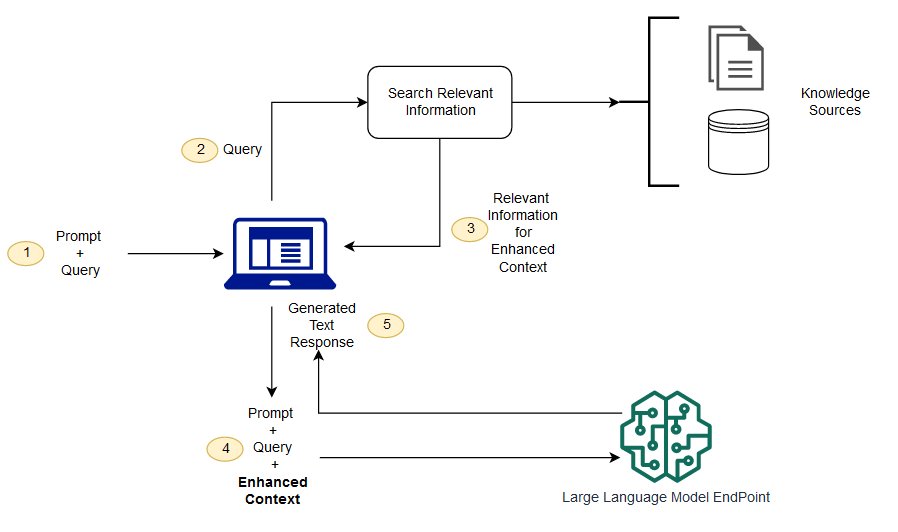
検索補強生成と意味検索の違いは?
意味探索はRAG結果を向上させることができ,そのLLMアプリケーションに大量の外部知識源を追加したい組織に適している.現代企業は、マニュアル、一般的な問題、研究報告、顧客サービスガイド、人的資源文書リポジトリなど、様々なシステムに大量の情報を格納する。文脈検索は規模的に挑戦的であるため,生成出力品質が低下する.
意味検索技術:異なる情報を含む大型データベースをスキャンし,より正確にデータを検索することができる.例えば、彼らはこう答えることができます*“去年機械修理にいくらかかりましたか?”*などの問題は、質問を関連文書にマッピングし、検索結果ではなく特定のテキストを返す方法である。そして,開発者はこの答えを用いてLLMにより多くの文脈を提供することができる.
RAGにおける従来やキーワード検索解決策が知識集約型タスクに対して生じる結果は限られている.開発者は,手動でデータを用意する際には,単語埋め込み,文書ブロック,その他の複雑な問題も扱わなければならない.これに対して,意味検索技術は知識ベース準備のすべての作業を行うことができるため,開発者はそうする必要はない.これらはまた,RAGペイロードの品質を最大限に向上させるために,意味的に関連するパラグラフと関連性に順位付けされたタグ語を生成する.
RAGの3つのコアコンポーネント
検索拡張生成モデルは主に3つのコアコンポーネントから構成される:
- 検索器(Retriever):外部知識源から関連情報の検索を担当する.
- シーケンサ(Ranker):検索結果を評価し,優先度を並べる.
- 生成器(Generator):検索とランキング結果を用いて,ユーザの入力に合わせて最終的な回答や内容を生成する.
RAG脳図
この図は、非常に詳細です!
