LlamaquaCity in Ontario Canada
HTML ve DaktiScript sürümü
Belgelerin çevik versiyonu daha eksiksiz, TS nispeten zayıf mı?
Giriş
Bir ortam oluştur
conda create --name llamaindex python=3.9.19
conda activate llamaindex
** Conda ortamını VScode'da ayarla **
Python: Select Interpreter
Kurulum kütüphanesi
pip install llama-index pypdf sentence_transformers
OpenAI' ı Yapılandır
vim ~/.bashrc
Çevre değişkeni ekle
export OPENAI_API_KEY="sk-xxxx"
Doğrulama
echo $OPENAI_API_KEY
** Her şey yolunda **
Yapılandır: Komut satırında Go proxy
Hızlı Başlangıç
import os.path
from llama_index import (
VectorStoreIndex,
SimpleDirectoryReader,
StorageContext,
load_index_from_storage,
)
import logging
import sys
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG)
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
# check if storage already exists
PERSIST_DIR = "./storage"
if not os.path.exists(PERSIST_DIR):
# load the documents and create the index
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
# store it for later
index.storage_context.persist(persist_dir=PERSIST_DIR)
else:
# load the existing index
storage_context = StorageContext.from_defaults(persist_dir=PERSIST_DIR)
index = load_index_from_storage(storage_context)
# either way we can now query the index
query_engine = index.as_query_engine()
response = query_engine.query("What did the author do growing up?")
print(response)
** Tümleme metodu kullanılır **
/chat/completions
** Sorgu parametreleri **
{
"messages": [
{
"role": "system",
"content": "You are an expert Q&A system that is trusted around the world.\nAlways answer the query using the provided context information, and not prior knowledge.\nSome rules to follow:\n1. Never directly reference the given context in your answer.\n2. Avoid statements like \"Based on the context, ...\" or \"The context information ...\" or anything along those lines."
},
{
"role": "user",
"content": "xxx"
}
],
"model": "gpt-3.5-turbo",
"stream": false,
"temperature": 0.1
}
** Sistem hızlı **
You are an expert Q&A system that is trusted around the world.
Always answer the query using the provided context information, and not prior knowledge.
Some rules to follow:
1. Never directly reference the given context in your answer.
2. Avoid statements like "Based on the context, ..." or "The context information ..." or anything along those lines.
Sen dünyanın her yerinde güvenilir bir soru ve cevap sistemisin. Sorulara cevap verirken, her zaman önceki bilgi yerine sağlanan arkaplan bilgilerini kullanın. Uyulacak bazı kurallar:
- Cevapta verilen arkaplan bilgilerine asla doğrudan atıfta bulunmayın. @ info: whatsthis
- "Arkaplan bilgilerine dayanarak..." "...kullanma,... @ info: whatsthis Ya da "Geçmişteki bilgiler gösteriyor ki..." Ya da onun gibi bir şey.
** Kullanıcı dakik **
Context information is below.
---------------------
file_path: data/paul_graham_essay.txt
xxx
---------------------
Given the context information and not prior knowledge, answer the query.
Query: What did the author do growing up?
