RAG:检索增强生成
RAG
RAG: Retrival Augmented Generation
คุณกําลังพยายามไขคดีที่ซับซ้อน
- บทบาทของนักสืบคือการรวบรวมเงื่อนงํา หลักฐาน และประวัติบางอย่างที่เกี่ยวข้องกับคดี "หลังจากนักสืบรวบรวมข้อมูลเสร็จ ผู้สื่อข่าวจึงสรุปข้อเท็จจริงเหล่านี้เป็นเรื่องราวที่น่าสนใจและนําเสนอเรื่องราวที่มีความต่อเนื่องกัน
ปัญหาของแอลเอ็ม
- ภาพหลอน : ให้ข้อมูลเท็จโดยไม่มีคําตอบ
- LLM ใช้เป็นข้อมูลล้าสมัย ซึ่งไม่สามารถเข้าถึงข้อมูลล่าสุดและเชื่อถือได้หลังจากวันกําหนดเส้นตายความรู้ของตน
- นอกจากนี้ คําตอบจาก LLM ไม่ได้อ้างอิงถึงแหล่งที่มา ซึ่งหมายความว่า คําสอนนั้นไม่สามารถตรวจสอบความถูกต้องโดยผู้ใช้ได้ และไม่สามารถวางใจได้เต็มที่ ซึ่งเน้นให้เห็นถึงความสําคัญของการตรวจสอบและประเมินด้วยตนเองเมื่อใช้ข้อมูลที่สร้างโดยปัญญาประดิษฐ์ (AI)
您可以将大型语言模型看作是一个过于热情的新员工,他拒绝随时了解时事,但总是会绝对自信地回答每一个问题。
RAG คือวิธีแก้ปัญหาท้าทายบางอย่าง มันจะกําหนดกลับให้ LLM นําข้อมูลที่เกี่ยวข้องจากผู้มีอํานาจและแหล่งความรู้ที่ได้กําหนดไว้ล่วงหน้า องค์กรสามารถควบคุมการแสดงผลข้อความที่สร้างได้ดีขึ้น และผู้ใช้สามารถเรียนรู้เชิงลึกว่า LLM สร้างการตอบสนองอย่างไร
กระบวนการของแอลเอ็ม
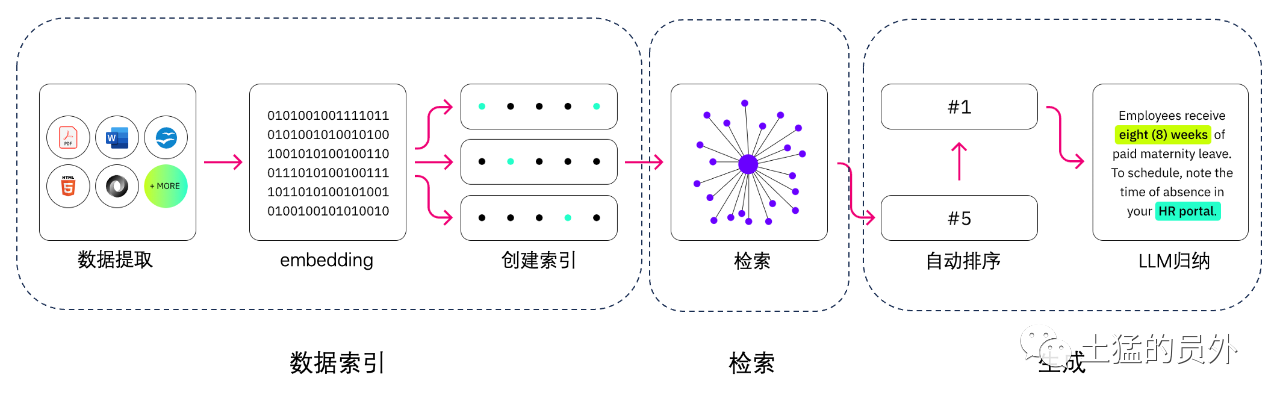
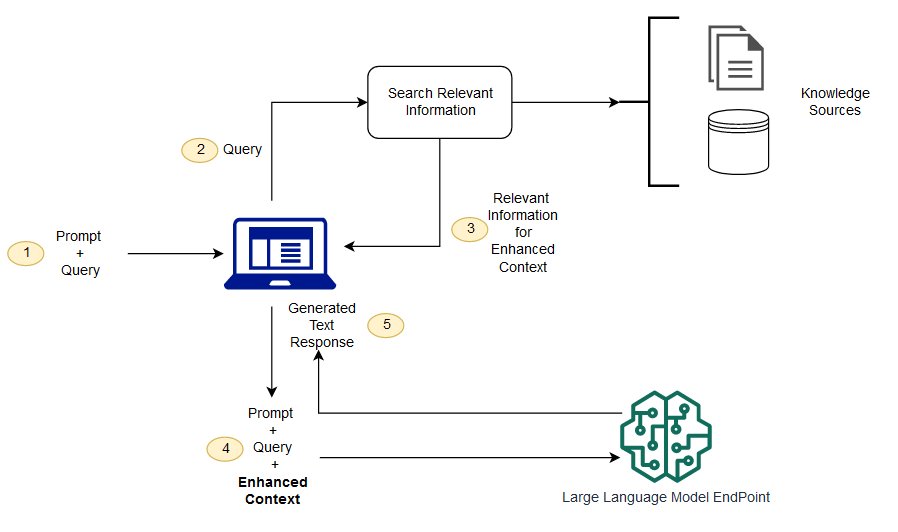
(ไม่เข้าใจ) การดึงข้อมูลการสร้างเสริมและการค้นหาความหมายต่างกันอย่างไร?
การค้นหาความหมาย จะช่วยเพิ่มผล RAG สําหรับองค์กรที่ต้องการเพิ่มแหล่งความรู้ภายนอกจํานวนมากในแอพฯ LLM ของตน ธุรกิจสมัยใหม่เก็บข้อมูลมากมายในระบบต่างๆ เช่น คู่มือ ปัญหาทั่วไป รายงานการวิจัย คู่มือการให้บริการลูกค้า และคลังเอกสารด้านทรัพยากรบุคคล เป็นต้น การดึงคอนเทนต์มาใช้งานในระดับที่ท้าทาย จึงจะลดคุณภาพการสร้างเอาท์พุทลง