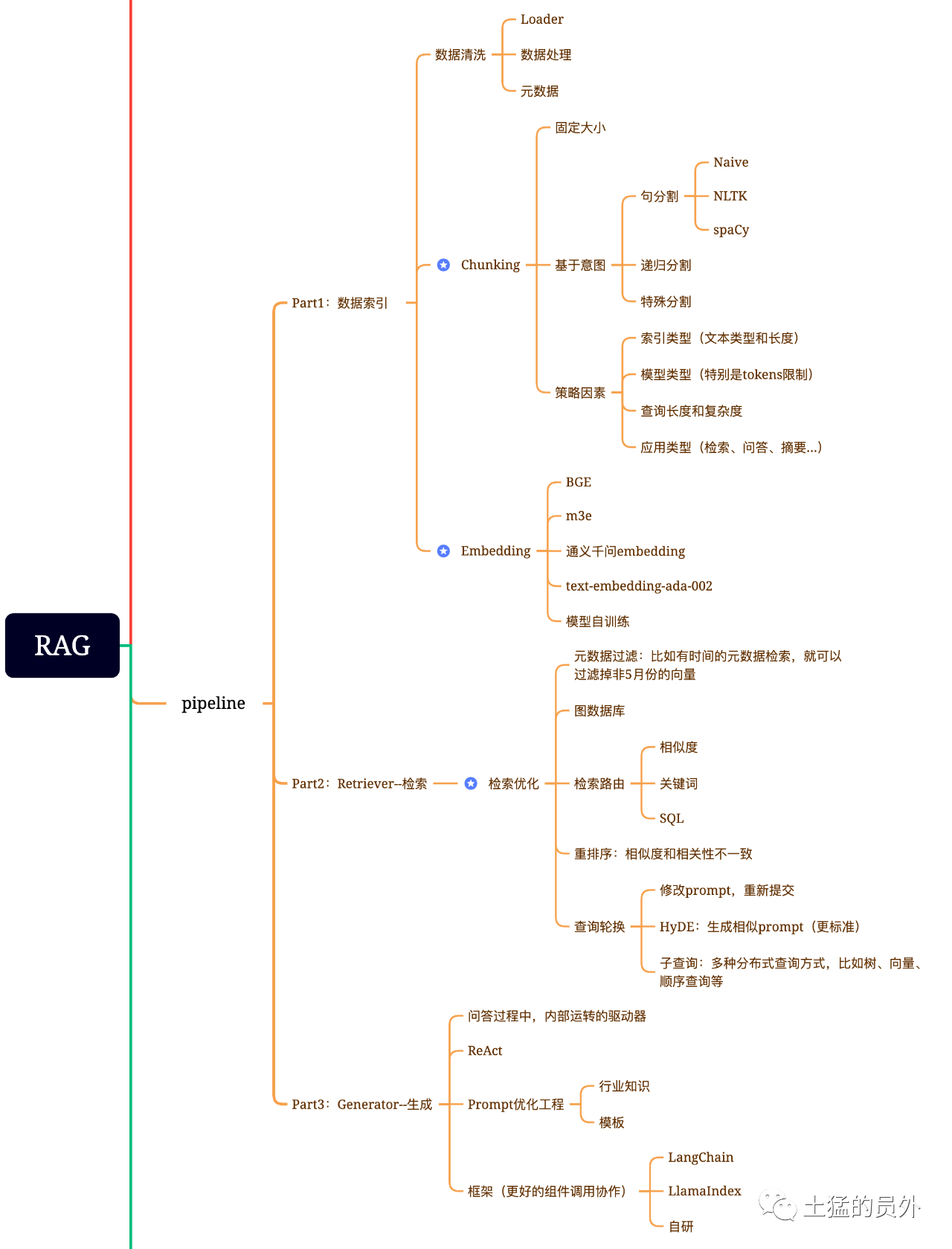
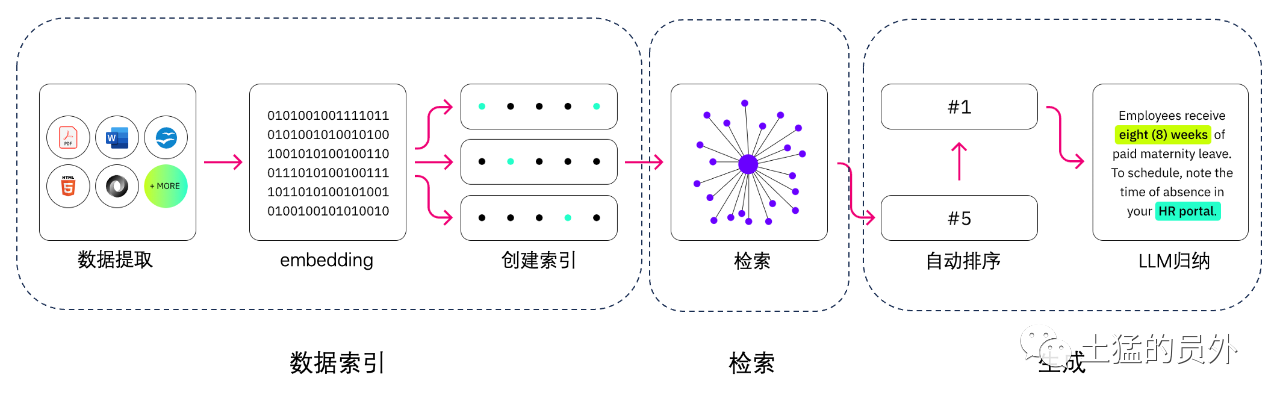
データ索引
データ抽出
--データクリーニング:データLoader、PDF、word、markdown、データベース、APIなどを抽出します データ処理:データフォーマット処理、識別できないコンテンツの除去、圧縮およびフォーマットなどを含む -メタデータ抽出:ファイル名、時間、章title、画像altなどの情報を抽出することは、非常に重要である。
データ抽出のツール
-UnstructuredIO -LlamaParse -Google Document AI -AWS Textract -pdf 2 image+pytesseract
検索する
検索最適化は一般に次の5つの作業に分けられる
-メタデータフィルタリング:インデックスを多くのchunksに分類した場合,検索効率が問題となる.このとき,メタデータで先にフィルタリングを行うことができれば,効率や関連度が大きく向上する.例えば、“XX部門の今年5月のすべての契約書のうち、XX設備調達が含まれている契約書はどのようなものがありますか?”と聞いてみましょう。。このとき,メタデータがあれば,“XX部門+2023年5月”に関するデータを検索することができ,検索量は一気に大域的な万分の1となる可能性がある
-グラフ関係検索:多くのエンティティをnodeにし,それらの関係をrelationにすることができれば,知識間の関係を利用してより正確に回答することができる.特に,いくつかのマルチホップ問題に対しては,グラフデータインデックスを利用することで検索の関連度が高くなる
-検索技術:先に述べた前置の前処理の手法であるが,検索の主な方式はこれらである:
-
