RAG:检索增强生成
RA G
RAG: Retrieval Augmented Generation
당신은 복잡한 사건을 해결하려고 하고 있다:
- 형사는 사건과 관련된 단서, 증거, 기록 등을 수집하는 역할을 합니다.
- 탐정이 이 정보를 수집한 후, 기자는 이러한 사실들을 흥미진진한 이야기로 요약하고 일관성 있는 서술을 제시합니다.
LLM의 문제점
- 환각: 답 없이 거짓 정보를 제공한다.
- LLM은 오래된 정보를 사용하며 해당 지식 마감일 이후 최신의 신뢰할 수 있는 정보에 액세스할 수 없습니다.
- 또한 LLM은 출처를 참조하지 않는 답변을 제공합니다. 즉, 사용자의 주장이 정확하고 신뢰할 수 없다는 것을 의미합니다.이는 인공지능이 생성하는 정보를 사용할 때 독자적인 사찰과 평가의 중요성을 부각시킨다.
您可以将大型语言模型看作是一个过于热情的新员工,他拒绝随时了解时事,但总是会绝对自信地回答每一个问题。
RAG는 이러한 과제 중 일부를 해결할 수 있는 방법입니다.LLM을 리디렉션하여 미리 결정된 권위 있는 지식 소스에서 관련 정보를 검색합니다.조직은 생성된 텍스트 출력을 보다 잘 제어할 수 있으며 LLM이 응답을 생성하는 방법에 대한 통찰력을 얻을 수 있습니다.
LLM 프로세스
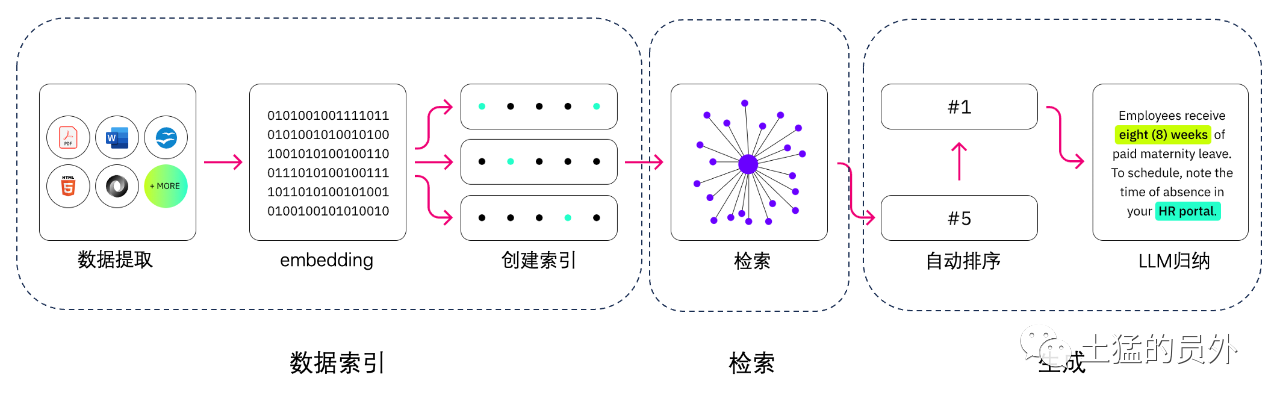
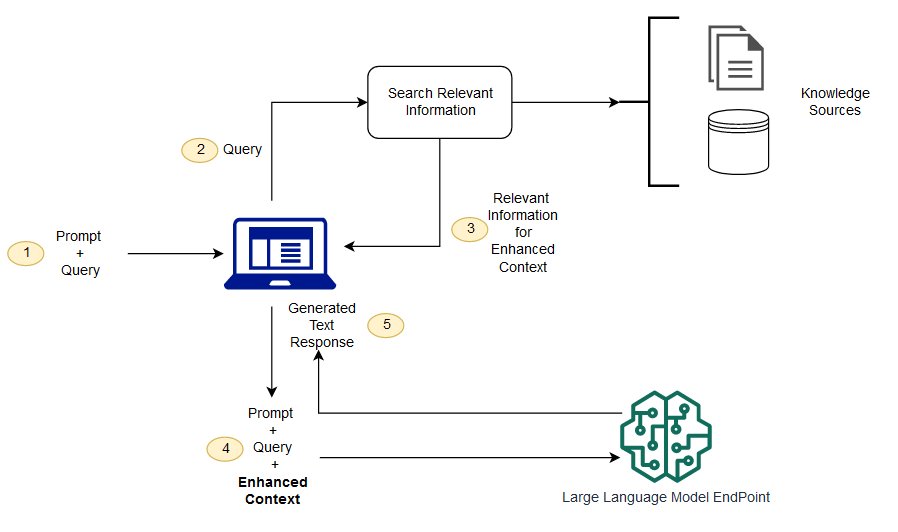
검색 향상 생성과 의미 검색의 차이점은 무엇입니까?