เทคโนโลยีการค้นหาภาษา : สามารถสแกนฐานข้อมูลขนาดใหญ่ที่มีข้อมูลต่าง ๆ และรับข้อมูลได้อย่างแม่นยํายิ่งขึ้น ยกตัวอย่างเช่น พวกเขาสามารถตอบได้เช่น* "ปีที่แล้วใช้เงินไปเท่าไหร่ในการซ่อมบํารุงเครื่องจักร" * คําถามอื่นๆ เช่น การจับคู่ปัญหากับเอกสารที่เกี่ยวข้องและกลับไปใช้ข้อความเฉพาะแทนผลการค้นหา จากนั้นนักพัฒนาสามารถใช้คําตอบนี้เพื่อนําเสนอคอนเทนท์เพิ่มเติมให้กับ LLM ได้
โซลูชั่นค้นหาคําค้นแบบเก่าหรือคีย์เวิร์ดใน RAG มีผลลัพธ์ที่จํากัดต่องานที่ต้องใช้ความรู้มาก นักพัฒนายังต้องจัดการกับการฝังคํา บล็อกเอกสาร และปัญหาที่ซับซ้อนอื่นๆ ในการเตรียมข้อมูลด้วยตนเอง เทียบกับเทคโนโลยีการค้นหาภาษาที่สามารถทํางานทุกอย่างที่ฐานความรู้เตรียมไว้ได้ ดังนั้นนักพัฒนาจึงไม่จําเป็นต้องทํา พวกเขายังสร้างย่อหน้าและคําเครื่องหมายที่เรียงลําดับตามความเกี่ยวข้อง เพื่อเพิ่มคุณภาพของประจุที่มีประสิทธิภาพสูงสุดของ RAG
ส่วนประกอบหลักสามประการของ RAG
การรับโมเดลการสร้างเสริมนั้นประกอบด้วยองค์ประกอบหลัก 3 ประการ คือ
- เครื่องตรวจ (Retriever) : ทําหน้าที่รับข้อมูลที่เกี่ยวข้องจากแหล่งความรู้ภายนอก
- ลําดับ (Ranker) : ประเมินผลการรับข้อมูล และจัดลําดับความสําคัญ
- ตัวสร้าง (Generator): ใช้การรับข้อมูลและเรียงลําดับผลลัพธ์ รวมกับการป้อนข้อมูลของผู้ใช้ สร้างคําตอบหรือเนื้อหาสุดท้าย
แผนที่สมอง RAG
ภาพนี้ ละเอียดมาก!