Answer:
Uygulama Senaryosu
| 应用场 | 说明 |
|---|---|
| Q&A | 最重要 |
| Chatbots | |
| Agents | 高级 |
| Structured Data Extraction | 有用,整理聊天记录等 |
| Multi-modal |
Temel ilkeler
Temel Süreç
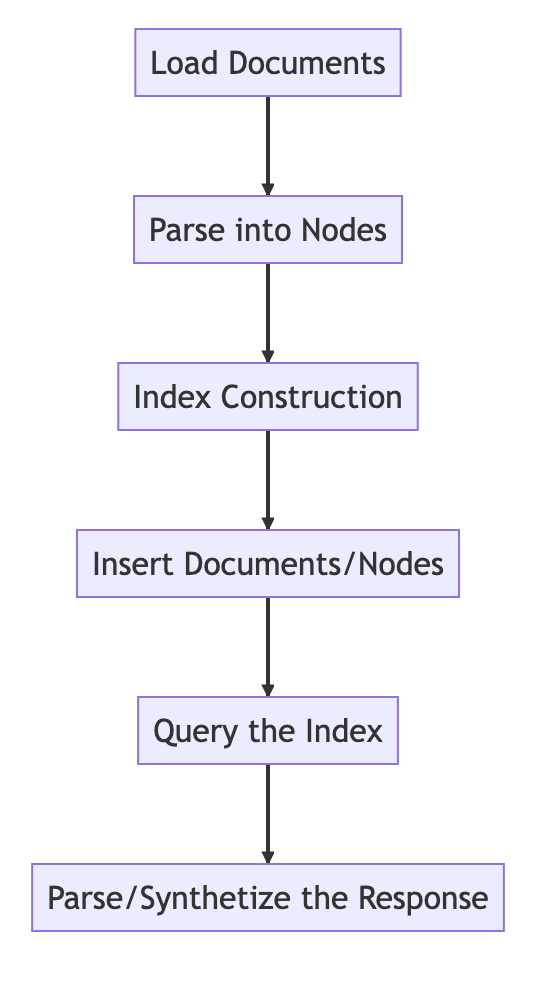
from llama_index import VectorStoreIndex, SimpleDirectoryReader
# Load in data as Document objects
documents = SimpleDirectoryReader('data').load_data()
# 切片,转成Node
# Parse Document objects into Node objects to represent chunks of data
index = VectorStoreIndex.from_documents(documents)
# Index Construction:创建索引
# Build an index over the Documents or Nodes
query_engine = index.as_query_engine()
# The response is a Response object containing the text response and source Nodes
summary = query_engine.query("What is the text about")
print("What is the data about:")
print(summary)
Chonking and NodeCity in Germany
Kaynak Veri - > Belgeler - - > Düğümler
Belgeler: Vücut ve yetkilendirme bilgileri içerir
Belge Kimliği
Belge aslında Node' un bir alt sınıfıdır
Bir dosyanın pek çok belgeye bölünmesi garip.
TextNode: Çoklu Note' yi kesmek için NodeParser' ı kullan@ info: whatsthis
Belge Kimliği İçerir
Node ve Node arasında bir bağlantı vardı
- NodeParser belge nesnelerinin bir listesini alır
- Spacy'nin cümle segmentasyonu kullanılarak, her belgenin metni cümlelere bölünür.
- Her cümle bir düğümü temsil eden bir TextNode nesnesine sarılır.
- TextNode cümle metninin yanı sıra belge kimliği, belgedeki konum, vb. gibi metinleri içerir.
- TextNode nesnelerinin bir listesini gönderir. @ info: whatsthis
Belgeyi ve indeksi kaydet
İki şekilde
- Yerel diske kaydet
- Storage'dan Vektör veritabanına
** Yerel diske kaydet **
import os.path
from llama_index import (
VectorStoreIndex,
SimpleDirectoryReader,
StorageContext,
load_index_from_storage,
)
import sys
# check if storage already exists
PERSIST_DIR = "./storage"
if not os.path.exists(PERSIST_DIR):
# 保存数据: Load the documents and create the index
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
# store it for later
index.storage_context.persist(persist_dir=PERSIST_DIR)
else:
# 从磁盘加载回数据: load the existing index
storage_context = StorageContext.from_defaults(persist_dir=PERSIST_DIR)
index = load_index_from_storage(storage_context)
query_engine = index.as_query_engine()
response = query_engine.query("What did the author do growing up?")
print(response)
Bir indeks oluştur
Her Node için bir içerik oluştur@ info: whatsthis
Doktor Stroremberg'de bir indeks oluştur@ info: whatsthis
- Doktor Storeschild için, düğüme yerleştirilen metin Faiss endeksinde depolanır, ve makroekonomik arama hızlı bir şekilde düğüm üzerinde yapılabilir.
- Endeks, belge kimliği, konum, vb. gibi her düğümün de koordinasyonunu depolar.
- Bir düğüm bir belgenin içeriğini ya da özel bir belgeyi geri alabilir.
