LLM rankings and prices
ranking
| Model | grade |
|---|---|
| GPT-4-Turbo-2024-04-09 | 1258 |
| Claude 3 Opus | 1253 |
| Gemini 1.5 Pro API-0409-Preview | 1249 |
| Meta Llama 3 70b Instruct | 1213 |
| Claude 3 Sonnet | 1201 |
| Command R+ | 1192 |
| Claude 3 Haiku | 1181 |
| Mistral-Large-2402 | 1158 |
| Qwen1.5-72B-Chat | 1153 |
| Command R | 1150 |
| Mistral Medium | 1147 |
| Meta Llama 3 8b Instruct | 1147 |
| Mixtral-8x22b-Instruct-v0.1 | 1145 |
| Qwen1.5-32B-Chat | 1134 |
| GPT-3.5-Turbo-0613 | 1119 |
| Qwen1.5-14B-Chat | 1119 |
| Mixtral-8x7b-Instruct-v0.1 | 1114 |
| Yi-34B-Chat | 1109 |
| WizardLM-70B-v1.0 | 1108 |
evaluation standard
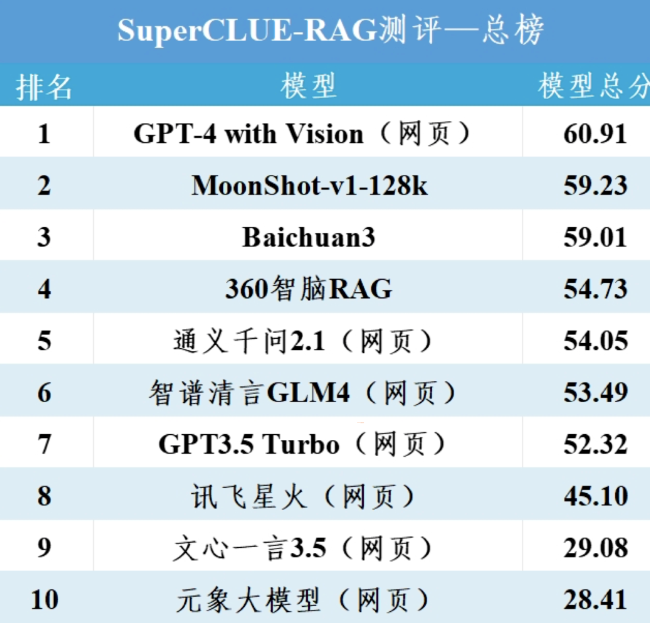
RAG score
https://mp.weixin.qq.com/s/EdoA5fcyzgTw3LarMMe00g
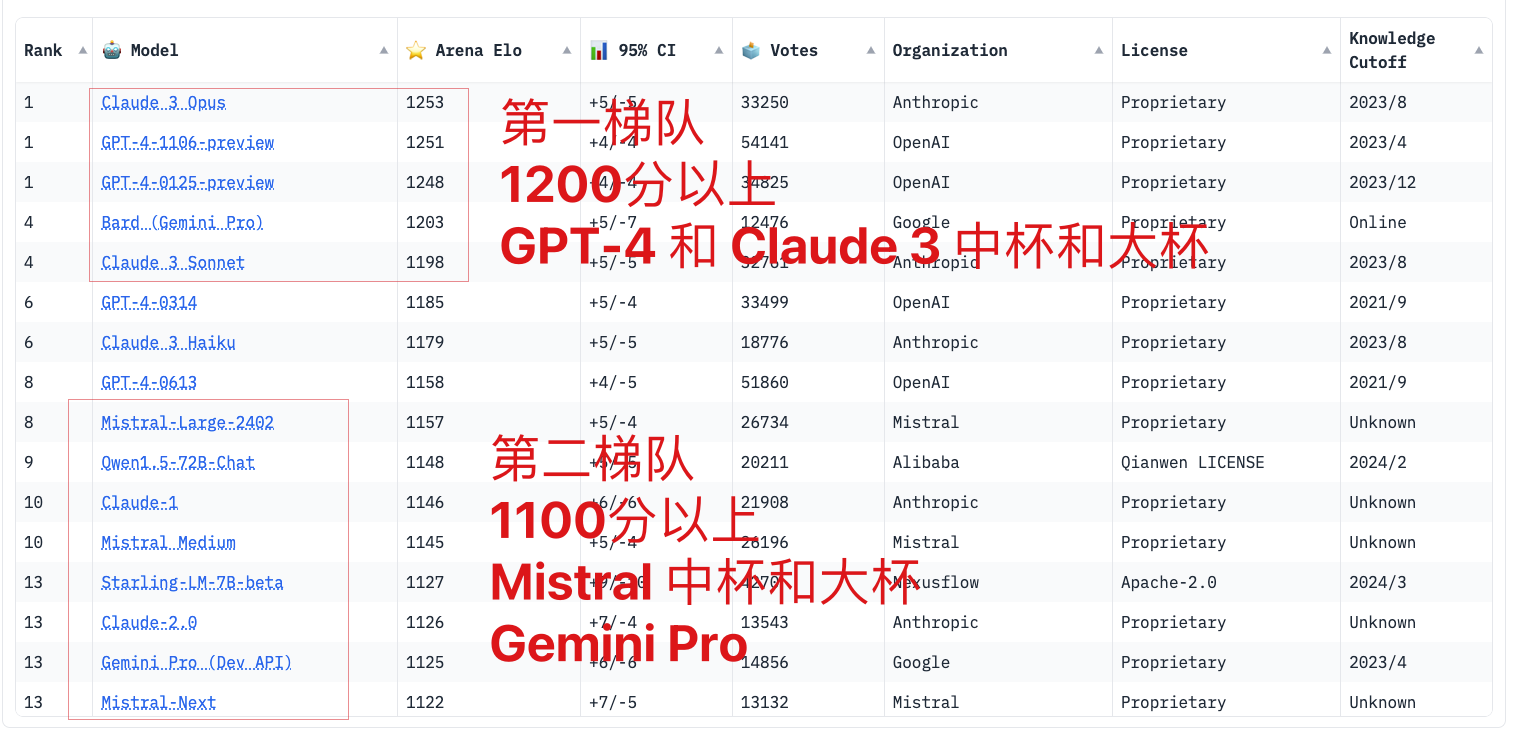
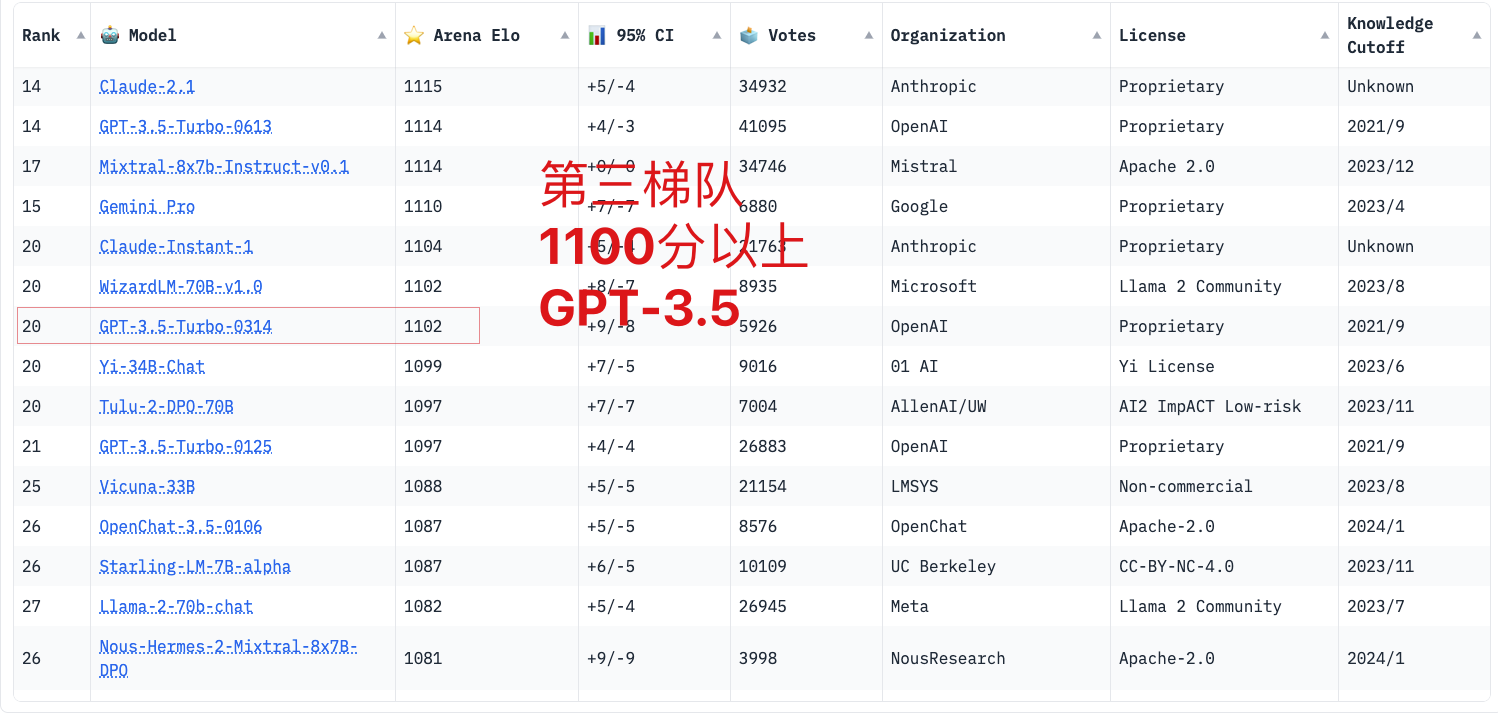
LMSYS
🏆 LMSYS Chatbot Arena Leaderboard
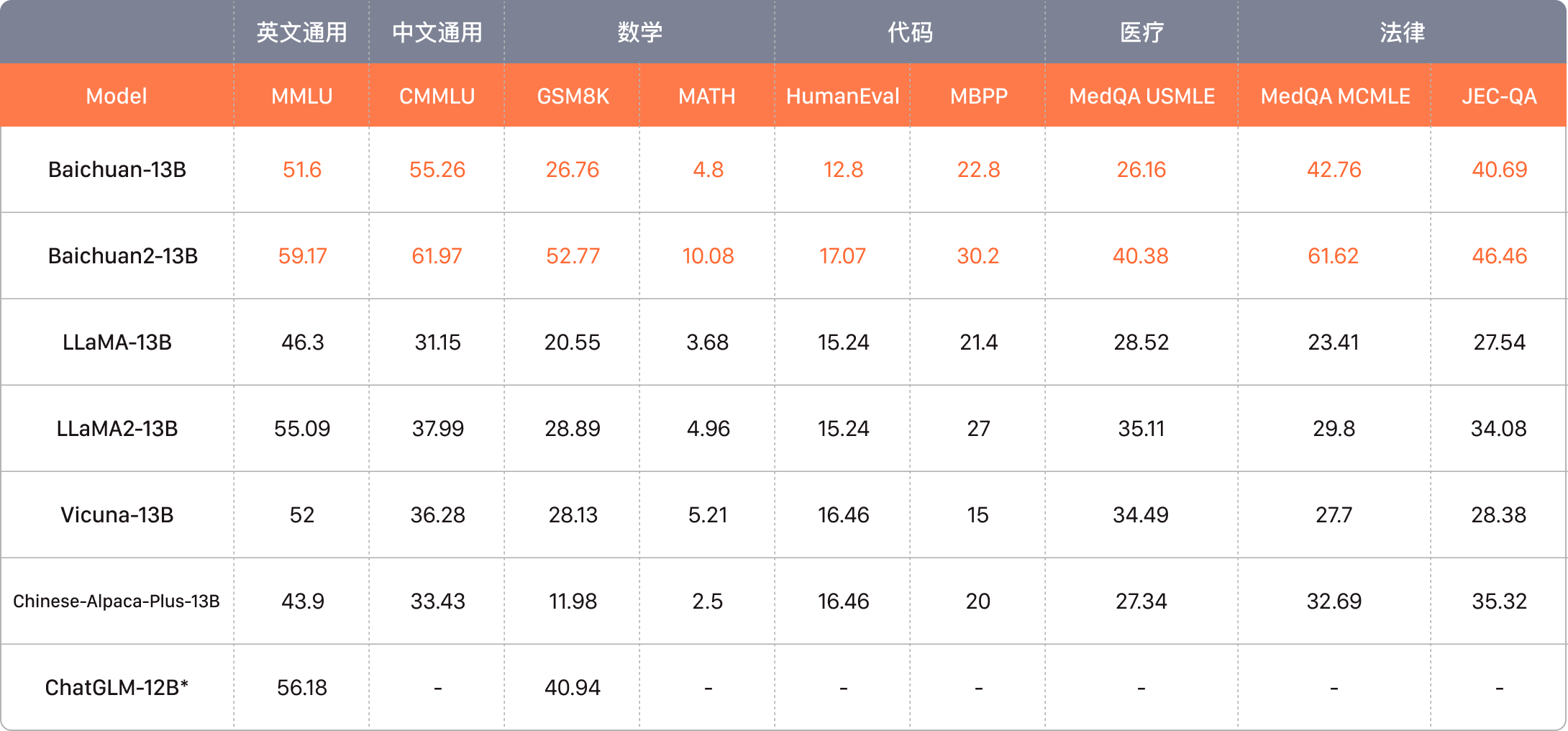
| echelon | grade | representative |
|---|---|---|
| the first echelon | Above 200 minute | GPT-4 Claude 3 medium mug and tankard |
| second echelon | Above 150 minute | Mistral medium mug and tankard Claude 3 small glasses Thousand Questions 72B |
| the third echelon | 110 minute or more | GPT-3.5 |
GPT-4 has a 12% improvement compared to GPT-3.5
Claude 3 small cup has a 6% improvement compared to GPT-3.5
CLUE test review
CLUE test language understanding evaluation Baseline
https://mp.weixin.qq.com/s/cI92Fp2ic13_BKaRSgZw4g
price
Gemini: Currently only 1.0 Pro price