Database vettoriale å
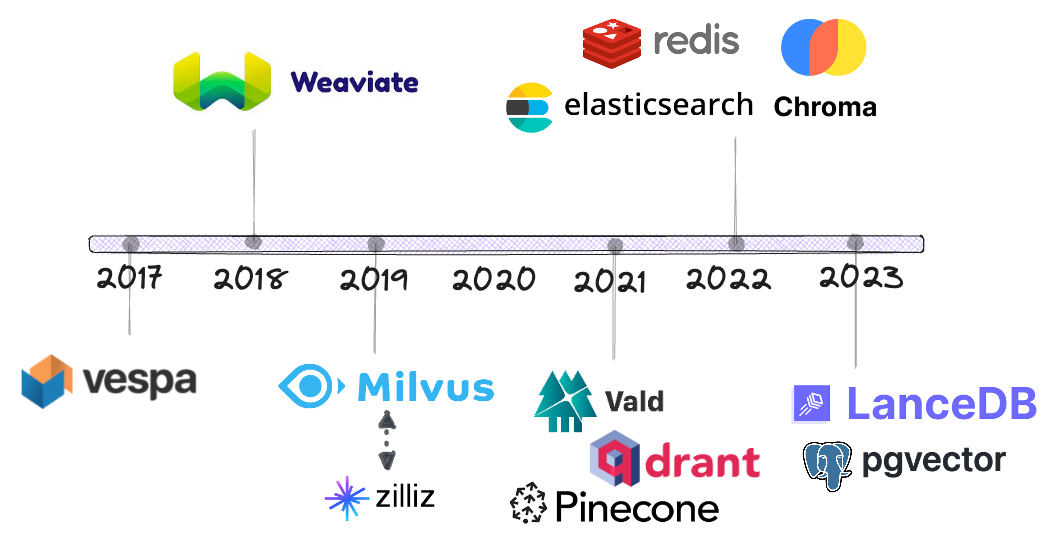
Cronologia
Vespa è uno dei primi fornitori ad aggiungere la ricerca di somiglianza vettoriale accanto al mainstream algoritmo di ricerca di parole chiave basato su BM25.
Weaviate ha poi lanciato un prodotto dedicato per la ricerca di vettori open source alla fine del 2018.
Entro il 2019, inizieremo a vedere più concorrenza in questo settore, tra cui Milvus (anche open source). Zilliz è la casa madre di Milvus.
Nel 2021, tre nuovi fornitori hanno aderito al concorso: Vald, Qdrant e Pinecone.
Fu solo allora che i fornitori stabiliti come Elasticsearch, Redis e PostgreSQL cominciarono a offrire la ricerca vettoriale, molto più tardi di quanto la gente pensasse, solo nel 2022 e dopo.
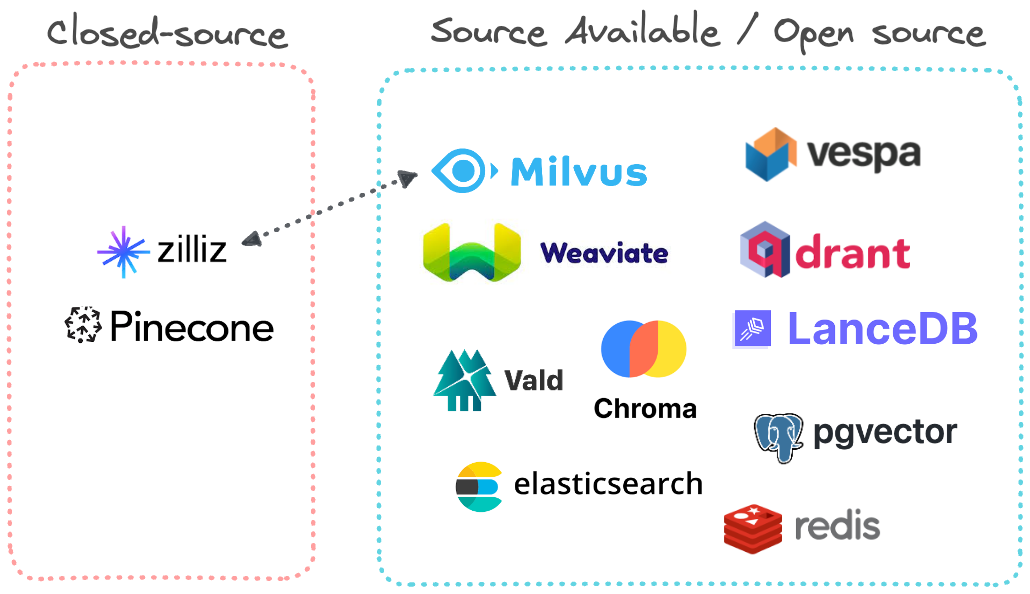
Open Source e commercio
Affari: Pinecone e Zilliz