Sorgu indeksi
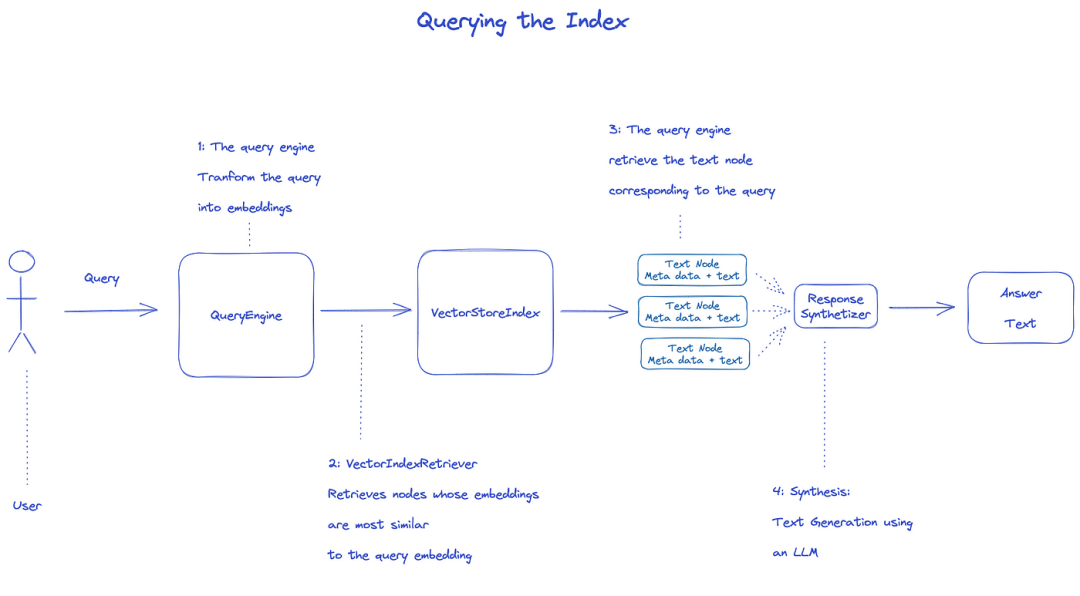
İndeksi sorgulamak için, AlyEngine kullanılacaktır.
- UNICEF sorgunun indeksinden ilgili düğümleri alır. @ info: whatsthis Örneğin, DoctorIndexissis, düğümün en çok sorgu aktarımına benzer olduğu düğümü geri alır. NAME OF TRANSLATORS
- Alınan düğümlerin listesi son çıktıyı oluşturmak için MouseSynthesizer'a geçirilir. @ info: whatsthis
- Öntanımlı olarak, her düğüm dizicini, her düğüm LLM API olarak adlandırır.
- LLM girdileri sorgu ve düğüm metni son çıktıyı almak için
- Bu düğümlerin her birinden gelen yanıtlar son çıktı dizgisine toplanmıştır.
from llama_index import (
VectorStoreIndex,
get_response_synthesizer,
)
from llama_index.retrievers import VectorIndexRetriever
from llama_index.query_engine import RetrieverQueryEngine
from llama_index.postprocessor import SimilarityPostprocessor
from llama_index import StorageContext, load_index_from_storage
# rebuild storage context
storage_context = StorageContext.from_defaults(persist_dir="storage")
# load index
index = load_index_from_storage(storage_context)
# configure retriever
retriever = VectorIndexRetriever(
index=index,
similarity_top_k=10,
)
# configure response synthesizer
response_synthesizer = get_response_synthesizer()
# assemble query engine
query_engine = RetrieverQueryEngine(
retriever=retriever,
response_synthesizer=response_synthesizer,
node_postprocessors=[SimilarityPostprocessor(similarity_cutoff=0.7)],
)
# query
response = query_engine.query("What did the author do growing up?")
print(response)
Resmi belge: Anlayış
** Veri işlemenin üç süreci **
Dünya'daki veri temizleme/özellik mühendislik altprogramları ya da geleneksel veri ayarında ETL boru hatları.