의미 검색은 LLM 응용 프로그램에 많은 외부 지식 소스를 추가하려는 조직에 적합한 RAG 결과를 향상시킬 수 있습니다.현대 기업들은 매뉴얼, FAQ, 연구 보고서, 고객 서비스 안내서, 인적 자원 문서 저장소 등 다양한 시스템에 대량의 정보를 저장합니다.컨텍스트 검색은 규모에 도전적이므로 결과 출력 품질이 저하됩니다.
시맨틱 검색 기술: 서로 다른 정보가 포함된 대형 데이터베이스를 스캔하고 데이터를 더 정확하게 검색할 수 있습니다.예를 들어, 그들은 * "작년에 기계 수리에 얼마를 썼는가?"라고 답할 수 있습니다.* 질문들을 관련 문서에 매핑하고 검색 결과가 아닌 특정 텍스트를 반환하는 등의 질문입니다.그런 다음 개발자는 이 답변을 사용하여 LLM에 더 많은 컨텍스트를 제공할 수 있습니다.
RAG의 기존 또는 키워드 검색 솔루션은 지식 집약적인 작업에 대한 제한적인 결과를 제공합니다.개발자는 수동으로 데이터를 준비할 때 단어 포함, 문서 청크 및 기타 복잡한 문제도 처리해야 합니다.이와는 대조적으로 의미 검색 기술은 지식 기반 준비의 모든 작업을 완료할 수 있으므로 개발자는 그렇게 할 필요가 없습니다.또한 의미 관련 단락과 관련성별로 정렬된 태그 단어를 생성하여 RAG 페이로드의 품질을 극대화합니다.
RAG의 3대 핵심 구성요소
Enhanced 생성 모델을 읽어들일 때는 크게 세 가지 핵심 컴포넌트로 구성됩니다.
- 검색자(Retriever): 외부 자료 소스에서 관련 정보를 읽어들일 책임이 있습니다.
- 정렬기: 검색 결과를 평가하여 우선 순위를 지정합니다.
- 생성기(Generator): 결과를 검색하고 정렬하여 사용자의 입력과 결합하여 최종 답변 또는 컨텐트를 생성합니다.
RAG 뇌도
이 그래프는, 매우 상세합니다!