Plug - in forma
- pgvector
- Redis Stack
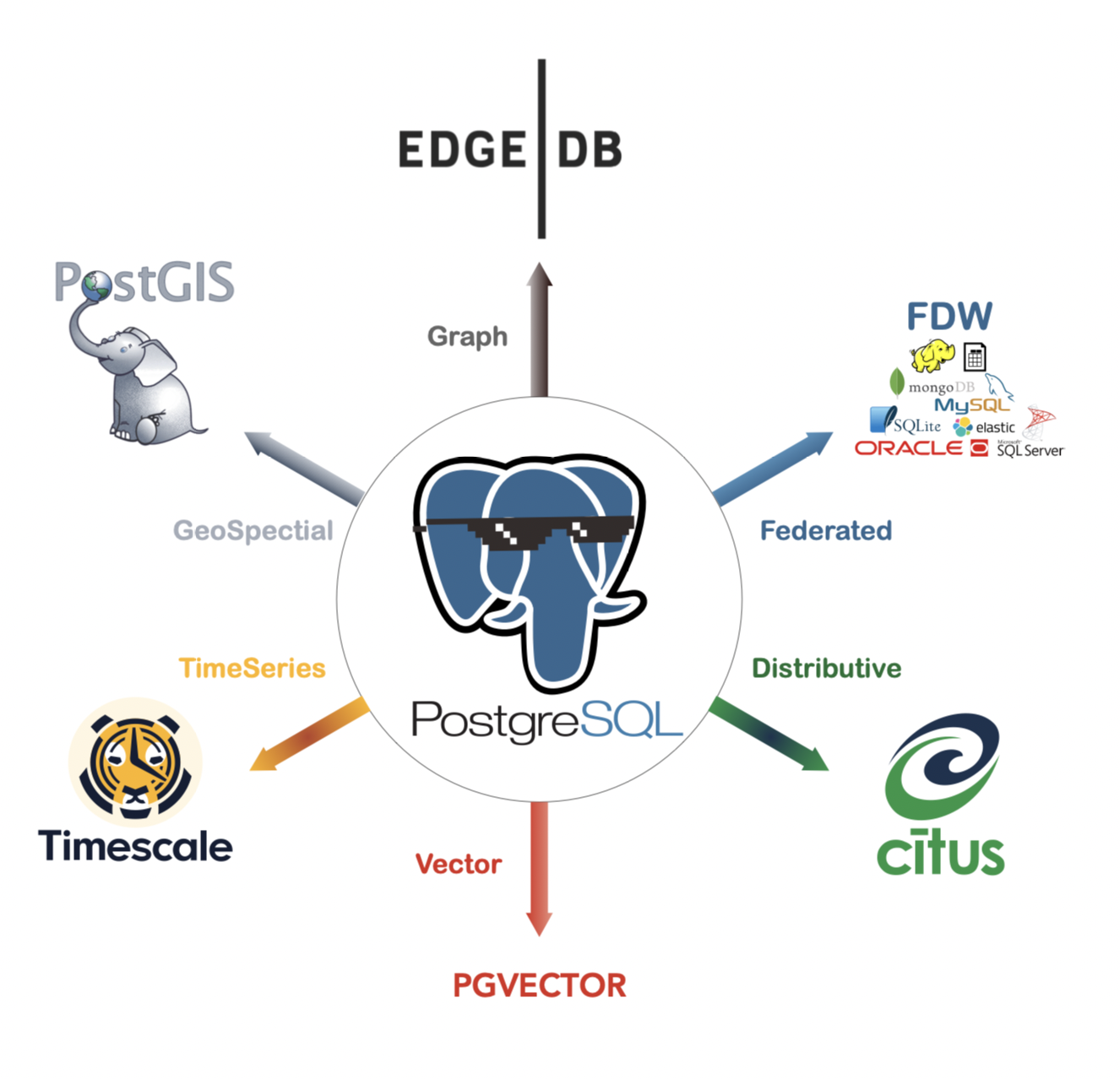
Postgres
Un database supporta anche:
- Database di relazione: RDS
- Database Vector: pgvector
- database serie temporali: il database delle serie temporali svolge un ruolo importante nel filtraggio dei metadati. Si tratta di un database che registra eventi e tempi di occorrenza, e la velocità di ricerca per le serie temporali è molto veloce. Nelle applicazioni RAG, se decine di migliaia di file di conoscenza del settore sono tagliati fuori, sarà molto importante utilizzare il filtraggio del tempo. Ad esempio, se abbiamo solo bisogno di recuperare i file del contratto nel marzo 2023, allora possiamo utilizzare i dati delle serie temporali per scegliere il pezzo di destinazione da decine di migliaia, e poi calcolare il vettore.