Bu sindirim boru hattı tipik olarak üç ana safhadan oluşur:
- Verileri yükle
- Veriyi Dönüştür
- Endeksle ve veriyi sakla
Veri Yükle (Alım)
** Hedef:** Çeşitli veri türlerini 'Not' nesnelerine biçimlendirin.
** Girdi:** Çeşitli veri türleri
** Çıktı:** 'Not' cismi
** Üç yol **
- 'Düzensel Okuyucu Sınıfı'nı kullan: en uygunu: @ info: whatsthis
- 'Llamade'de 'Okuyucu': Yazılan çeşitli araç gereçleri: @ info: whatsthis
- 'Dosya'yı doğrudan oluşturun.
** 'ReastleDirectory Reader' sınıfı **
from llama_index import SimpleDirectoryReader
documents = SimpleDirectoryReader("./data").load_data()
Markdown, PDFs, kelime belgeleri (.docx), PowerPoint güverteleri, resimler (.jpg,.png), ses ve video desteği
** Llamahub **
- Notion (
NotionPageReader) - Google Docs (
GoogleDocsReader) - Slack (
SlackReader) - Discord (
DiscordReader) - Apify Actors (
ApifyActor). Can crawl the web, scrape webpages, extract text content, download files including.pdf,.jpg,.png,.docx, etc.这个可以爬虫
** Doküman oluştur **
from llama_index.schema import Document
doc = Document(text="text")
Veriyi Dönüştür (dönüşmeler)
** Sebep:** LLM'nin uygun geri alma ve verimli kullanımı
** Özel operasyonlar **
- Parça 'Chunking' (chunking)
- XML' i çıkar (Spectator) Name -Gönderiliyor.
** Girdi:** 'Node'
** Çıktı:** 'Node'
Eklentili API@ info: whatsthis
'Doctor StoreExx' yöntemini kullan () @ info: whatsthis
from llama_index import VectorStoreIndex
vector_index = VectorStoreIndex.from_documents(documents)
vector_index.as_query_engine()
** Parametreleri nasıl özelleştiririm **
Fikir: Özelleştirmek için 'ServiceControl' kullan
text_splitter = SentenceSplitter(chunk_size=512, chunk_overlap=10)
service_context = ServiceContext.from_defaults(text_splitter=text_splitter)
index = VectorStoreIndex.from_documents(
documents, service_context=service_context
)
Atomik API
Standart Kullanım kipi
from llama_index import Document
from llama_index.embeddings import OpenAIEmbedding
from llama_index.text_splitter import SentenceSplitter
from llama_index.extractors import TitleExtractor
from llama_index.ingestion import IngestionPipeline, IngestionCache
# 加载数据源
documents = SimpleDirectoryReader("./data").load_data()
