ラガス州
クイックスタート
コンセプトは
| 概念 | 含义 |
|---|---|
| Question | |
| Contexts | Retrieved contexts:实际找到的Context |
| Answer | 最终生成的答案 |
| Ground truths | 参考答案 |
Dataset
from datasets import Dataset
data_samples = {
'question': ['When was the first super bowl?', 'Who won the most super bowls?'],
'answer': ['The first superbowl was held on January 15, 1967', 'The most super bowls have been won by The New England Patriots'],
'contexts' : [['The Super Bowl....season since 1966,','replacing the NFL...in February.'],
['The Green Bay Packers...Green Bay, Wisconsin.','The Packers compete...Football Conference']],
'ground_truth': ['The first superbowl was held on January 15, 1967', 'The New England Patriots have won the Super Bowl a record six times']
}
dataset = Dataset.from_dict(data_samples)
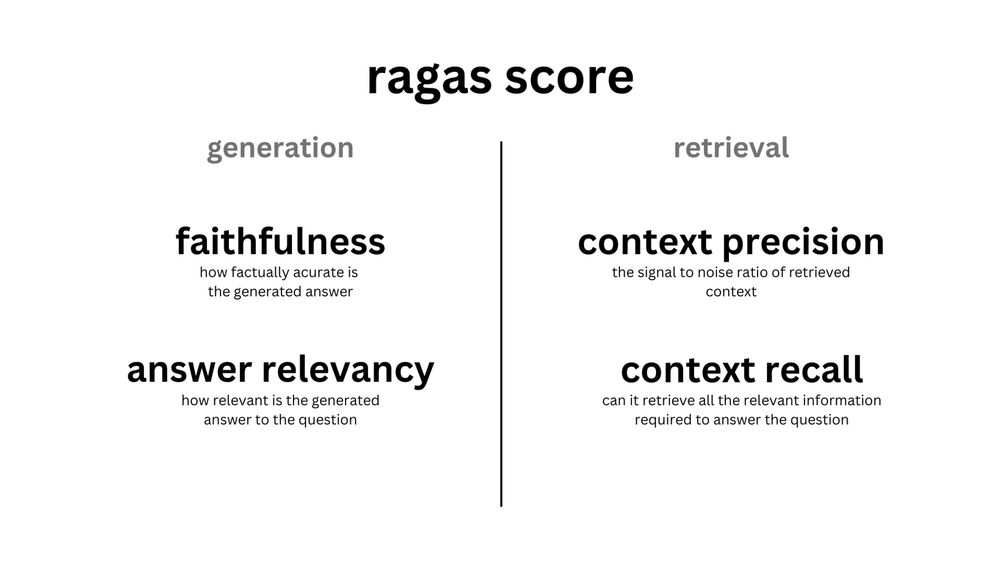
Metricとは
| Metric | |||
|---|---|---|---|
| Context Precision | Retrieval | Question | 是否跑题:检索结果 与 Quesion 是否相关 |
| Answer Relevance | Anwser | Question | 是否跑题:生成的答案 是否与 Question 相关 |
| Faithfulness | Anwser | Retrieval | 是否参考引用:生成的答案 是否忠诚于 检索结果 |
| Context Recall | Retrieval | 参考答案 Ground Truth | 检索的准确性: 检索结果 与 参考答案 是否相关 |
Promptとは
コンテキストの精度
Given question, answer and context verify if the context was useful in arriving at the given answer. Give verdict as "1" if useful and "0" if not with json output.
The output should be a well-formatted JSON instance that conforms to the JSON schema below.
……
Your actual task:
question: 法国的首都是什么?
context: 巴黎是法国的首都。
answer: 巴黎
verification:
Answer Relevancy
このプロンプトは理解できません。
Generate a question for the given answer and Identify if answer is noncommittal. Give noncommittal as 1 if the answer is noncommittal and 0 if the answer is committal. A noncommittal answer is one that is evasive, vague, or ambiguous. For example, "I don't know" or "I'm not sure" are noncommittal answers
……
Your actual task:
answer: 巴黎
context: 巴黎是法国的首都。
output:
Faithfulness
Create one or more statements from each sentence in the given answer.
……
Your actual task:
question: 法国的首都是什么?
answer: 巴黎
statements:
Your task is to judge the faithfulness of a series of statements based on a given context. For each statement you must return verdict as 1 if the statement can be verified based on the context or 0 if the statement can not be verified based on the context.
……
Your actual task:
context: 巴黎是法国的首都。
statements: ["\u6cd5\u56fd\u7684\u9996\u90fd\u662f\u5df4\u9ece\u3002"]
answer:
コンテキスト·リコール
Given a context, and an answer, analyze each sentence in the answer and classify if the sentence can be attributed to the given context or not. Use only "Yes" (1) or "No" (0) as a binary classification. Output json with reason.