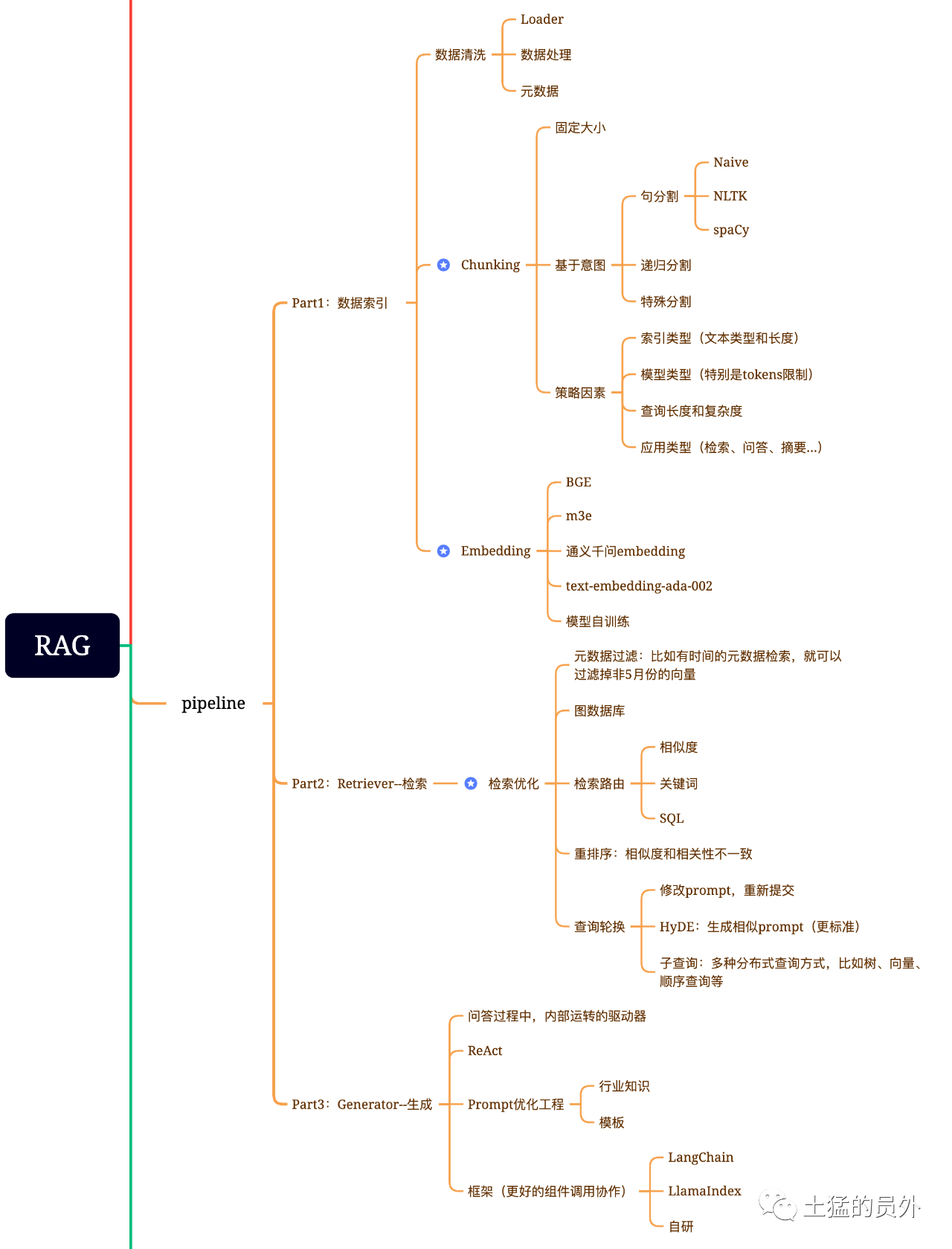
ดัชนีข้อมูล
"การสกัดข้อมูล"
- การล้างข้อมูล : ได้แก่ ข้อมูล Loader, สกัด PDF, word, markdown และฐานข้อมูล และ API เป็นต้น
- การประมวลผลข้อมูล: รวมถึงการประมวลผลในรูปแบบข้อมูล, ไม่สามารถระบุข้อมูลได้, การบีบอัดและฟอร์แมต เป็นต้น
- การดึงข้อมูลกํากับ: การดึงข้อมูลชื่อ, เวลา, บทเฉพาะกาล, title, รูปภาพ alt เป็นต้น ที่สําคัญมาก
เครื่องมือในการดึงข้อมูล
- UnstructuredIO (ใช้แล้ว)
- Llama Parse (ใช้แล้ว)
- Google Document AI
- AWS Textract
- Sticker f2image + pytesseract
รับข้อมูล
การปรับแต่งทั่วไปสําหรับการรับข้อมูลแบ่งออกเป็น 5 ส่วนต่อไปนี้:
· * การกรองข้อมูลกํากับภาพ*: เมื่อเราแยกดัชนีออกเป็น chunks มากมาย ประสิทธิภาพในการรับข้อมูลจะกลายเป็นปัญหา ณ เวลานั้น หากสามารถกรองผ่านข้อมูลกํากับได้ก่อน ก็จะช่วยเพิ่มประสิทธิภาพและความเกี่ยวข้องได้มากทีเดียว เช่น เราถามว่า "ช่วยจัดระเบียบให้หน่อยว่า สัญญาทั้งหมดของแผนก XX ในเดือนพ.ค.