# 创建转换数据的工作流
# create the pipeline with transformations
pipeline = IngestionPipeline(
transformations=[
SentenceSplitter(chunk_size=25, chunk_overlap=0), # 分片
TitleExtractor(), # 提取Meta信息
OpenAIEmbedding(), # Embedding
]
)
# 执行流程,生成节点
# run the pipeline
nodes = pipeline.run(documents=documents)
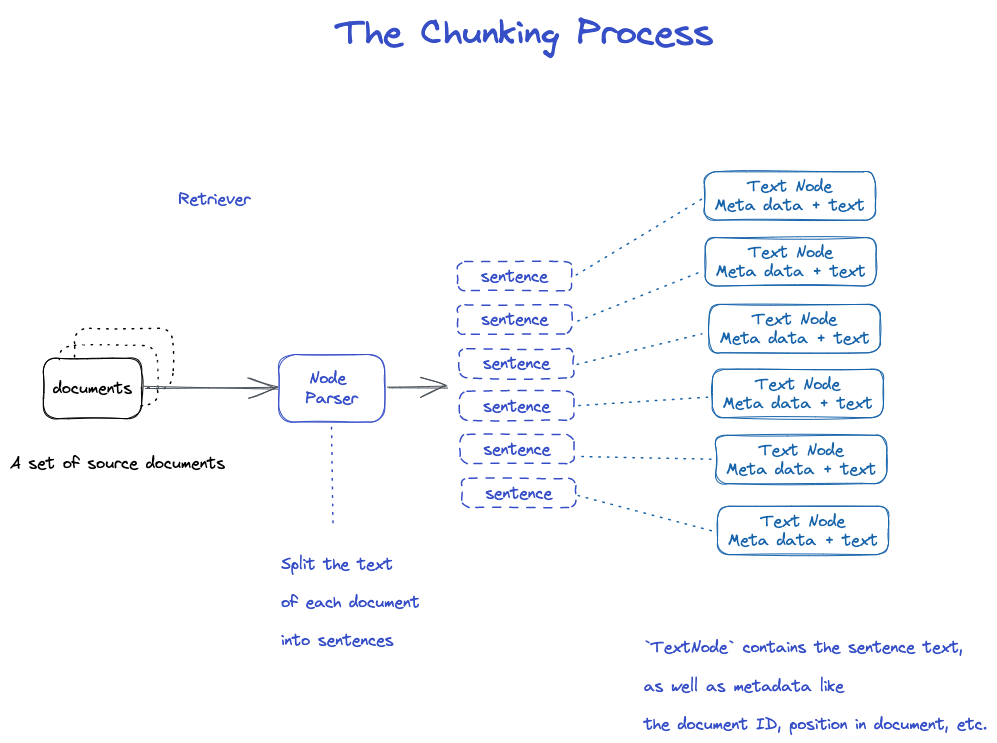
Dilim@ info: tooltip
Node Parser modülünde belirtildiği gibi birçok strateji vardır.
Araç Çubuğu Ekle
K3b eklemek için belge ve Node' ı özelleştirebilirsiniz. @ info: whatsthis
Doğrudan bir Node nesnesi oluştur@ info: whatsthis
from llama_index.schema import TextNode
node1 = TextNode(text="<text_chunk>", id_="<node_id>")
node2 = TextNode(text="<text_chunk>", id_="<node_id>")
index = VectorStoreIndex([node1, node2])
İndeks
** Her şey yolunda **
** Ortak indeksler **
- NAME OF TRANSLATORS
- Vector Tore Terrace (en yaygın) @ info: whatsthis
- Ağaç Tasarrufları
- Anahtar Kelime Tablosu Araç Çubuğu
** X-Men (eski adı: list 2.0) **

** Vector Store X-Men **

** Ağaç parçaları **

** Anahtar kelime tabloları **

-
https: / docs.llamaindex.ai/en/stable/ modül_ rehberler/ chat_ chat_ html)
NASCARName
Araç Çubuğu Ekle
document.metadata['lang'] = lang
Filtrele
from llama_index.core.vector_stores import (
ExactMatchFilter,
MetadataFilters,
MetadataFilter,
)
filters = MetadataFilters(
filters=[
MetadataFilter(key="post_year", value="2017"),
],
)
# You pass filter as an argument. You can have any type of filter
# we saw above and then pass it to query engine.
query_engine = index.as_query_engine(service_context=service_context,
similarity_top_k=5,
filters = filters,
response_mode='tree_summarize')
response = query_engine.query("Marathon Running")
print(response)
Yanıt Araç Çubuğu
- Refine: Bağlamlı yanıtları tek tek oluştur; önce metin_Qa şablon şablonunu kullan, ve sonra refin_ şablonu kullan. @ info: whatsthis
- Kompakt: Öntanımlı. Ancak reçineye benzer bir bağlam bir istekle örtüşüyor.
- Ağaç
- Basit_ XMLGenericName
Kaynak Kod
Belge
'Edment' bir 'Node'nin alt sınıfıdır)
İçerir:
-
Metin
-
"Metadata"
-
'Odalık': Diğer dokümanlarla/ düğümlerle ilişki
** Atomik kullanım süreci **
from llama_index import Document, VectorStoreIndex
# 数据源
text_list = [text1, text2, ...]