……
Your actual task:
question: 法国的首都是什么?
context: 巴黎是法国的首都。
answer: 巴黎
classification:
データの生成
動機:ドキュメントから何百ものQA(質問-コンテキスト-回答)サンプルを手動で作成することは、時間と労力がかかります。LLMを使って自動生成する。
分成几类:simple, reasoning, conditioning, multi-context
これらのカテゴリーは **
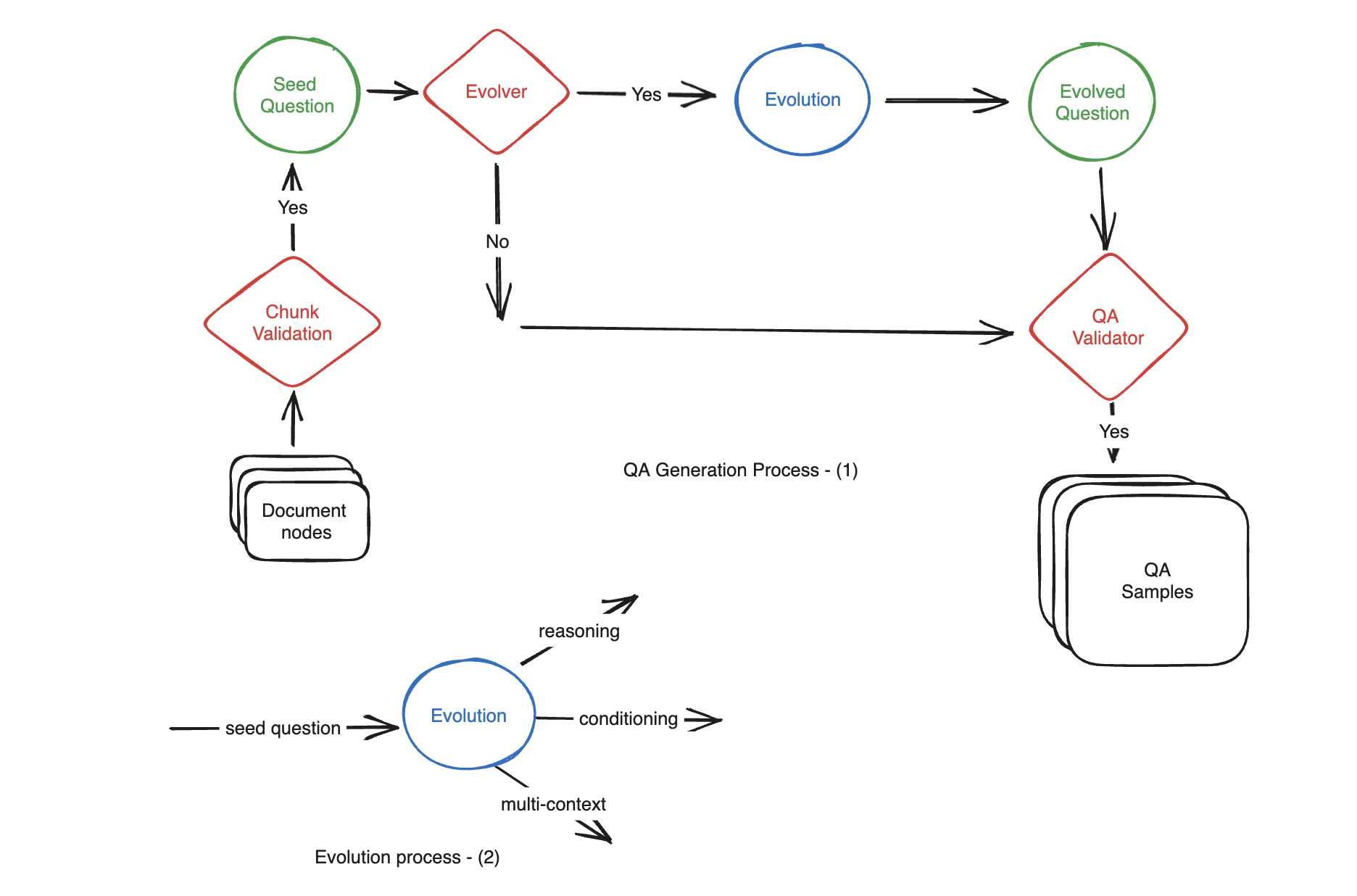
生成時に、これら3種類のスケールを指定します。
from ragas.testset.generator import TestsetGenerator
from ragas.testset.evolutions import simple, reasoning, multi_context
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
# documents = load your documents
# generator with openai models
generator_llm = ChatOpenAI(model="gpt-3.5-turbo-16k")
critic_llm = ChatOpenAI(model="gpt-4")
embeddings = OpenAIEmbeddings()
generator = TestsetGenerator.from_langchain(
generator_llm,
critic_llm,
embeddings
)
# Change resulting question type distribution
distributions = {
simple: 0.5,
multi_context: 0.4,
reasoning: 0.1
}
# use generator.generate_with_llamaindex_docs if you use llama-index as document loader
testset = generator.generate_with_langchain_docs(documents, 10, distributions)
testset.to_pandas()
データの読み込み
公式にLangChainを使用し、LangChainを使用し続けて、問題は容易ではない。
言語の自動適応
アセスメント
評価中に使用されたPromptを中国語に翻訳し、gpt-4-turbo-previewモデルを使用します。
“勧告に基づく提案は、ターゲット言語に自動的に適応されます。
The sit to
.cacha/ragasby to reuse later.