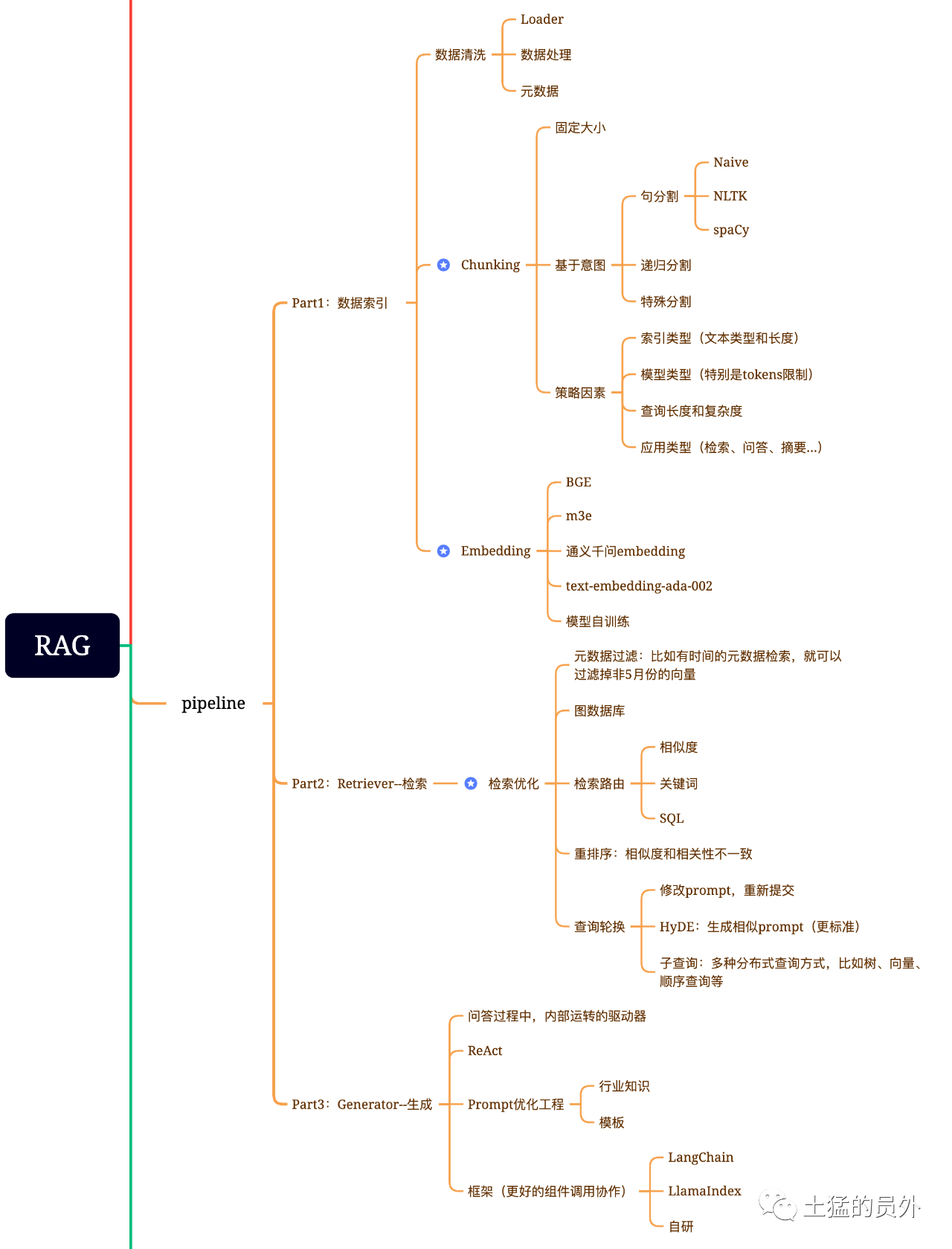
데이터 인덱스
-
데이터 추출
-
데이터 클리닝: 데이터 Loader, PDF, word, markdown, 데이터베이스 및 API 등의 추출
-
데이터 처리: 데이터 형식 처리, 인식할 수 없는 컨텐츠 제거, 압축 및 서식 지정 등을 포함합니다.
-
메타데이터 추출: 파일 이름, 시간, 장 title, 그림 alt 등의 정보를 추출합니다.
데이터 추출 도구
- UnstructuredIO(사용)
- LlamaParse (사용)
- Google Document AI
- AWS Textract
- pdf2image + pyteseract
검색
검색 최적화는 일반적으로 다음과 같은 다섯 부분으로 구성됩니다.
-
메타데이터 필터링: 인덱스를 여러 개의 chunks로 나눌 때 검색 효율성이 문제가 됩니다.이럴 때 메타데이터를 통해 먼저 필터링할 수 있다면 효율성과 관련도를 크게 높일 수 있다.예를 들어 'XX 부서의 올해 5월 모든 계약 중 XX 장비 구매가 포함된 계약서에는 어떤 것들이 있는지 정리해 달라'고 물었다..이때 메타데이터가 있으면 'XX부서+2023년 5월' 관련 데이터를 검색하면 검색량이 단번에 전역의 만분의 1이 될 수 있습니다.