# 手动创建documents
documents = [Document(text=t) for t in text_list]
# 建立索引: 传入document,在VectorStoreIndex再转换:分片转成Node,Embedding等
index = VectorStoreIndex.from_documents(documents)
Belge oluşturmanın çeşitli yöntemleri
** Elle yarat **
from llama_index import Document
text_list = [text1, text2, ...]
documents = [Document(text=t) for t in text_list]
** Veri aktarımını kullan (bağlayıcı) / @ info: whatsthis
Hepsinde bir yöntem yüklemesi_ data () var ()
from llama_index import SimpleDirectoryReader
documents = SimpleDirectoryReader("./data").load_data()
** Otomatik olarak oluşturulmuş örnek veri **
document = Document.example()
Özel Araç Çubuğu
from llama_index import Document
from llama_index.schema import MetadataMode
document = Document(
text="This is a super-customized document",
metadata={
"file_name": "super_secret_document.txt",
"category": "finance",
"author": "LlamaIndex",
},
excluded_llm_metadata_keys=["file_name"],
metadata_seperator="::",
metadata_template="{key}=>{value}",
text_template="Metadata: {metadata_str}\n-----\nContent: {content}",
)
print(
"The LLM sees this: \n",
document.get_content(metadata_mode=MetadataMode.LLM),
)
print()
print(
"The Embedding model sees this: \n",
document.get_content(metadata_mode=MetadataMode.EMBED),
)
Çıktı
The LLM sees this:
Metadata: category=>finance::author=>LlamaIndex
-----
Content: This is a super-customized document
The Embedding model sees this:
Metadata: file_name=>super_secret_document.txt::category=>finance::author=>LlamaIndex
-----
Content: This is a super-customized document
Çıkarma şablonu (anlamıyorum) @ info: whatsthis
Düğüm
Özen: Belgenin parçalanması
Nasıl elde edilir:
- Belgeyi Node' a dönüştürmek için NodeParser sınıfını kullan@ info: whatsthis
- Elle oluştur
Belge gibi:
-
Metin
-
"Metadata"
-
'Odalık': Diğer dokümanlarla/ düğümlerle ilişki
Belgeden Node'a dönüştürüldüğünde, K3b gibi bilgiler miras kalır.
Düğüm Llamaduke'da birinci sınıf bir vatandaş.
** Atomik kullanım süreci **
from llama_index.node_parser import SentenceSplitter
# load documents
...
# 手动转换:切片,转成Node
# parse nodes
parser = SentenceSplitter()
nodes = parser.get_nodes_from_documents(documents)
# build index
index = VectorStoreIndex(nodes)
** İlişki kur **
from llama_index.schema import TextNode, NodeRelationship, RelatedNodeInfo
node1 = TextNode(text="text_chunk1", id_="node_id1")
node2 = TextNode(text="text_chunk2", id_="node_id2")
node3 = TextNode(text="text_chunk3", id_="node_id3")
# set relationships
node1.relationships[NodeRelationship.NEXT] = RelatedNodeInfo(
node_id=node2.node_id
)
node2.relationships[NodeRelationship.PREVIOUS] = RelatedNodeInfo(
node_id=node1.node_id
)
node2.relationships[NodeRelationship.PARENT] = RelatedNodeInfo(
node_id=node3.node_id, metadata={"key": "val"}
)
print(node2)
Ayrıştırmacı@ info: whatsthis
Amaç: Veri kaynaklarını Node nesnelerine dönüştür
Spesifik: Bir belge nesne grubunu çoklu Node nesnelerine ayır@ info: whatsthis
Ortak somut uygulama
NodeParser, aşağıdaki gibi uygulanan soyut bir sınıftır:
** Dosya tipine göre **
- Özel Dosya Ayrıştırıcısı
- ISO MLNodeParkserGenericName
- JSONNODEBER
- MarkdownNode Ayrıştırıcı
** Metin segmentasyonu **
- CodeSplaughCity in Ontario Canada
- Langlois NodeParserCity in Ontario Canada
- SentenceSplund.