Timescale Vector Plug - In
Ricerca di somiglianza più veloce per milioni di vettori: supporto * * DiskANN * * algoritmo, * * HNSW * * algoritmo
-
-
- Timescale Vector ottimizza il tempo - domande di ricerca vettoriali basate: * * Utilizzare il tempo automatico - partizionamento basato e indicizzazione della super tabella del timescale per trovare efficacemente le embeddings più vicine, ricerca per intervallo di tempo o documento esistenza anno vettore di vincolo, e facilmente memorizzare e recuperare le risposte di grande modello di lingua (LLM) e la cronologia di chat. Time - Based Semantic Search consente anche di utilizzare * * Search Enhanced Generation (Retrieval Aumentated Generation, * * RAG * *) e Time - Based Context Retrieval per fornire agli utenti risposte LLM più utili.
-
-
-
- Stack di infrastruttura AI semplificato: * * Combinando * * Embedding vettoriali * *, * * dati relazionali * * e * * serie temporale * in un database PostgreSQL, il vettore timescale elimina la complessità operativa della gestione di più sistemi di database su larga scala.
-
-
-
- Semplifica l'elaborazione dei metadati e il filtraggio degli attributi multipli: * * Gli sviluppatori possono utilizzare tutti i tipi di dati PostgreSQL per memorizzare e filtrare i metadati e collegare i risultati della ricerca vettoriale con i dati relazionali per ottenere più contesto - risposte sensibili. Nelle versioni future, Timescale Vector ottimizzerà ulteriormente il ricco filtraggio multi-attributo per consentire una ricerca di somiglianza più veloce durante il filtraggio dei metadati.
-
Database vettoriale raccolto da LlamaIndex
-
- Opzioni Vector Store & supporto funzionalità * *
| Vector Store | Type | Metadata Filtering | Hybrid Search | Delete | Store Documents | Async |
|---|---|---|---|---|---|---|
| Apache Cassandra® | self-hosted / cloud | ✓ | ✓ | ✓ | ||
| Astra DB | cloud | ✓ | ✓ | ✓ | ||
| Azure Cognitive Search | cloud | ✓ | ✓ | ✓ | ||
| Azure CosmosDB MongoDB | cloud | ✓ | ✓ | |||
| ChatGPT Retrieval Plugin | aggregator | ✓ | ✓ | |||
| Chroma | self-hosted | ✓ | ✓ | ✓ | ||
| DashVector | cloud | ✓ | ✓ | ✓ | ✓ | |
| Deeplake | self-hosted / cloud | ✓ | ✓ | ✓ | ||
| DocArray | aggregator | ✓ | ✓ | ✓ | ||
| DynamoDB | cloud | ✓ | ||||
| Elasticsearch | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | ✓ |
| FAISS | in-memory | |||||
| txtai | in-memory | |||||
| Jaguar | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | |
| LanceDB | cloud | ✓ | ✓ | ✓ | ||
| Lantern | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | ✓ |
| Metal | cloud | ✓ | ✓ | ✓ | ||
| MongoDB Atlas | self-hosted / cloud | ✓ | ✓ | ✓ | ||