นี้ มีสัญญาในการจัดซื้ออุปกรณ์ XX มีอะไรบ้าง ณ เวลานั้น หากมีข้อมูลกํากับ เราก็สามารถเข้าไปค้นหาข้อมูลที่เกี่ยวข้องของ "กระทรวง" ได้ "พฤษภาทมิฬ 2023" การตรวจนับนับครั้งไม่ถ้วนอาจกลายเป็น 1 ในหมื่นประการของส่วนรวมได้ ; .
การดึงความสัมพันธ์แบบกราฟ: ถ้าสามารถเปลี่ยนหลายร่างเป็น node และเปลี่ยนความสัมพันธ์ระหว่างมันให้เป็น relation สามารถใช้ความสัมพันธ์ระหว่างความรู้ในการตอบได้อย่างแม่นยํามากขึ้น โดยเฉพาะกับประเด็นการกระโดดเยอะๆ การใช้ดัชนีข้อมูลกราฟจะทําให้ความเกี่ยวข้องในการรับข้อมูลสูงขึ้น
· * เทคนิคในการรับข้อมูล*: ที่กล่าวมาก่อนหน้านี้คือวิธีการจัดการล่วงหน้าซึ่งวิธีการรับข้อมูลหลักหรือวิธีเหล่านี้:
-
- 相似度检索:前面我已经写过那篇文章《大模型应用中大部分人真正需要去关心的核心——Embedding》中有提到六种相似度算法,包括欧氏距离、曼哈顿距离、余弦等,后面我还会再专门写一篇这方面的文章,可以关注我,yeah;
- การรับคําสําคัญ**: นี่เป็นวิธีการรับข้อมูลแบบดั้งเดิม แต่บางครั้งก็สําคัญเช่นกัน การกรองข้อมูลหลักที่เรากําลังพูดถึงนั้น เป็นอีกวิธีหนึ่งคือ การสรุป chunk ให้สรุปก่อน และค้นหา chunk ที่อาจเกี่ยวข้องด้วยคําสําคัญ เพื่อเพิ่มประสิทธิภาพในการรับข้อมูล ว่ากันว่า ... ... .