-
그림 관계 검색: 많은 엔티티를 node로, 이들 사이의 관계를 relation으로 바꿀 수 있다면 지식 간의 관계를 이용하여 보다 정확한 답변을 할 수 있습니다.특히 다중 홉 문제를 해결하기 위해 그래프 데이터 인덱스를 사용하면 검색의 상관도가 높아집니다.
-
검색 기술: 선행 선행 처리 방법, 검색의 주요 방법은 다음과 같습니다.
-
- 相似度检索:前面我已经写过那篇文章《大模型应用中大部分人真正需要去关心的核心——Embedding》中有提到六种相似度算法,包括欧氏距离、曼哈顿距离、余弦等,后面我还会再专门写一篇这方面的文章,可以关注我,yeah;
-
키워드 검색: 기존 검색 방식이지만, 때로는 중요하기도 합니다.아까 저희가 말씀드렸던 메타데이터 필터링은 일종의, 또 하나는 chunk를 요약한 다음에 키워드 검색을 통해서 연관될 수 있는 chunk를 찾아서 검색 효율성을 높이는 것이다.Claude.ai도 그렇게 했다고 합니다;
-
SQL 검색: 이전의 영업 데이터와 같이 일부 로컬라이제이션된 엔터프라이즈 애플리케이션에는 SQL 쿼리가 필수적입니다.
-
기타 : 검색기술이 아직 많으니 뒤에 쓰면서 천천히 얘기하자.
-
리시퀀싱(Rerank): 검색 결과가 좋지 않은 경우가 많습니다. 이는 chunks가 시스템 내 많은 수를 가지고 있기 때문에 검색 차원이 최적일 수는 없으며, 한 번의 검색 결과는 상관도에서 그다지 좋지 않을 수 있기 때문입니다.이 경우 planB를 사용하여 재정리하거나 조합의 상관도, 일치도 등의 요소를 재조정하여 비즈니스 시나리오에 보다 적합한 정렬을 얻을 수 있는 검색 결과를 재정리하는 전략이 필요합니다.왜냐하면 이 단계 이후에 LLM에 결과를 보내서 최종 처리를 하게 되기 때문에 이 부분의 결과가 중요합니다.이 안에는 또한 관련도를 검토하여 재정리를 트리거하는 내부 판단기가 있을 것입니다.
-
쿼리 교체: 쿼리 검색의 한 가지 방법입니다. 일반적으로 다음과 같은 몇 가지 방법이 있습니다.
-
** 하위 쿼리: ** LlamaIndex와 같은 프레임에서 제공되는 쿼리기를 사용하여 트리 쿼리(잎 끝 지점, 한 단계씩 쿼리, 병합), 벡터 쿼리 또는 가장 원래 순서로 chunks를 쿼리하는 등 다양한 시나리오에서 다양한 쿼리 전략을 사용할 수 있습니다.**
-
HyDE:작업 참조 방식으로 유사하거나 보다 표준적인 prompt 템플릿을 생성합니다.
Re-Rank
대부분의 벡터 데이터베이스는 효율성을 계산하기 위해 어느 정도의 정확성을 희생합니다.이렇게 하면 검색 결과가 임의적으로 나타나며 원래 Top K를 반환하는 것이 가장 관련이 없을 수 있습니다.
使用BAAI/bge-reranker-base、BAAI/bge-reranker-large等开源模型来完成Re-Rank操作。
중영일한을 지원하는 넷이즈의 bce-reranker-base도 있다.