- 相似度检索:前面我已经写过那篇文章《大模型应用中大部分人真正需要去关心的核心——Embedding》中有提到六种相似度算法,包括欧氏距离、曼哈顿距离、余弦等,后面我还会再专门写一篇这方面的文章,可以关注我,yeah; -キーワード検索:これは伝統的な検索方式であるが,重要な場合もある.先に述べたメタデータフィルタリングとは,chunkを要約し,キーワード検索により関連可能なchunkを見つけ,検索効率を増加させることである.Claudde.aiもそうしたという SQL検索:これはより伝統的ですが、現地化された企業アプリケーションの場合、SQL問合せは、前述した販売データのように、SQL検索を先に行う必要があります。 -その他:検索技術はまだたくさんありますので、後でゆっくり話しましょう。
-並べ替え(Rerank):chunksはシステム内で数が多く,我々の検索次元が最適であるとは限らず,一回の検索の結果が関連度にそれほど理想的でない可能性があるため,我々の検索結果が理想的でない場合が多い.このとき,planBを用いて並べ替えたり,関連度,適合度などを組み合わせて再調整したり,我々の業務場面に応じたランキングを得るなど,検索結果を並べ替える戦略が必要である.このステップの後,LLMに結果を送って最終処理を行うため,この部分の結果が重要である.この中には,関連度をレビューし,並べ替えをトリガする内部の判断器もある.
-*クエリローテーション:クエリ検索の1つの方式であり,一般にいくつかの方式がある:
**サブクエリ:LlamaIndexなどのフレームワークで提供されるクエリを使用して、ツリークエリ(葉ノードから、一歩ずつ検索、統合)、ベクトルクエリ、または最も原始的な順序クエリchunksなどの様々なクエリポリシーを使用することができます
*HyDE:類似またはより標準的なpromptテンプレートを生成する検針作業の方法です
Re-Rank
多くのベクトルデータベースは計算効率のためにある程度の精度を犠牲にする.これはその検索結果に一定のランダム性を持たせ,オリジナルが返すTop Kが必ずしも最も相関するとは限らない.