- การรับข้อมูลแบบ SQL*: วิธีนี้ยิ่งเป็นประเพณีมากขึ้น แต่สําหรับแอพพลิเคชั่นสําหรับธุรกิจที่เป็นแบบท้องถิ่น การสืบค้นแบบ SQL เป็นสิ่งจําเป็น เช่น ข้อมูลการขายที่ผมกล่าวถึงก่อนหน้านี้ ต้องทํา SQL ในการรับข้อมูลก่อน
- อื่นๆ : เทคนิคการรับข้อมูลยังมีอีกเยอะ ด้านหลังใช้จนค่อย ๆ พูดไป
· * การเรียงลําดับหนัก (Rerank)*: หลายครั้งที่ผลการรับข้อมูลของเราไม่สู้ดีนัก เพราะ chunks มีจํานวนมากในระบบ และมิติที่เรารับมานั้นไม่จําเป็นต้องดีที่สุดเสมอไป และผลลัพธ์ในการรับข้อมูลครั้งเดียวอาจไม่ได้ดีเท่าบนค่าความเกี่ยวข้อง ช่วงเวลานี้เราจําเป็นต้องมีกลยุทธ์ในการเรียงลําดับผลลัพธ์ในการรับข้อมูล เช่น การใช้ plan B เรียงลําดับหนัก หรือปรับองค์ประกอบต่างๆ ที่เกี่ยวข้อง ให้ลงตัว และได้รับการเรียงลําดับที่สอดคล้องกับฉากธุรกิจของเรามากขึ้น เพราะหลังจากขั้นตอนนี้ไปแล้วเราก็จะส่งผลลัพธ์ให้ LLLM ดําเนินการในที่สุด ดังนั้นผลลัพธ์ในส่วนนี้จึงมีความสําคัญมาก ข้างในจะมีตัวตัดสินภายใน เพื่อตัดสินความเกี่ยวข้อง กระตุ้นการเรียงลําดับซ้ํา
-***: เป็นวิธีหนึ่งในการสืบค้นการรับข้อมูล ซึ่งโดยทั่วไปจะมีหลายวิธี:
· *การสืบค้นย่อย: *สามารถใช้กลยุทธ์การสืบค้นต่างๆ ในฉากต่าง ๆ เช่น สามารถใช้การสืบค้นจากกรอบของ Lllama Index ได้ โดยใช้การสืบค้นต้นไม้ (จากจุดสิ้นสุดของใบ การสืบค้นทีละขั้น การควบรวม) การสืบค้นแบบวัดปริมาณ หรือลําดับเดิมสุดของ chunks เป็นต้น ****
"HyDE: " เป็นวิธีการลอกงาน สร้างต้นแบบ prompt ที่คล้ายคลึงกันหรือมาตรฐานกว่า" *
Re-Rank
ฐานข้อมูลวัดค่าส่วนใหญ่จะเสียสละความถูกต้องในระดับหนึ่ง เพื่อประสิทธิภาพในการคํานวณ ซึ่งทําให้การดึงผลลัพธ์ออกมามีความสุ่มเสี่ยง และ Top K ที่กลับมาเดิมอาจไม่ได้เกี่ยวข้องกันมากที่สุด
使用BAAI/bge-reranker-base、BAAI/bge-reranker-large等开源模型来完成Re-Rank操作。