리콜/혼합 검색
2소켓 쿼리:
- 의미 검색(Vector Search)/벡터 데이터베이스 리콜
- 키워드 검색 / 키워드 검색 리콜
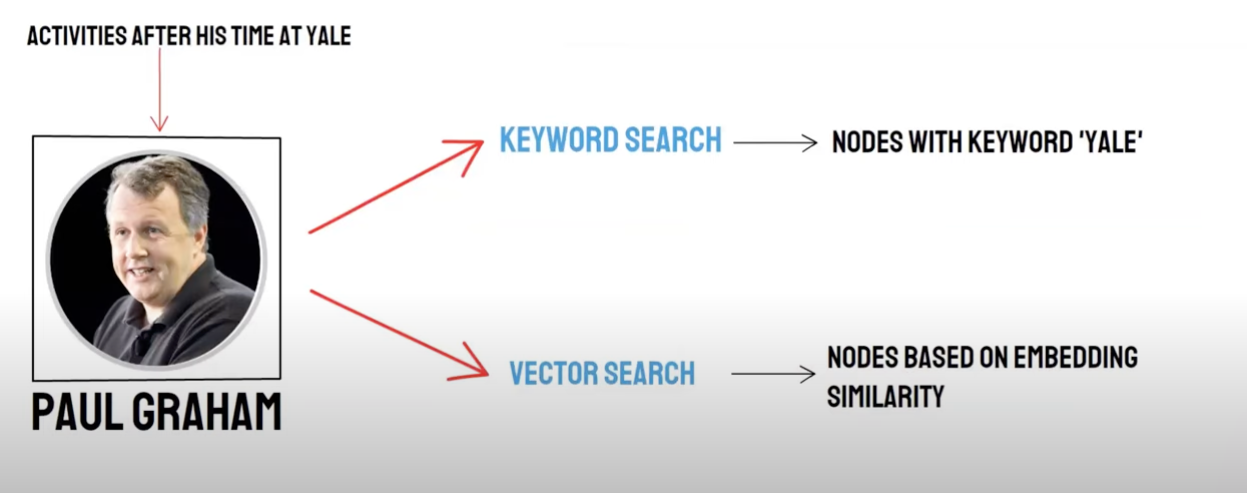
벡터 데이터베이스 리콜 및 키워드 검색 리콜은 각각의 장점과 부족을 가지므로 두 가지 모두의 리콜 결과를 종합하면 전체적인 검색 정확성과 효율성을 높일 수 있다.역순 정렬 융합(Reciprocal Rank Fusion, RRF) 알고리즘은 각 문서의 다양한 리콜 방법에서 순위를 가중치를 부여하여 합산하여 혼합 후의 총 점수를 계산합니다.
키워드를 사용하여 리콜 검색 Keyword RetrievalKeyword Ensemblet**을 선택하면 PAI는 기본적으로 RRF 알고리즘을 사용하여 벡터 데이터베이스 리콜 결과와 키워드 검색 리콜 결과를 멀티플렉싱합니다.
생성
프레임에는 Langchain과 LlamaIndex가 있습니다
수하 기술의 방안.
프레임
어려운 점은 text-to-sql이 뭔가요?
텍스트 분할:
텍스트 분할: 문서를 더 작은 블록으로 분할하여 후속 문서를 쉽게 검색할 수 있도록 Embedding 텍스트를 만들 수 있습니다.
이상적 상황: 의미 관련 텍스트 조각을 순서에 따라 함께 놓으십시오.
분할 방법
- 규칙에 따라: (가장 간단한 방법) 문장별로 문서를 버스트합니다.중국어 및 영어에서 일반적으로 사용되는 종료 기호(예: 단일 문자 줄임표, 중국어 줄임표, 큰따옴표 등)를 기준으로 문서를 분할합니다.
- 의미에 따라: 1.먼저 규칙을 기반으로 문서를 문장 수준의 문서 블록으로 분할합니다. 2.그런 다음 모델을 사용하여 시맨틱 기반 문서 블록을 통합하여 궁극적으로 의미 기반 문서 블록을 얻을 수 있습니다.
** 의미 기반 텍스트 분할 모델**
아리다모원이 출시한 SEQ_MODEL 이 모델은 분할된 문장이 단락 경계에 속하는지 여부를 예측하여 의미 세그먼트를 결정하는 BERT+ 슬라이딩 창을 기반으로 한다.
텍스트 방향 정량화:Embedding 모델 선택
지원의 BBA 모델(bge-base-zh 모델) 또는 MTEB 롤모델 중에서 선택하십시오.
벡터 저장소
-
Faiss: 개인용
-
Milvus: 프로덕션 레벨
질의에 따라 벡터를 이용한 매칭 지식 포인트 검색
Top_k
Faiss: 검색 결과 근처를 확장하여 chunk_size(일반적으로 500자)보다 작은 문서를 찾습니다.