使用BAAI/bge-reranker-base、BAAI/bge-reranker-large等开源模型来完成Re-Rank操作。
網易のbce-reranker-baseもあり、中英日韓をサポートしています。
リコール·ハイブリッド検索
双路問い合わせ:
-意味検索(Vector Search)/ベクトルデータベースリコール -キーワード検索(Keyword Search)/キーワード検索リコール
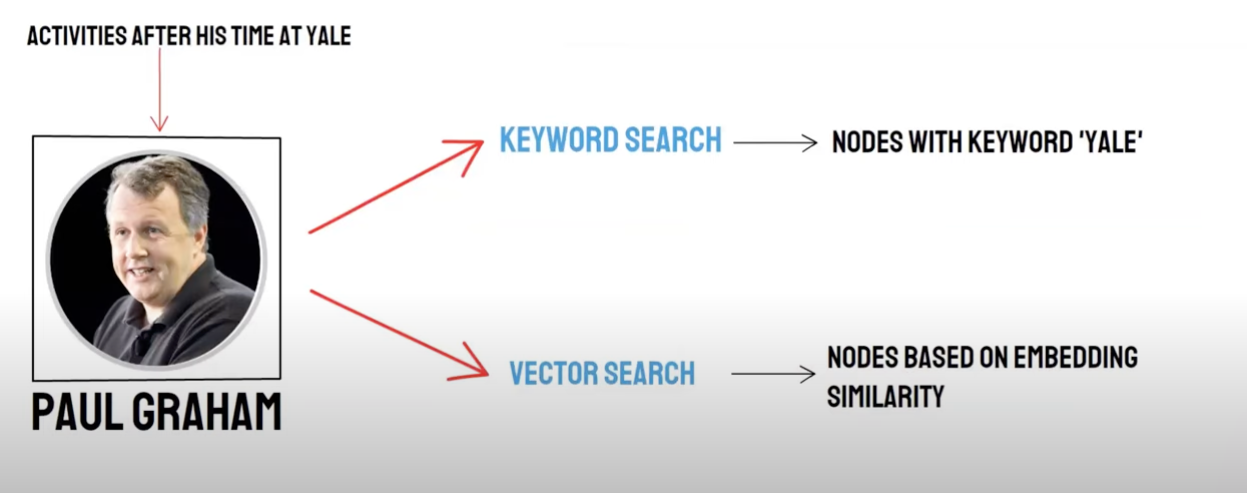
ベクトルデータベースリコールとキーワード検索リコールはそれぞれの優位性と不足があるため、両者のリコール結果を統合することは全体の検索正確性と効率を高めることができる。逆数ランキング融合(Reciprocal Rank Fusion,RRF)アルゴリズムは,文書ごとに異なるリコール方法におけるランキングを重み付き加算することで,融合後の総スコアを計算する.
キーワード検索リコール、すなわちKeyword Retrievalを用いてKeyword Ensembledを選択すると、PAIはデフォルトでRRFアルゴリズムを用いてベクトルデータベースリコール結果とキーワード検索リコール結果を多重リコール融合する。
生成
フレームにはLangchainとLlamaIndexがあります
技術を数える案
フレームワーク
難点は,text-to-sqlとは何か?
テキスト分割:
テキスト分割:文書を小さなブロックに分割し,後続のテキストEmbeddingを容易にし,さらに後続の文書検索を容易にする.
理想的には,意味的に関連するテキストセグメントを順に置く.
分割方法
-規則:(最も簡単な方法)文に従って文書を分割する.文書は,単語区切り文字,中英省略番号,二重引用符など,中国語や英語でよく見られる終了記号によって分割される. -意味によって: 1.まず,規則に基づいて文書を文レベルの文書ブロックに分割する 2.そして,モデルを用いて意味に基づいて文書ブロックを統合し,最終的に意味に基づく文書ブロックを得る
意味に基づくテキスト分割モデル
アリダモ院が発売した配列番号MODELこのモデルは,BERT+スライドウィンドウに基づいて,分割後の文が段落境界に属するかどうかを予測することで意味セグメントを決定する.
テキストベクトル化:Embeddingモデルの選択
智源のBBAモデル(bge-base-zhモデル)またはMTEBモデルから選択する.