ยังมี bce-reranker-base ที่ใช้งานง่ายในเน็ต และสนับสนุน นัมยอง ฮัง
เรียกใช้/ ผสมการเรียกข้อมูล
สอบถามทางคู่ :
· การรับข้อมูลทางภาษา (Vector Search)/** การเรียกคืนข้อมูลไปยังฐานข้อมูลวัด*
- การเรียกใช้คีย์เวิร์ด (Keyword Search) / การเรียกกลับคําสําคัญ
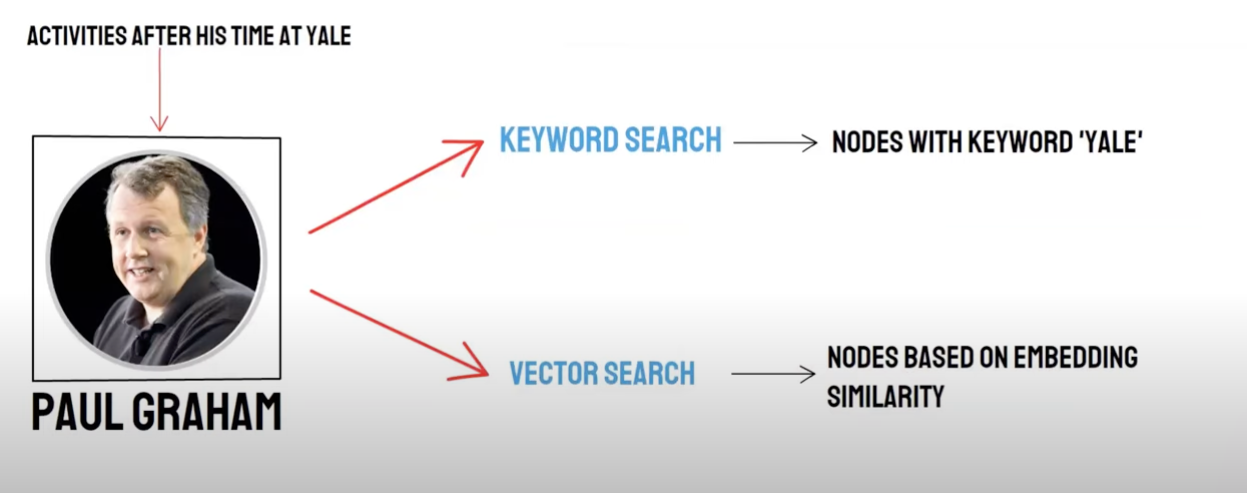
การเรียกคืนฐานข้อมูลปริมาณและการรับคําสําคัญต่าง ๆ มีข้อได้เปรียบและข้อด้อยของแต่ละคน ดังนั้นผลลัพธ์การเรียกคืนทั้ง 2 แบบจึงจะช่วยเพิ่มความถูกต้องและประสิทธิภาพในการรับข้อมูลโดยรวม นับถอยหลังการเรียงลําดับการรวมตัว (Reciprocal Rank Fusion, RRF)อัลกอริทึมของอัลกอริทึม ผ่านการร้องขอสิทธิในการจัดอันดับของเอกสารแต่ละฉบับในวิธีการเรียกคืนที่แตกต่างกัน โดยคํานวณคะแนนรวมหลังจากหลอมรวมเข้าด้วยกัน
เมื่อคุณเลือกที่จะรับการเรียกกลับโดยใช้คําสําคัญ คือ * Keyword Retrival* เลือก * Keyword Ensembled** * PAI จะใช้อัลกอริธึม RRF ผสมผสานกับการเรียกกลับหลายเส้นทางโดยปริยายกับผลการเรียกกลับฐานข้อมูลวัดค่าและผลการเรียกกลับคําสําคัญ (Keyword Retrival*) ของ Keyword Ensembled*
สร้าง
กรอบมี Langlia และ Llama Index
รูปแบบของเทคโนโลยีการนับเลข
กรอบ
สิ่งที่ยากคือ: text-to-sql คืออะไร?
แยกข้อความ:
การแยกข้อความ: แบ่งเอกสารออกเป็นชิ้นเล็กกว่าเพื่อความสะดวกในการทํา Embedding ของข้อความต่อไป เพื่อความสะดวกในการรับเอกสารต่อไป
สถานการณ์ในอุดมคติ : นําคลิปข้อความที่เกี่ยวข้องในความหมายมาประกอบกันตามลําดับ
"วิธีการแยกชิ้นส่วน"
- ตามกฎ : (วิธีที่ง่ายที่สุด) แยกเอกสารตามประโยค มีการแบ่งส่วนกับเอกสารตามสัญลักษณ์ที่พบเห็นได้ทั่วไปทั้งภาษาจีนและภาษาอังกฤษ เช่น อักษรเดี่ยว อักษรย่อ อักษร อักษรกลาง อักษรคู่ เป็นต้น
- ตามความหมาย:
- เริ่มจากการแยกชิ้นส่วนเอกสารเป็นระดับประโยค โดยใช้กฎในการแยกเอกสาร
