Deep Eval and Confident AI
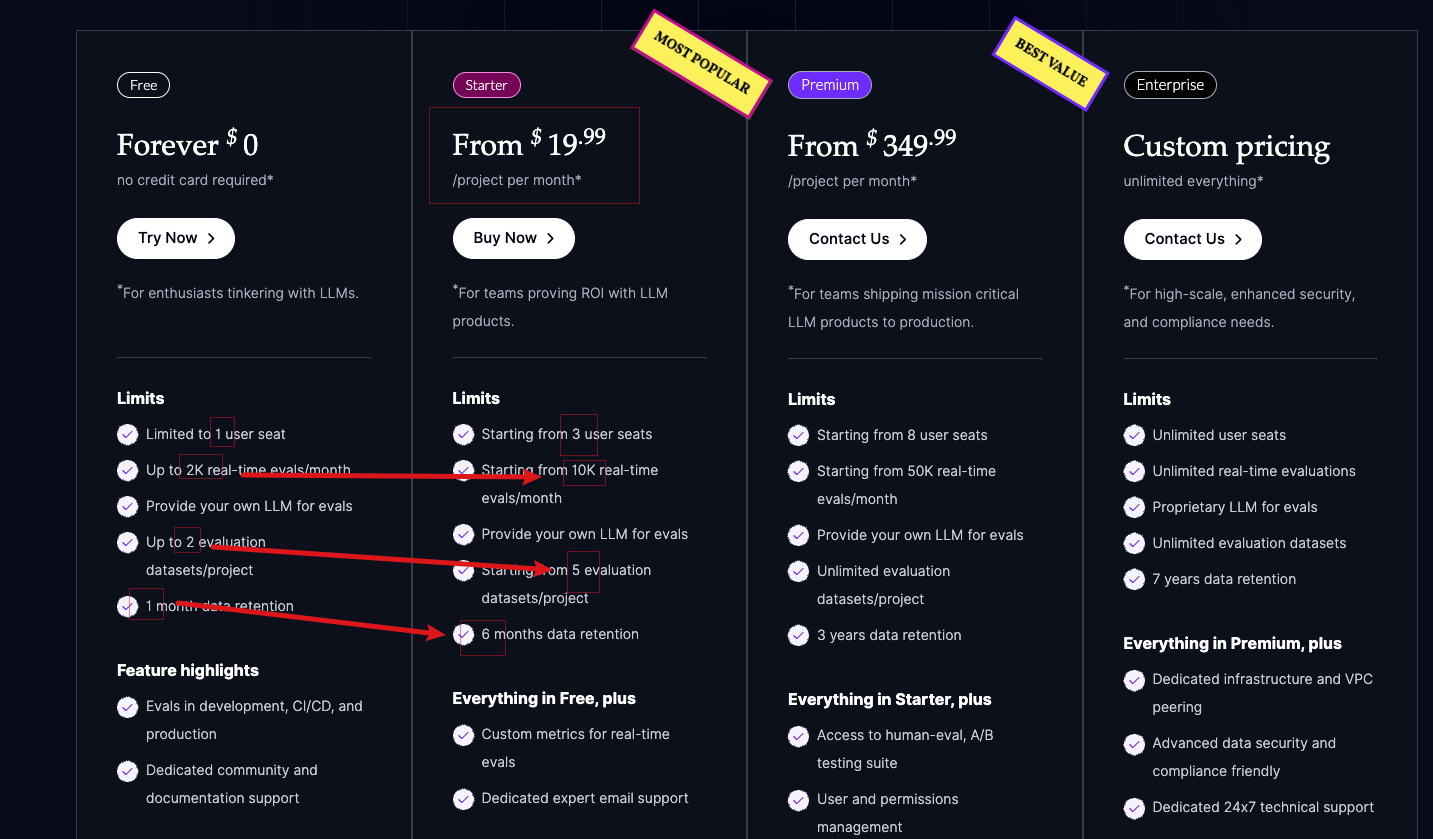
price
Free package: basically enough
Starter package: US$20/month
Quick Start
latestversion
pip install -U deepeval
Register forConfident AI
Get api key
log in
deepeval login --api-key xxxx
Create the file试验_example.py
from deepeval import assert_test
from deepeval.test_case import LLMTestCase
from deepeval.metrics import AnswerRelevancyMetric
def test_answer_relevancy():
answer_relevancy_metric = AnswerRelevancyMetric(threshold=0.5)
test_case = LLMTestCase(
input="What if these shoes don't fit?",
# Replace this with the actual output of your LLM application
actual_output="We offer a 30-day full refund at no extra cost."