# 将Metric中的Prompt翻译成中文
from datasets import Dataset
# from langchain.chat_models import ChatOpenAI
from langchain_openai import ChatOpenAI, OpenAI
from ragas.metrics import (
answer_relevancy,
faithfulness,
context_recall,
context_precision,
answer_correctness,
answer_similarity,
)
from ragas import evaluate
from ragas import adapt
eval_model = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
# llm used for adaptation
openai_model = ChatOpenAI(model_name="gpt-4-turbo-preview")
# openai_model = OpenAI(model_name="gpt-4-0125-preview", temperature=0)
adapt(
metrics=[
answer_relevancy,
# faithfulness,
context_recall,
context_precision,
answer_correctness,
# answer_similarity,
],
language="Chinese",
llm=openai_model,
)
# Eval
dataset = Dataset.from_dict(
{
"question": ["法国的首都是什么?"],
"contexts": [["巴黎是法国的首都。"]],
"answer": ["巴黎"],
"ground_truths": [["巴黎"]],
}
)
print(dataset)
results = evaluate(dataset, llm=eval_model)
print(results)
生成されたキャッシュデータ
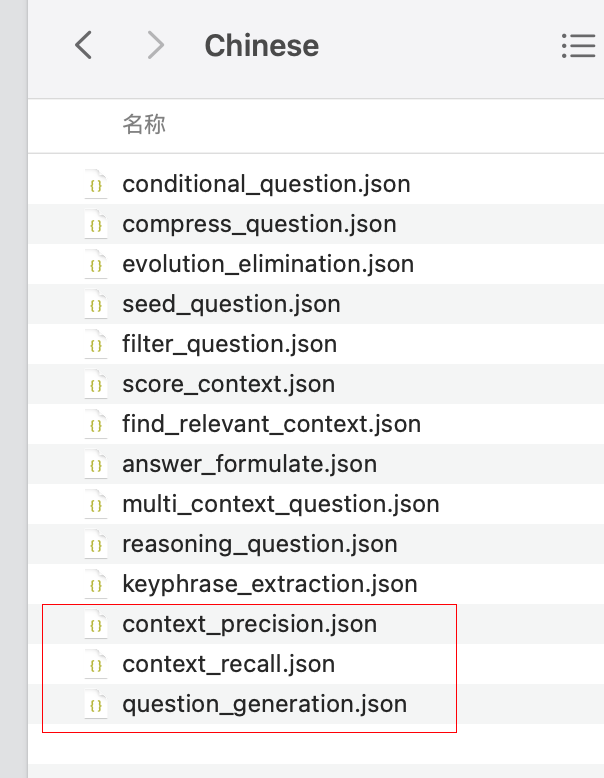
データの生成
from ragas.testset.generator import TestsetGenerator
from ragas.testset.evolutions import simple, reasoning, multi_context,conditional
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
# generator with openai models
generator_llm = ChatOpenAI(model="gpt-3.5-turbo-16k")
critic_llm = ChatOpenAI(model="gpt-4")
embeddings = OpenAIEmbeddings()
generator = TestsetGenerator.from_langchain(
generator_llm,
critic_llm,
embeddings
)
# adapt to language
language = "Chinese"
generator.adapt(language, evolutions=[simple, reasoning,conditional,multi_context])
generator.save(evolutions=[simple, reasoning, multi_context,conditional])
生成されたキャッシュデータ
dataset内のフィールド
- QUETION-
- Contexts:取得したコンテキスト
- Ground_Truth:答えを参照
- anwser anwser生成された解答
- Question: A set of questions.
- Contexts: Retrieved contexts corresponding to each question. This is a
list[list]since each question can retrieve multiple text chunks. - Answer: Generated answer corresponding to each question.
- Ground truths-Ground truths corresponding to each question. This is a `` which coronds to the ected answer for each question.
文脈を参照しないでください。
metrics=[
# 这几个都不需要原始的context
context_precision,
answer_relevancy,
faithfulness,
context_recall,
],
BGEの使用
from ragas.llama_index import evaluate
flag_model = HuggingFaceEmbeddings(model_name="BAAI/bge-small-en-v1.5")
query_engine2 = build_query_engine(flag_model)
result = evaluate(query_engine2, metrics, test_questions, test_answers)
統合LangSmith
環境変数の設定
export LANGCHAIN_TRACING_V2=true
export LANGCHAIN_ENDPOINT=https://api.smith.langchain.com
export LANGCHAIN_API_KEY=<your-api-key>
export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
トラッカーの作成
# langsmith
from langchain.callbacks.tracers import LangChainTracer
tracer = LangChainTracer(project_name="callback-experiments")
Evalueの使用
from datasets import load_dataset
from ragas.metrics import context_precision
from ragas import evaluate
dataset = load_dataset("explodinggradients/amnesty_qa","english")
evaluate(dataset["train"],metrics=[context_precision],callbacks=[tracer])
LaIndexの
官方文档有问题。