- Sentence Windowower Parlatıcı (anlamıyorum) @ info: whatsthis
- SemanticSplitterNodeser (anlamıyorum, daha gelişmiş hissettiriyor)
- TokenTextSpringCity in Newfoundland Canada
** Baba - oğul ilişkisi **
- Hierarşikal NodeParser: OtoMergings'de kullanılır. @ info: whatsthis
Tipik Kullanım
** Atomik kullanım **
from llama_index import Document
from llama_index.node_parser import SentenceSplitter
# 创建NodeParser
node_parser = SentenceSplitter(chunk_size=1024, chunk_overlap=20)
# 调用 get_nodes_from_documents() 方法
# show_progress 可以显示进度
nodes = node_parser.get_nodes_from_documents(
[Document.example(), Document.example()], show_progress=True
)
print(len(nodes))
print()
print(nodes[0])
Çıktı
2
Node ID: eaeb6e44-6828-4e36-b7a3-69342de4dc7c
Text: Context LLMs are a phenomenal piece of technology for knowledge
generation and reasoning. They are pre-trained on large amounts of
publicly available data. How do we best augment LLMs with our own
private data? We need a comprehensive toolkit to help perform this
data augmentation for LLMs. Proposed Solution That's where LlamaIndex
comes in. Ll...
** Dönüşümler ** pigmentlerde*
from llama_index import Document
from llama_index.node_parser import SentenceSplitter
from llama_index.ingestion import IngestionPipeline
from llama_index.node_parser import TokenTextSplitter
documents = [Document.example(), Document.example()]
# 创建NodeParser
node_parser = SentenceSplitter(chunk_size=1024, chunk_overlap=20)
# 将NodeParser放到Pipeline中的transformations列表
pipeline = IngestionPipeline(transformations=[node_parser])
nodes = pipeline.run(documents=documents)
print(len(nodes))
print()
print(nodes[0])
** ServiceContext kullan **
from llama_index import Document, ServiceContext, VectorStoreIndex
from llama_index.node_parser import SentenceSplitter
from llama_index.ingestion import IngestionPipeline
from llama_index.node_parser import TokenTextSplitter
documents = [Document.example(), Document.example()]
node_parser = SentenceSplitter(chunk_size=1024, chunk_overlap=20)
service_context = ServiceContext.from_defaults(text_splitter=node_parser)
index = VectorStoreIndex.from_documents(
documents, service_context=service_context, show_progress=True
)
Dönüşümler
Girdi: Bir Node seti
Çıktı: Bir Node seti
İki ortak yol vardır:
- Evet, evet, evet.
- Senkronize.
NodeParser ve 'Audata Extractor' transformasyonlara ait. @ info: whatsthis
** Kullanım modu **
from llama_index.text_splitter import SentenceSplitter
from llama_index.extractors import TitleExtractor
node_parser = SentenceSplitter(chunk_size=512)
extractor = TitleExtractor()
# use transforms directly
nodes = node_parser(documents)
# or use a transformation in async
nodes = await extractor.acall(nodes)
** ServiceContext ile birleşti **
from llama_index import ServiceContext, VectorStoreIndex
from llama_index.extractors import (
TitleExtractor,
QuestionsAnsweredExtractor,
)
from llama_index.ingestion import IngestionPipeline
from llama_index.text_splitter import TokenTextSplitter
transformations = [
TokenTextSplitter(chunk_size=512, chunk_overlap=128),
TitleExtractor(nodes=5),
QuestionsAnsweredExtractor(questions=3),
]
# 创建ServiceContext,传入Transfrmation
service_context = ServiceContext.from_defaults(
transformations=[text_splitter, title_extractor, qa_extractor]
)
# 传入VectorStoreIndex的from_documents()或insert()方法
index = VectorStoreIndex.from_documents(
documents, service_context=service_context
)
ServiceContextName
Llamagado boru hattı üzerinde kullanılan bir tomar hizmet ve yeniden yapılanmalar.
** Yayılabilir **
from llama_index import (
ServiceContext,
OpenAIEmbedding,
PromptHelper,
)
from llama_index.llms import OpenAI
from llama_index.text_splitter import SentenceSplitter
# 设置LLM
llm = OpenAI(model="text-davinci-003", temperature=0, max_tokens=256)
# 设置Embedding模型
embed_model = OpenAIEmbedding()
# 设置Chunk的大小
text_splitter = SentenceSplitter(chunk_size=1024, chunk_overlap=20)
prompt_helper = PromptHelper(
context_window=4096,
num_output=256,
chunk_overlap_ratio=0.1,
chunk_size_limit=None,
)
service_context = ServiceContext.from_defaults(
llm=llm, # 设置LLM
embed_model=embed_model, # 设置Embedding模型
text_splitter=text_splitter, # 设置Chunk的大小
prompt_helper=prompt_helper,
)
** Constructor parametreleri ** (daha uygun)
** Düğüm ayrıştırıcısı için Kwang'lar için **
- 'Chunk_size'
- Kütleler örtüşüyor.