)
assert_test(test_case, [answer_relevancy_metric])
The file name must begin with试验_
operation
deepeval test run test_example.py
Set the Folder in which to save results
Set Environment Variables
export DEEPEVAL_RESULTS_FOLDER="./deep-eval-results"
Parameter of deepeval试验run
parallel
deepeval test run test_example.py -n 4
cache
deepeval test run test_example.py -c
repetition
deepeval test run test_example.py -r 2
hook
...
@deepeval.on_test_run_end
def function_to_be_called_after_test_run():
print("Test finished!")
conceptual framework
| Test Case | Contains input/actual_output/retrieval_context | |
| Dataset | Collection of试验Cases | |
| Golden | Compared with the试验case, the actual_output |
An actual试验Case
test_case = LLMTestCase(
input="Who is the current president of the United States of America?",
actual_output="Joe Biden",
retrieval_context=["Joe Biden serves as the current president of America."]
)
Use Pytest for evaluation
from deepeval import assert_test
from deepeval.test_case import LLMTestCase
from deepeval.metrics import AnswerRelevancyMetric
dataset = EvaluationDataset(test_cases=[...])
@pytest.mark.parametrize(
"test_case",
dataset,
)
def test_customer_chatbot(test_case: LLMTestCase):
answer_relevancy_metric = AnswerRelevancyMetric()
assert_test(test_case, [answer_relevancy_metric])
@pytest.mark.parametrizeis a decorator provided by Pytest. Recurrence simply evaluates each test case one by one inEvaluationDataset.
Run without CLI
# A hypothetical LLM application example
import chatbot
from deepeval import evaluate
from deepeval.metrics import HallucinationMetric
from deepeval.test_case import LLMTestCase
# ……
test_cases = [first_test_case, second_test_case]
metric = HallucinationMetric(threshold=0.7)
evaluate(test_cases, [metric])
Test Case
A standard试验Case
test_case = LLMTestCase(
input="What if these shoes don't fit?", #必选
expected_output="You're eligible for a 30 day refund at no extra cost.", #必选
actual_output="We offer a 30-day full refund at no extra cost.",
context=["All customers are eligible for a 30 day full refund at no extra cost."], # 参考值