Milvus: topk 검색 + bge-base-ko + 단락 유사 합산 모델
생각: topk 검색에 기반한 확장 검색 아이디어를 분석하면 주로 의미 세그먼트를 확장하여 큰 모델이 대답할 때 가능한 한 많은 유용한 정보를 얻어 응답 효과를 높일 수 있다는 것을 알게 되었습니다.
아이디어:
- 먼저 규칙을 기반으로 문서를 문장 수준의 문서 블록으로 분할합니다.
- 그런 다음 모델을 사용하여 시맨틱 기반 문서 블록을 통합하여 궁극적으로 의미 기반 문서 블록을 얻을 수 있습니다.
- 다시 한 번 문서에 대해 텍스트 embedding 모델을 사용하여 의미 유사도에 따라 다시 집계합니다. 두 번 다른 방법으로 원래 문장 레벨의 문서를 두 번 합산하는 것과 같습니다.
Prompt 빌드
你现在是一个智能助手了,现在需要你根据已知内容回答问题
已知内容如下:
"{context}"
通过对已知内容进行总结并且列举的方式来回答问题:"{question}",在答案中不能出现问题内容,并且不允许编造内容,并且使用简体中文回答。
如果该问题和已知内容不相关,请回答 "根据已知信息无法回答该问题" 或 "没有提供足够的相关信息"。
대답 생성: LLM 선택
테스트 시나리오
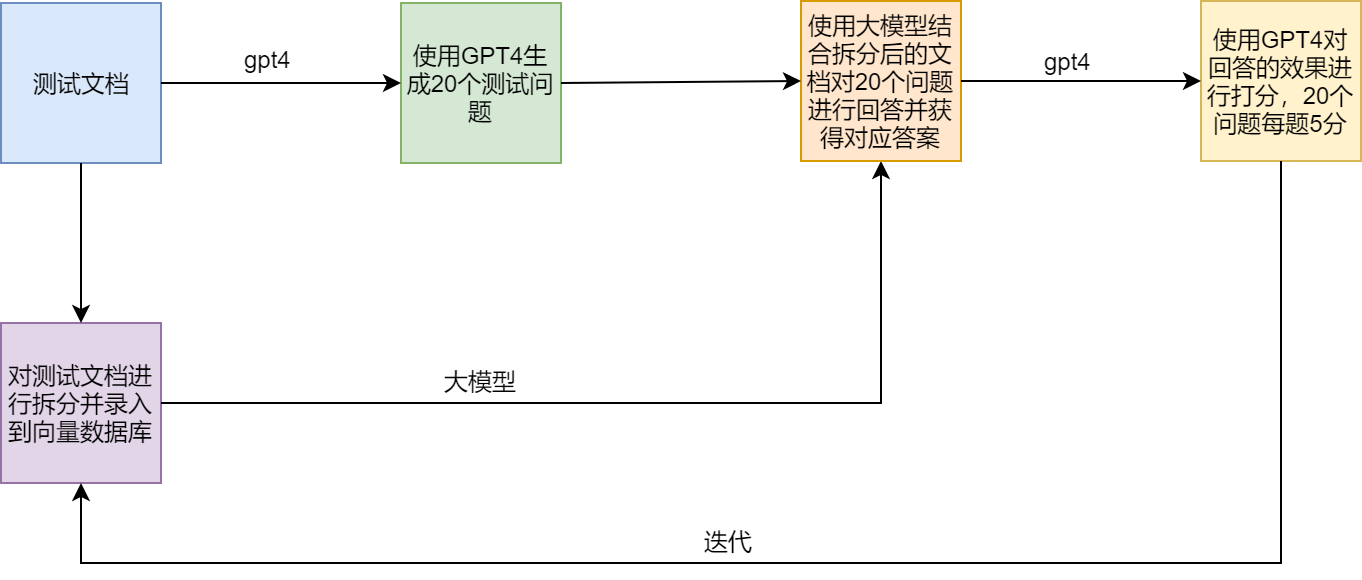
RAG의 문제점과 해결 방안

예 제
LamaIndex官方提供了一个范例(SEC Insights),用来展示高级查询技术