** Hızlı yardımcılar için Kwarg'lar **
- "Pencere": "Pencere":
- "Gidelim"
Örneğin...
service_context = ServiceContext.from_defaults(chunk_size=1000)
** Küresel yapılandırma **
from llama_index import set_global_service_context
set_global_service_context(service_context)
** Lokal yapılandırma **
query_engine = index.as_query_engine(service_context=service_context)
Stormage ContextName
Belgelerin, indekslerin ve indekslerin nerede depolandığını belirler. @ info: whatsthis
[API Reference] (https: / docs.llamaindex.ai/en/stable/API_ Referans/)
store = PGVectorStore(
connection_string=conn_string,
async_connection_string=async_conn_string,
schema_name=PGVECTOR_SCHEMA,
table_name=PGVECTOR_TABLE,
)
index = VectorStoreIndex.from_vector_store(store)
Doktor StorevallCity in Ontario Canada
Bağlayıcı Fonksiyonu
index = VectorStoreIndex.from_vector_store(store)
İki tür motor vardır:
- Query Engine: BaseQueryEngine
- Chat Engines: BaseChatEngine
Motor Oluştur
index.as_query_engine()# BaseQueryEngine
index.as_query_engine(streaming=True)# 流式 BaseQueryEngine
index.as_chat_engine() # BaseChatEngine; 流式不是在这里控制
Sorgu
# Query
response = await query_engine.aquery(query) # 流式
response = await query_engine.aquery(query)
# Chat
response = await chat_engine.astream_chat(last_message_content, messages) # 流式在这里控制
response = await chat_engine.achat(last_message_content, messages)
Dilbilgisi@ info: whatsthis
Sorgu
Balıkçılık
XML ChatEngine
- Sohbet
- stream_ chat
- AchtGenericName
- astream_ chat
Akımı destekler: dere
Asenkron desteklenmektedir: A ile başlayan
Yanıt tipi
# Query
RESPONSE_TYPE = Union[
Response,
StreamingResponse, AsyncStreamingResponse, #流式
PydanticResponse
]
# Chat
StreamingAgentChatResponse #流式
AGENT_CHAT_RESPONSE_TYPE = Union[AgentChatResponse, StreamingAgentChatResponse] #非流式
Yayınsız tepkiyle nasıl başa çıkılır
K3b' nin standart API' lerini kullan:
- StreamingForse ()
- AsyncStreamingForse
- StreamingForseGenericName
- Sorgu.
@r.post("")
async def chat(
request: Request,
queryData: _QueryData,
query_engine: BaseQueryEngine = Depends(get_query_engine_stream),
):
query = queryData.query
streaming_response = await query_engine.aquery(query)
async def event_generator():
async for token in streaming_response.async_response_gen:
if await request.is_disconnected():
break
yield f"data: {token}\n\n"
return StreamingResponse(event_generator(), media_type="text/event-stream")
- Sohbet.
@r.post("")
async def chat(
request: Request,
data: _ChatData,
chat_engine: BaseChatEngine = Depends(get_chat_engine),
):
last_message_content, messages = await parse_chat_data(data)
response = await chat_engine.astream_chat(last_message_content, messages)
async def event_generator():
async for token in response.async_response_gen():
if await request.is_disconnected():
break
yield token
return StreamingResponse(event_generator(), media_type="text/plain")
StreamingGenericName
class AsyncStreamingResponse:
async_response_gen: TokenAsyncGen
class StreamingResponse:
response_gen: TokenGen
Yanıt Araç Çubuğu
İzle ve kontrol et
Öğretmen.
Derin Öğretici
Building and Evaluating Advanced RAG Applications:链接 Bilibili
** Polaroid ve katalitik arama için ortak metin **
Bu video, tek bir birleşik sorgu arayüzüne dönüştürülen XML ve katalitik arama için Llamaduke'a inşa edilen araçları kapsar. @ info: whatsthis