| MyScale | cloud | ✓ | ✓ | ✓ | ✓ | |
| Milvus / Zilliz | self-hosted / cloud | ✓ | ✓ | ✓ | ||
| Neo4jVector | self-hosted / cloud | ✓ | ✓ | |||
| OpenSearch | self-hosted / cloud | ✓ | ✓ | ✓ | ||
| Pinecone | cloud | ✓ | ✓ | ✓ | ✓ | |
| Postgres | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | ✓ |
| pgvecto.rs | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | |
| Qdrant | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | ✓ |
| Redis | self-hosted / cloud | ✓ | ✓ | ✓ | ||
| Simple | in-memory | ✓ | ✓ | |||
| SingleStore | self-hosted / cloud | ✓ | ✓ | ✓ | ||
| Supabase | self-hosted / cloud | ✓ | ✓ | ✓ | ||
| Tair | cloud | ✓ | ✓ | ✓ | ||
| TencentVectorDB | cloud | ✓ | ✓ | ✓ | ✓ | |
| Timescale | ✓ | ✓ | ✓ | ✓ | ||
| Typesense | self-hosted / cloud | ✓ | ✓ | ✓ | ||
| Weaviate | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ |
Database più supportati
| ector Store | Type | Metadata Filtering | Hybrid Search | Delete | Store Documents | Async | |
|---|---|---|---|---|---|---|---|
| DashVector | cloud | ✓ | ✓ | ✓ | ✓ | ||
| Elasticsearch | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | ✓ | 总觉得比较重 |
| Jaguar | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | ||
| Lantern | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | ✓ | |
| MyScale | cloud | ✓ | ✓ | ✓ | ✓ | ||
| Pinecone | cloud | ✓ | ✓ | ✓ | ✓ | ||
| Postgres | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | ✓ | |
| pgvecto.rs | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | ||
| Qdrant | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | ✓ | 创始人好像出走了 |
| TencentVectorDB | cloud | ✓ | ✓ | ✓ | ✓ | ||
| Weaviate | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ |
Elasticsearch:总觉得比较重
Postgress:先从最简单的开始吧。
Qdrant:创始人好像出走了。
Confronto dei database di LangChain
| 数据库名称 | 应用场景 |
|---|---|
| HNSWLib, Faiss, LanceDB, CloseVector | 如果你需要一个可以在你的Node.js应用程序中运行的内存数据库,无需其他服务器 |
| MemoryVectorStore, CloseVector | 如果你在寻找一个可以在类似浏览器的环境中内存中运行的东西 |
| HNSWLib, Faiss | 如果你来自Python,并且你在寻找类似于FAISS的东西 |
| Chroma | 如果你在寻找一个开源的、功能全面的向量数据库,可以在docker容器中本地运行 |
| Zep | 如果你在寻找一个开源的向量数据库,提供低延迟、本地嵌入文档支持,并且支持边缘上的应用 |
| Weaviate | 如果你在寻找一个开源的、生产就绪的向量数据库,可以在docker容器中本地运行或在云中托管 |
| Supabase vector store | 如果你已经在使用Supabase,看看Supabase向量存储,使用同一个Postgres数据库来存储你的嵌入 |
| Pinecone | 如果你在寻找一个生产就绪的向量存储,你不必担心自己托管 |
| SingleStore vector store | 如果你已经在使用SingleStore,或者你需要一个分布式、高性能的数据库,你可能会考虑SingleStore向量存储 |
| AnalyticDB vector store | 如果你在寻找一个在线MPP(大规模并行处理)数据仓库服务,你可能会考虑AnalyticDB向量存储 |
| MyScale | 如果你在寻找一个性价比高的向量数据库,允许使用SQL进行向量搜索 |
| CloseVector | 如果你在寻找一个可以从浏览器和服务器端加载的向量数据库,看看CloseVector。它是一个旨在跨平台的向量数据库 |
| ClickHouse | 如果你在寻找一个可扩展的、开源的列式数据库,对于分析查询有着出色的性能 |