- จากนั้นใช้แบบจําลองเพื่อผนวกรวมบล็อกเอกสารตามความหมาย และในที่สุดก็ได้บล็อกเอกสารที่ใช้ภาษา
"จําลองการแยกข้อความตามความหมาย"
เปิดตัว "SEQ_MODEL" ที่ อ.อาลีดาโม โมเดลนี้อาศัยหน้าต่างเลื่อนแบบ BERT+ โดยทํานายว่าประโยคหลังการแยกชิ้นส่วนเป็นกรอบของย่อหน้าหรือไม่
ข้อความไปยังเชิงปริมาณ: เลือกแบบจําลอง Embedding
โมเดล BBA ของหัวเว่ย (Bedge-base-zh) หรือเลือกจากแบบอย่าง MTEB
จัดเก็บค่าปริมาณ
-
Fais: การใช้งานส่วนตัว
-
Milvus: ระดับการผลิต
หาจุดความรู้ที่ตรงกันตามการใช้คําถาม
Top_k
Fiss: ค้นหาส่วนขยายใกล้ผลการค้นหาเพื่อให้ได้เอกสารที่ใกล้เคียงกันน้อยกว่า chunk_ size (ทั่วไปคือ 500 คํา)
Milvus: topk รับข้อมูล "bge-base-zh" ย่อหน้าคล้ายกัน แบบจําลองการรวมตัว
ความคิด : วิเคราะห์ความคิดการรับส่วนขยายจาก topk การรับข้อมูล เราพบว่าส่วนใหญ่แล้ว ส่วนใหญ่จะเพิ่มลูกเล่นในการตอบด้วยการขยายขอบเขตของภาษา เพื่อให้โมเดลขนาดใหญ่ได้ข้อมูลที่เป็นประโยชน์มากที่สุดในการตอบ
แนวคิด:
- เริ่มจากการแยกชิ้นส่วนเอกสารเป็นระดับประโยค โดยใช้กฎในการแยกเอกสาร
- จากนั้นใช้แบบจําลองเพื่อผนวกรวมบล็อกเอกสารตามความหมาย และในที่สุดก็ได้บล็อกเอกสารที่ใช้ภาษา
- การรวมรุ่นการใช้ข้อความ embedding ของเอกสารตามลําดับอีกครั้งตามความเหมือนของภาษา เทียบเท่ากับการรวมเอกสารในระดับประโยคเดิม 2 ครั้ง ด้วยวิธีการที่แตกต่างกัน
สร้าง Prompt
你现在是一个智能助手了,现在需要你根据已知内容回答问题
已知内容如下:
"{context}"
通过对已知内容进行总结并且列举的方式来回答问题:"{question}",在答案中不能出现问题内容,并且不允许编造内容,并且使用简体中文回答。
如果该问题和已知内容不相关,请回答 "根据已知信息无法回答该问题" 或 "没有提供足够的相关信息"。
สร้างคําตอบ: เลือก LLM
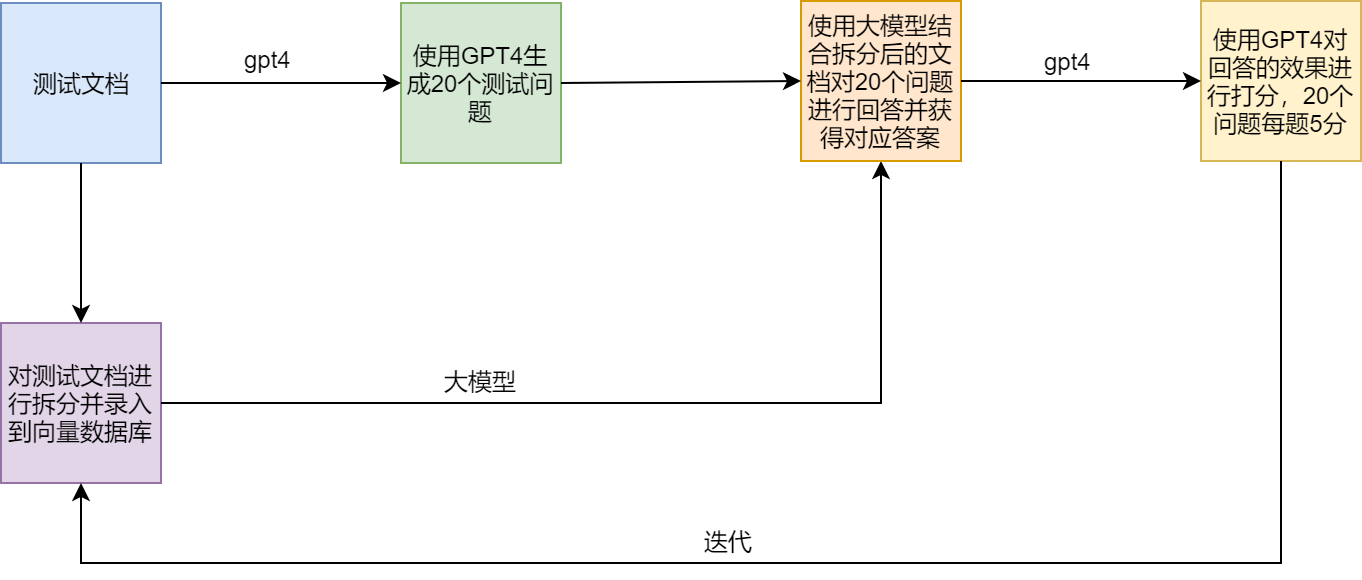
ชุดทดสอบ
จุดเจ็บและทางออกของ RAG

ตัวอย่าง
LamaIndex官方提供了一个范例(SEC Insights),用来展示高级查询技术