ベクトル記憶
-Faiss:個人使用
-Milvus:生産レベル
質問に応じてベクトルを用いて適合知識点を検索する
Top_k
Faiss:chunk_size(一般に500文字)以下の近い文書を得るために検索結果の近傍に拡張探索を行う
Milvus:topk検索+bge-base-zh+パラグラフ類似集合モデル
思想:topk検索に基づく拡張検索の考え方を分析すると,主に意味段落を拡張することで,大きなモデルが回答時にできるだけ多くの有用な情報を獲得させることで回答効果を向上させることが分かった.
考え方:
- まず,規則に基づいて文書を文レベルの文書ブロックに分割する
- そして,モデルを用いて意味に基づいて文書ブロックを統合し,最終的に意味に基づく文書ブロックを得る
- 再び文書に対してテキストembeddingモデルを用い,意味的類似度に従って再クラスタリングすることは,元の文レベルの文書を2回異なる方法で2回クラスタリングしたことに相当する.
Promptを構築する
你现在是一个智能助手了,现在需要你根据已知内容回答问题
已知内容如下:
"{context}"
通过对已知内容进行总结并且列举的方式来回答问题:"{question}",在答案中不能出现问题内容,并且不允许编造内容,并且使用简体中文回答。
如果该问题和已知内容不相关,请回答 "根据已知信息无法回答该问题" 或 "没有提供足够的相关信息"。
解生成:LLMを選択する
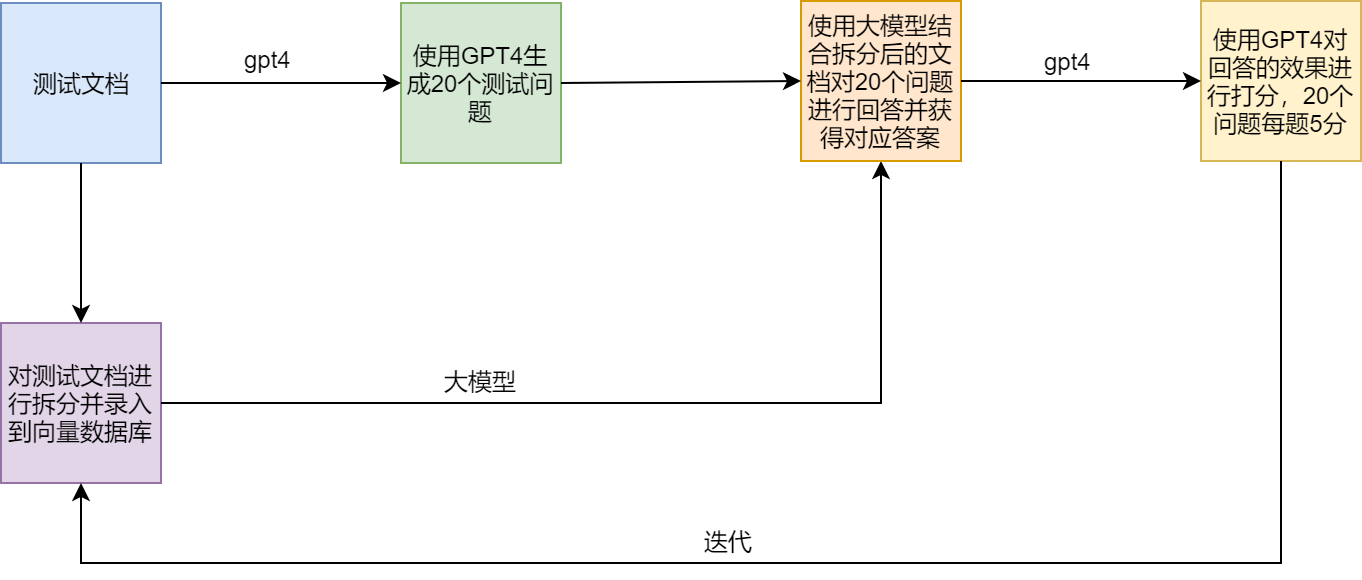
テスト案
RAGの痛みと解決策

例の例
LamaIndex官方提供了一个范例(SEC Insights),用来展示高级查询技术