retrieval_context=["Only shoes can be refunded."], # 实际检索结果
latency=10.0
)
-
contextis the ideal search result for a given Input, Normal from the Evaluation Data Set, -retrieval_contextThe actual search results of theLLM Application.
Dataset
Manually generate a dataset and and if you do push it to Confident AI
from deepeval.test_case import LLMTestCase
from deepeval.dataset import EvaluationDataset
# 原始数据
original_dataset = [
{
"input": "What are your operating hours?",
"actual_output": "...",
"context": [
"Our company operates from 10 AM to 6 PM, Monday to Friday.",
"We are closed on weekends and public holidays.",
"Our customer service is available 24/7.",
],
},
{
"input": "Do you offer free shipping?",
"actual_output": "...",
"expected_output": "Yes, we offer free shipping on orders over $50.",
},
{
"input": "What is your return policy?",
"actual_output": "...",
},
]
# 遍历,将生成 LLMTestCase 实例
test_cases = []
for datapoint in original_dataset:
input = datapoint.get("input", None)
actual_output = datapoint.get("actual_output", None)
expected_output = datapoint.get("expected_output", None)
context = datapoint.get("context", None)
test_case = LLMTestCase(
input=input,
actual_output=actual_output,
expected_output=expected_output,
context=context,
)
test_cases.append(test_case)
# 将 LLMTestCase 数组变成 EvaluationDataset
dataset = EvaluationDataset(test_cases=test_cases)
# 推送到Confident AI
dataset.push(alias="My Confident Dataset")
view results
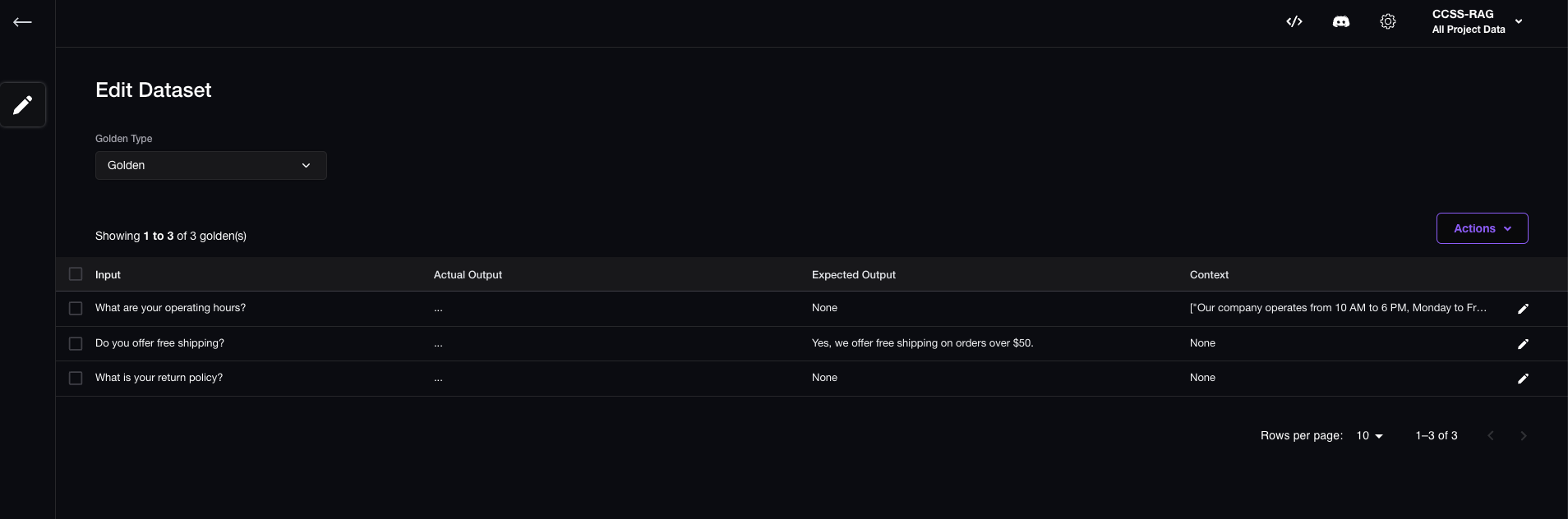
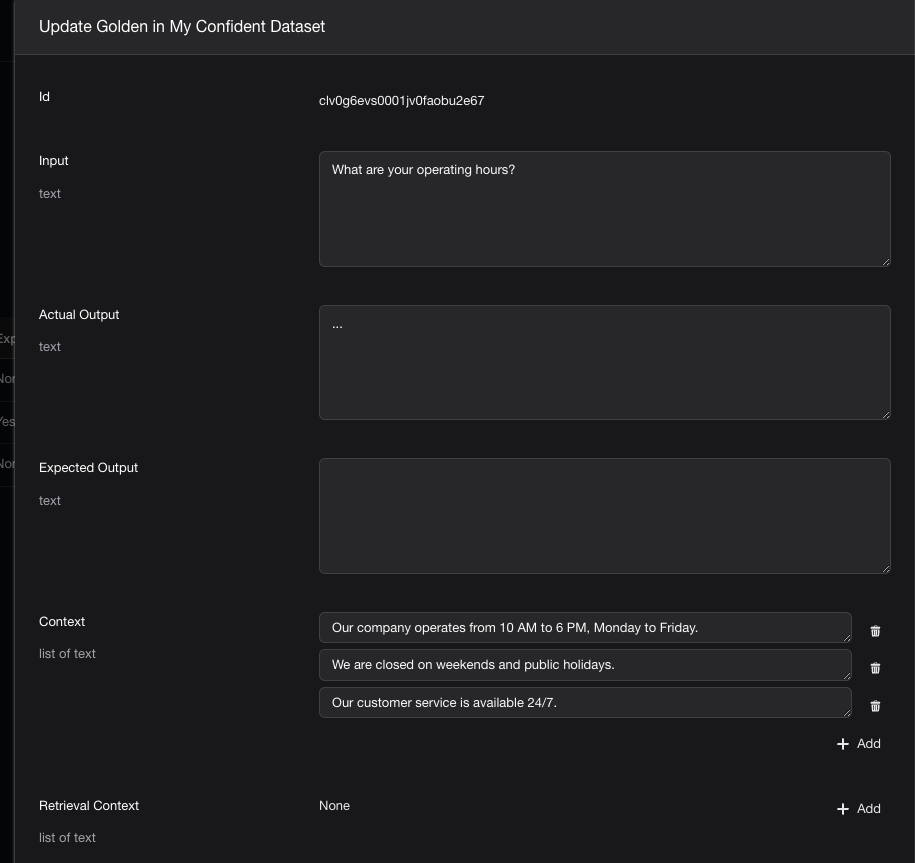
Manually createdin Confident AI's Web UI
Support test
Manually modify all Prompts under/Users/xxx/anaconda3/envs/LI311-b/lib/python3.11/site-packages/deepeval/synthesizer/template.pyand add
6. `Rewritten Input` should be in Chinse.
Metric
Dimension of Assessment
| Evaluation Metric | Description |
|---|---|
| Accuracy and Semantic Similarity | Comparison of generated answers with reference answers |
| Context Relevancy | Query correlation on retrieved context |
| Faithfulness | Consistency of generated answers with retrieved context |
| Answer Relevancy | The correlation of the generated answer on the Query |